What is prompt evaluation? How to test prompts with metrics and judges
A prompt that works in manual testing can still fail when it reaches real users. Inputs in production often differ from those a team tested, and small wording changes that improve results in one case can degrade quality in another. Without a clear way to measure changes in output quality across inputs, degraded responses often remain hidden until users report them.
Prompt evaluation provides a measurable process for assessing prompt quality before and after deployment. It allows teams to test prompts with real data, use automated scoring, and compare versions directly, so changes are evaluated on evidence rather than assumptions. This guide explains how to evaluate prompts, define quality criteria, build evaluation datasets, score outputs, catch regressions before deployment, and monitor quality once prompts are live.
What is prompt evaluation
Prompt evaluation is the process of assessing how well a prompt meets defined quality criteria, using a consistent, repeatable method. Instead of relying on isolated examples or subjective judgment, teams evaluate prompts across a set of representative inputs and score the outputs based on what matters for the application.
Evaluation focuses on outcomes rather than on the wording of the prompt. A prompt may be well written but still produce incorrect, incomplete, or unsafe responses under certain conditions. Prompt evaluation makes these failures visible by testing prompts on real inputs and scoring outputs on dimensions such as correctness, relevance, safety, and task completion.
By running evaluations regularly, teams can objectively compare prompt versions, understand the impact of changes, and detect quality regressions before they reach users.
Prompt evaluation vs prompt engineering vs prompt management vs model evaluation
| Aspect | Prompt engineering | Prompt evaluation | Prompt management | Model evaluation |
|---|---|---|---|---|
| Focus | Designing and refining prompt wording and structure | Measuring how well a prompt performs against defined quality criteria | Managing prompt versions, deployment, and rollback across environments | Measuring a model's general capabilities independent of a specific product |
| Purpose | Improving prompt design | Determining whether a prompt meets quality requirements | Deciding which prompt version should run in production | Assessing a model's overall capability |
| Scope | Individual prompt changes and iterations | Specific prompts running on a specific model | Prompt templates and their lifecycle | Base models across standardized tasks |
| Inputs | Prompt text and examples | Prompt, model, parameters, and test inputs | Prompt versions and environments | Benchmark datasets like MMLU or HellaSwag |
| Outputs | Revised prompt drafts | Quality scores and regression signals | Promotion and rollback decisions | Benchmark scores and model ranking |
| Timing | During prompt design and iteration | Before deployment and during production monitoring | During release and operational workflows | During model selection and comparison |
What to measure in a prompt evaluation
Before writing test cases, teams need to define what good output means for their application. Not every quality dimension applies to every product, so the first step is selecting the dimensions that reflect real user expectations rather than measuring everything by default.
Correctness measures whether an output contains factually accurate information. Teams usually score correctness by comparing responses against verified reference answers or ground-truth data. Any application that answers factual questions, generates code, or produces summaries needs a reliable way to measure correctness.
Groundedness, also called faithfulness, checks whether an output's claims are supported by the context the model was given. An answer can be true in general yet fail to demonstrate groundedness if the provided documents do not support the claim. Retrieval-augmented systems and any application that cites sources should evaluate groundedness separately from correctness.
Relevance measures whether the response actually addresses the user's request. An output can be factually correct and well-grounded but still perform poorly if it answers a different question or drifts off topic.
Style and format adherence evaluates whether the output adheres to required structure and presentation rules, such as JSON schemas, length limits, or brand tone. These criteria are often difficult to enforce with rule-based checks, which makes them a strong fit for LLM-based scoring.
Safety covers issues such as toxic content, data leaks, prompt injection vulnerabilities, and off-brand statements. Safety evaluation should include adversarial test cases that deliberately attempt to bypass guardrails, rather than relying solely on normal user inputs.
Latency and cost are operational constraints rather than quality dimensions, but they still belong in release decisions. A prompt that improves accuracy slightly while significantly increasing token usage or response time may not be an overall improvement.
Most teams start by measuring two or three dimensions and expand over time as they learn which quality gaps have the greatest impact on users. Starting with a few dimensions keeps evaluation focused while allowing it to mature alongside the product.
How to build a prompt evaluation test suite
A prompt evaluation test suite is built from three core components. Golden datasets define the inputs being tested, rubrics define what good output means for each input, and edge cases stress-test the prompt beyond normal usage.
Golden datasets
A golden dataset is a curated set of inputs paired with expected outputs or evaluation criteria that represent real-world usage. The most valuable datasets come from production logs, since real user queries capture phrasing, ambiguity, and intent that synthetic data often misses. Teams usually supplement production data with manually written examples for known failure modes and synthetic inputs for rare or extreme cases.
Starting with 20 to 50 carefully chosen examples is enough to catch major regressions. Each test case should include the input, a reference answer or evaluation target, and basic metadata such as category or difficulty. As evaluation practices mature, teams expand the dataset by flagging interesting production traces and adding them to the golden set.
