What is agent evaluation? How to test agents with tasks, simulations, and success criteria
AI agents plan across multiple steps, call external tools, update systems, and make decisions without human intervention. Unlike single-response models, agents execute sequences of actions that modify data and interact with external services over time. This multi-step execution enables complex workflows, but it also introduces failure patterns that are difficult to detect. An incorrect tool call, a flawed intermediate decision, or a database update based on wrong information can silently affect every step that follows.
Agent failures often remain invisible until they produce incorrect outcomes in production. Standard single-turn LLM evaluations test a single response to a single prompt and cannot determine whether an agent correctly completed a task across an entire workflow. Agent evaluation tests multi-step behavior directly, measures decision quality across tool calls, and verifies that the agent reached the intended outcome without introducing errors along the way.
This guide covers what agent evaluation involves, the core components every team needs to measure, practical methods for testing agents with tasks and simulations, and a structured workflow for implementing agent evaluation with Braintrust.
What is agent evaluation?
Agent evaluation tests multi-step, tool-using AI systems by examining both the final outcome and the sequence of decisions that produced it. End-to-end evaluation determines whether the agent achieved the intended goal for a given task. Step-level evaluation analyzes how the agent reached that outcome, including whether it selected the correct tool, passed valid parameters, interpreted tool outputs accurately, and transitioned to the appropriate next action.
Agent evaluation differs from standard model evaluation because it measures execution across an entire workflow rather than judging a single response. It evaluates tool selection, parameter accuracy, intermediate outputs, and decision transitions in addition to the final result. Evaluating the full workflow makes it possible to identify which specific action caused a failure instead of judging only whether the final output passed or failed.
Agent evaluation also needs to account for non-deterministic behavior. The same agent running the same task twice can take different paths and produce different results. Running multiple trials per task produces more stable pass rates and provides a clearer measure of how reliably the agent completes its objective.
Agent evals vs. LLM evals
LLM evals grade a model's response to a single prompt for qualities such as correctness, relevance, or tone. Agent evals assess how a full system performs across multiple turns, including the model, the tools it uses, the data it updates, and the environment it interacts with.
| Dimension | LLM evals | Agent evals |
|---|---|---|
| Scope | Grade a single response | Evaluate a full trajectory of decisions, tool calls, and state changes across many turns |
| What gets tested | The model alone | The model working together with its scaffold, tools, and environment |
| Grading | Output quality (correctness, relevance, tone) | Multi-dimensional scoring across task success, tool accuracy, efficiency, safety, and cost |
| Determinism | Mostly reproducible with temperature controls | Agents take different paths on repeated runs, requiring multiple trials per task for reliable scores |
How to design agent eval tasks
A task is a defined test case with fixed inputs and clear success criteria. Each run of that task is a trial, and running multiple trials helps account for the variation that agents can show across executions.
Well-designed agent evaluation tasks define success in measurable terms. The expected outcome might be a specific database update, a correct final answer, or a verified sequence of tool calls. If the success criteria are vague, scores become inconsistent and difficult to interpret, which makes it harder to diagnose failures or compare changes. Clear definitions at the task level make evaluation results reliable and actionable.
Stable tasks require controlled dependencies. Instead of calling live APIs or production databases, tasks should run against stubbed services or snapshot data from staging or production. When the underlying data changes between runs, evaluation results become unstable and difficult to reproduce. Using consistent test data keeps task outcomes comparable across experiments and releases.
Tasks are split into two levels depending on what needs to be measured.
- Single-step tasks work like unit tests for agents, isolating a specific decision to check whether the agent selected the correct tool, constructed valid parameters, or correctly interpreted a tool's output.
- End-to-end tasks test the full workflow from input to goal completion across all steps.
Both are necessary because a task can appear successful overall while still containing decision-level weaknesses that create risk at scale.
The most useful task scenarios come from real incidents, user-reported edge cases, and domain-specific workflows identified by domain experts. Building tasks from observed failures ensures that evaluation covers actual risk patterns, and expanding coverage over time improves reliability as the agent evolves.
How to run agent simulations
Deterministic tasks validate whether an agent meets defined requirements under controlled conditions, while simulations expose how it behaves under variation. A simulation recreates a realistic environment and runs the agent through scenarios that differ across attempts, which helps surface behaviors that do not appear in static, specification-driven tests.
LLM-driven user personas: A separate language model acts as a simulated user with defined goals, constraints, and interaction patterns. The agent interacts with this persona across multiple turns, which allows teams to test intent handling, clarification strategies, tool selection, and task completion under different user behaviors. By varying persona traits such as expertise level, ambiguity tolerance, or goal clarity, teams can measure how reliably the agent completes workflows across diverse scenarios.
Sandboxed environments: A sandboxed environment replicates production infrastructure within an isolated system, allowing the agent to execute full workflows without affecting live data. Databases, APIs, and interfaces run against controlled replicas or data snapshots, which ensures that each simulation starts from a known baseline. Resetting the environment between runs keeps conditions consistent while still allowing the agent's internal decisions to vary.
Fault injection: Fault injection deliberately introduces failures into tools and external systems to test how the agent responds under stress. Simulated timeouts, malformed responses, missing fields, or inconsistent data reveal whether the agent retries appropriately, handles errors safely, or enters unstable execution loops. Adversarial variations such as contradictory instructions or mid-task goal changes further test whether the agent maintains coherent planning and safe execution when conditions shift unexpectedly.
A practical starting point is to snapshot production data for realism, build sandboxed replicas for high-risk workflows, and prioritize adversarial scenarios that pose failure modes with the greatest impact if they occur in front of users.
How to define success criteria for agents
Success criteria determine whether an agent task passes or fails. Graders are the mechanisms that apply those criteria by evaluating either the final outcome or the full execution transcript. Most evaluation setups rely on three grader types, each suited to different kinds of tasks.
Code-based graders apply when correctness can be verified objectively. These include string matching, regex validation, binary checks, static analysis, or direct verification of a database update or API response. They run quickly, cost little, and produce fully reproducible results. However, they can fail when an agent produces a valid result in a format that does not exactly match the expected pattern.
Model-based graders use an LLM to evaluate open-ended or subjective outputs. Rubric-based scoring, natural language assertions, pairwise comparisons, and multi-judge consensus allow teams to assess reasoning quality, task completeness, or safety constraints when fixed rules are too rigid. These graders handle flexible outputs better than code-based checks, but they require calibration against human judgments to maintain stability and prevent drift.
Human graders provide the reference standard for evaluation quality. Subject-matter experts review transcripts, validate challenging edge cases, and assess agreement among reviewers to refine grading guidelines. Human review is slower and more expensive than automated methods, so teams typically use it for calibration, spot checks, and high-risk scenarios.
Scoring can be binary (where all graders must pass), weighted (where combined scores must exceed a defined threshold), or hybrid. When evaluation thresholds are directly linked to release gates, deployments are automatically blocked if regression scores fall below acceptable levels, turning evaluation results into enforceable shipping decisions.
Over time, capability evaluations that begin with low pass rates can evolve into regression tests once performance stabilizes. A scenario that initially measures whether an agent can complete a task at all eventually becomes part of a regression suite that protects against future degradation.
Common agent eval metrics
Agent evaluation requires metrics that measure both whether the agent achieved its goal and how it executed each step along the way.
| Metric | What it measures | Example |
|---|---|---|
| Task success rate | Whether the agent achieved its goal | Refund processed correctly in the target system |
| Tool selection accuracy | Whether the agent picked the right tool for each step | Called search_db instead of delete_record |
| Parameter correctness | Whether the tool arguments were valid and properly constructed | Passed instance_id instead of region_name |
| Step efficiency | Whether the agent avoided unnecessary or redundant actions | Completed the task in 4 steps instead of 12 |
| Safety and compliance | Whether the agent stayed within policy boundaries | No unauthorized data access or policy violations |
| Cost | Tokens and API calls consumed per task | $0.03 per successful resolution |
| Latency | Time from input to task completion | 8 seconds end-to-end |
| Recovery and resilience | Whether the agent handled tool failures and adapted | Retried with corrected parameters after an API error |
Building an agent eval harness
An agent eval harness is the infrastructure that runs evals end-to-end, from loading test cases through grading results and gating deployments. Each stage in the pipeline feeds directly into the next. The diagram below illustrates how datasets, task execution, scoring, aggregation, CI integration, and feedback loops connect into a continuous evaluation workflow.
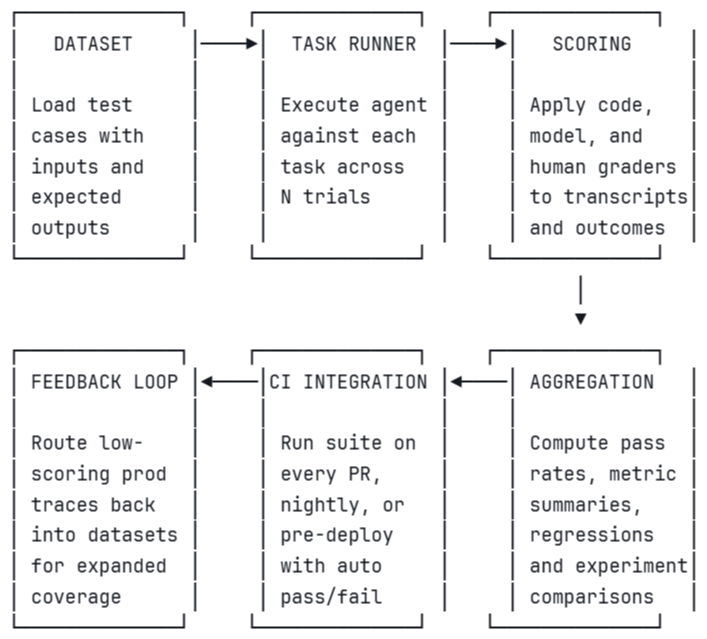
Evaluating agents with Braintrust
Braintrust provides an integrated workflow for evaluating agents from development through production without requiring separate tools. Braintrust structures every agent eval around three components:
- Data defines the task dataset with clear inputs and expected outcomes.
- Task runs the agent against each case across multiple trials.
- Scores apply grading functions that measure both overall task success and step-level behavior.
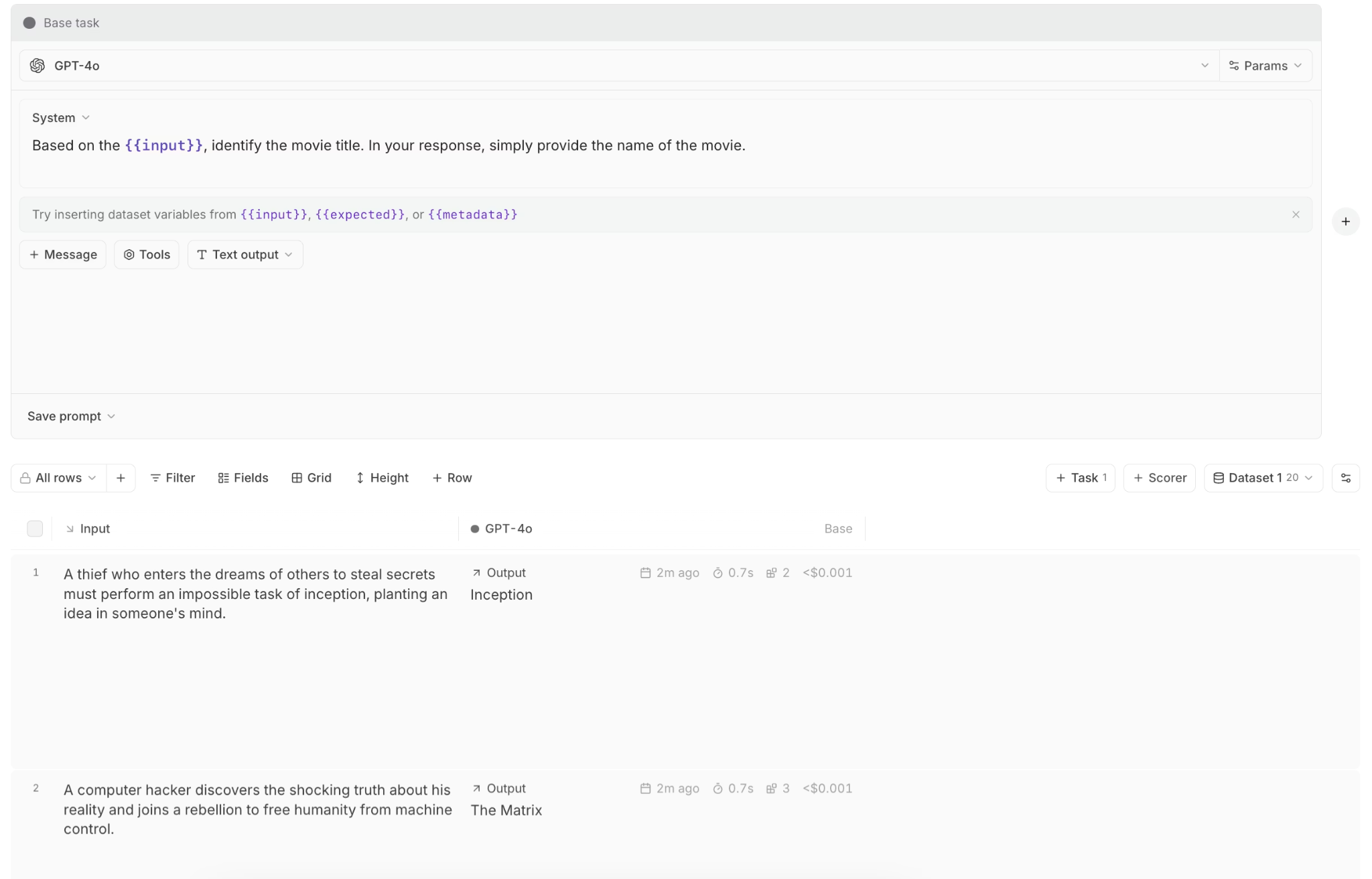
Offline evaluations allow teams to stub external dependencies, isolate high-risk agent actions, and build golden datasets from real scenarios. Code-based scorers verify objective outcomes such as database updates or structured outputs, while LLM-as-a-judge scorers evaluate open-ended reasoning. Braintrust's Playground enables rapid iteration on prompts and scoring logic before committing to a full evaluation run, shortening the feedback cycle and reducing setup overhead.
For step-level evaluation, Braintrust supports inline scorers that trigger conditionally based on agent behavior. If the agent makes a tool call, one scorer checks the accuracy of the tool selection. If the agent generates a direct response instead, a separate scorer checks for hallucination. The hooks argument in the eval's task function captures intermediate metadata like tool calls, making that data available to any downstream scorer.
// Capture intermediate tool calls for step-level scoring
export async function taskFunc(input, hooks) {
// Run the agent...
if (rsp.choices[0].finish_reason === "tool_calls") {
const toolCalls = rsp.choices[0].message.tool_calls;
hooks.metadata.tool_calls = toolCalls;
}
// Continue execution...
}
if (!res.choices[0].message.tool_calls?.length) {
// Start hallucination scoring in the background (fire-and-forget)
runHallucinationScore({
question: message,
answer: res.choices[0].message.content,
context: documents,
});
break;
}
Online evaluation brings scoring into production by evaluating sampled live traffic as users interact with the agent. Braintrust monitors hallucinations, tool accuracy, and task completion on real requests, and teams can incorporate user feedback, such as likes, dislikes, and comments, to surface issues that automated checks may miss. Adaptive sampling can begin with full coverage and gradually reduce the sample rate as the agent's reliability improves.
Tracing and monitoring dashboards provide full transparency into agent behavior across steps, including tool calls, intermediate outputs, and timing data. Score trends, regressions, and experiment comparisons appear in one place, so teams can identify quality degradation before it impacts users.
Loop, Braintrust's built-in evaluation assistant, uses natural language queries to analyze production traces, suggest evaluation criteria, generate test datasets, and recommend scoring improvements. Loop reduces the manual effort required to expand evaluation coverage and maintain regression suites.
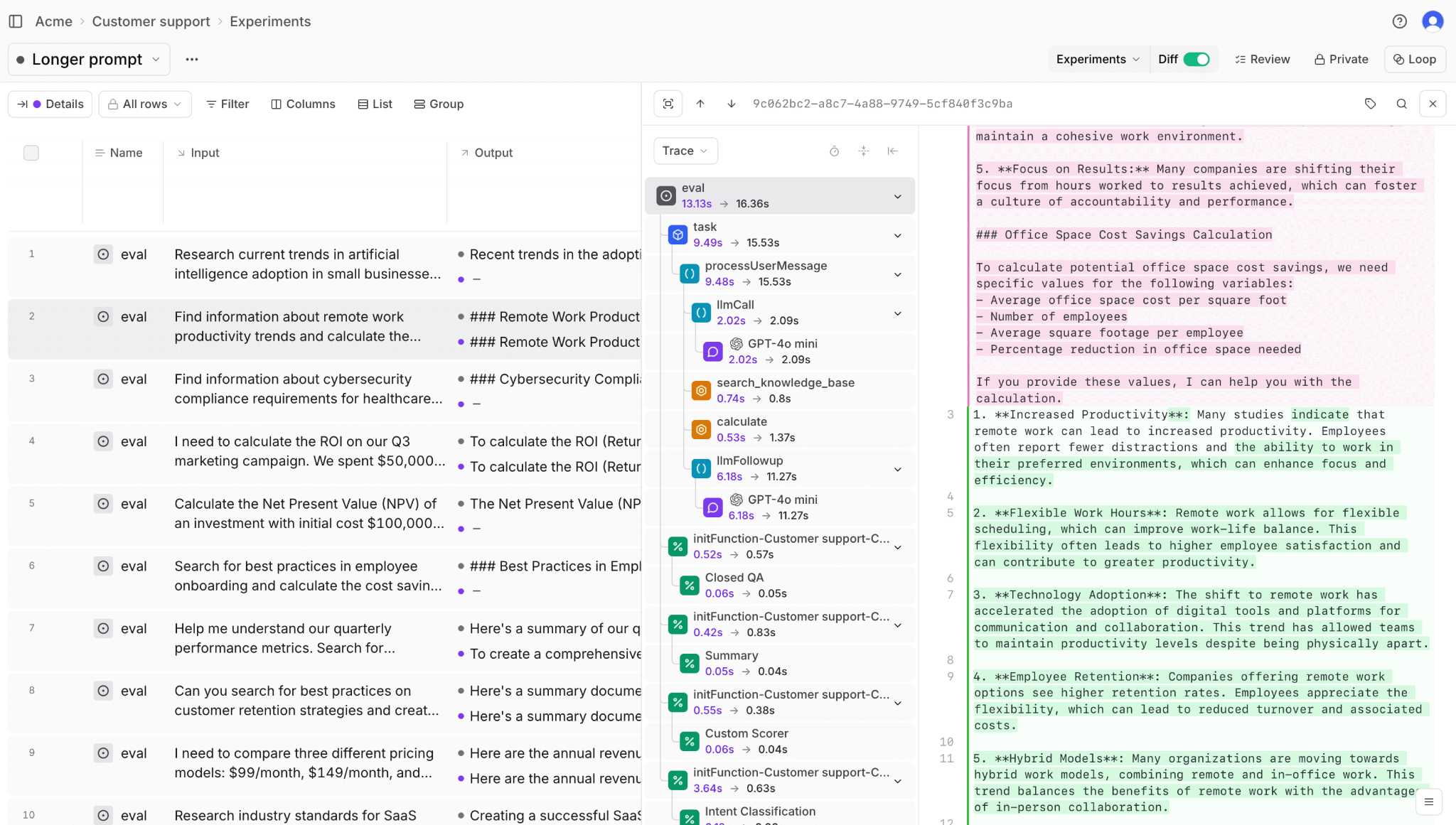
CI/CD integration through Braintrust's GitHub Action runs eval suites on every pull request and posts results directly as PR comments, showing which test cases improved, which regressed, and by how much. Teams can use these results to enforce quality gates at the code review stage, blocking merges when regression scores drop below the defined threshold.
Leading companies such as Notion, Stripe, Zapier, Vercel, Airtable, and Ramp use Braintrust to evaluate and monitor their agents with a unified workflow that spans development and production.
Ready to build agent evals that catch failures before production? Get started with Braintrust's free tier.
Conclusion
Agent evaluation keeps multi-step systems reliable as prompts change, tools evolve, and workflows grow more complex. When task success, tool accuracy, and execution behavior are measured consistently across trials and environments, failures become traceable to specific decisions instead of appearing as unpredictable outcomes in production.
Braintrust provides the infrastructure to run agent evaluation end to end, from task design and simulation through scoring, CI gating, and production monitoring in a single integrated workflow. This unified system keeps agent performance measurable, enforceable, and easier to maintain as capabilities expand. Start evaluating your agents with Braintrust.
Agent evaluation FAQs
What is an agent eval?
An agent eval is a structured test for a multi-step, tool-using AI system. It measures whether the agent achieved its intended goal, selected appropriate tools, provided valid parameters, and operated within defined safety and policy boundaries throughout the task's execution, rather than judging only the final response.
How do agent evals work?
Teams define tasks with clear inputs and measurable success criteria, run the agent across multiple trials to account for behavioral variation, and apply graders to evaluate both final outcomes and intermediate steps. Code-based graders verify objective results, LLM-as-a-judge scorers assess open-ended outputs, and human review calibrates automated scoring when needed. Results aggregate into pass rates and metric summaries that determine whether changes meet the release threshold.
What are agent evaluation metrics?
Common metrics include task success rate, tool selection accuracy, parameter correctness, step efficiency, cost per task, latency, safety and compliance adherence, and recovery from failures. The specific mix depends on the agent's responsibilities and which types of failure would create operational or user risk.
Which tools should I use for agent evaluation?
Braintrust provides a unified system designed specifically for agent evaluation by connecting dataset management, tracing, scoring, experiments, CI enforcement, and online monitoring into a single workflow, so teams can move from detecting a failure to validating a fix without switching systems. Braintrust's integrated approach turns agent evaluation from a collection of scripts into an enforceable release process that scales as agents become more complex.
How do I get started with agent evaluation?
Start by turning real failures or high-risk workflows into structured tasks with clear inputs and measurable success criteria. Run those tasks across multiple trials, score both task outcomes and step-level behavior, and establish a baseline pass rate before making further changes, creating a controlled starting point instead of relying on ad hoc testing.
Braintrust simplifies this setup by letting you create datasets, define scorers, trace executions, and enforce release gates within the same workflow. Instead of building custom scripts for each stage, you can stand up a working evaluation harness quickly and expand it over time as your agent grows in complexity and responsibility.