Rubrics
A rubric defines the criteria that a scorer, whether human or automated, uses to judge an output. Effective rubrics clearly describe what each score level represents. For example, a correctness rubric might define a score of 0 as factually incorrect, 1 as correct but incomplete, and 2 as correct and concise. Without this level of specificity, different scorers interpret the same criteria differently, which leads to inconsistent results.
Rubrics should be versioned alongside prompts. When a rubric changes, earlier scores are no longer directly comparable, so teams need to know which rubric version was used to produce each evaluation result.
Edge cases and adversarial inputs
Standard test cases confirm that a prompt performs as expected under normal conditions. Edge cases and adversarial inputs test how the prompt behaves outside those conditions. Edge cases include ambiguous queries, empty inputs, extremely long inputs, or requests in unexpected languages. Adversarial inputs include prompt-injection attempts, role-breaking instructions, and inputs designed to extract the system prompt.
Together, these components ensure that prompt evaluations reflect real user behavior rather than idealized scenarios.
How LLM-as-a-judge scoring works for prompt evaluation
Evaluating thousands of prompt outputs manually is time-consuming, and traditional string-matching metrics such as BLEU or ROUGE fail to capture whether an output is actually correct in meaning. A response can provide the correct answer in different wording and still score poorly on BLEU and ROUGE metrics. LLM-as-a-judge scoring addresses this limitation by evaluating outputs based on meaning and intent rather than surface text, while operating at automated speed.
The scoring process
An LLM judge is a capable model (typically GPT or Claude) that evaluates outputs using the original user input, defined evaluation criteria, and optionally a reference answer. The judge returns a structured result that includes a score and an explanation of how that score was determined. Teams generally use one of three formats for judge outputs.
- Single-answer grading assigns a score using a fixed rubric.
- Pairwise comparison evaluates two outputs for the same input and selects the better one.
- Pass/fail classification checks whether an output meets a defined quality threshold.
Writing effective judge prompts
Because the judge follows instructions just like any other model, the quality of its scoring depends heavily on the clarity of its prompt. Broad instructions, such as "rate the quality of this response," lead to inconsistent results because the judge lacks a shared definition of quality. An effective judge prompt clearly defines the evaluation criteria, includes a concrete scoring rubric with examples, and requires the judge to justify their final score.
Example judge setup
Consider a customer support summarizer where the prompt generates ticket summaries from conversation transcripts. The judge prompt would instruct the evaluator to assess the summary on two dimensions, completeness and accuracy, with a 0-to-2 rubric for each. A score of 0 for completeness indicates the summary missed major points from the conversation. A score of 1 means it captured most points but omitted secondary details. A score of 2 indicates it captured all relevant points concisely. The judge returns a JSON object containing a reason field and separate scores for each dimension.
Calibrating judges and managing bias
Judge scores are useful only when they align with human judgment. Calibration typically involves having humans score 100 to 200 examples, running the same examples through the judge, and measuring agreement using metrics like Cohen's Kappa or Pearson correlation. Poor alignment indicates the need to refine the judge prompt, adjust the rubric, or add clearer examples.
LLM judges also show predictable biases.
- Position bias favors the first option in comparisons and is reduced by randomizing order.
- Verbosity bias rewards longer responses unless the rubric penalizes unnecessary length.
- Self-preference bias appears when a model judges its own outputs, which is why teams often use a different model family as the judge.
Score variability across runs can be reduced by setting the judge temperature to 0 and, when needed, averaging results across multiple evaluations.
Prompt evaluation metrics that drive release decisions
Individual test case scores are useful, but release decisions require aggregated metrics that summarize performance across the full test suite. The right metric depends on how the team plans to use the results and how much detail the decision requires, whether that is a strict quality gate or a more nuanced comparison between versions.
| Metric type | How it works | Best for | Limitation |
|---|---|---|---|
| Pass or fail | Applies a binary threshold to each test case, such as factuality above 0.8, counting as a pass | Clear CI gating and safety checks | Loses detail between passing scores |
| Scalar (0-1) | Scores outputs on a continuous scale | Trend analysis and regression detection | Harder to define strict release thresholds |
| Mean score | Averages scalar scores across the full test suite | High-level quality snapshot | Can hide severe failures in a small number of cases |
| Pass rate | Percentage of test cases that meet the threshold | Quick assessment of release readiness | Does not show how badly failing cases perform |
| P5 or P10 percentile | Score at the 5th or 10th percentile of the distribution | Catching worst-case outputs | Less intuitive for non-technical stakeholders |
| Pairwise win rate | Percentage of test cases where version B outperforms version A | A/B comparisons and stakeholder communication | Requires pairwise judge configuration |
Because LLM judges introduce some variability, small score differences between prompt versions can reflect noise rather than real improvement. Running 3 to 5 trials per test case and computing confidence intervals helps distinguish meaningful gains from random variation. Statements like "version B won on 64% of test cases" are also easier for stakeholders to understand than small changes in average scores.
Quality metrics should not be evaluated in isolation. A prompt that improves relevance by 5% while doubling token usage and response time may not be a net improvement. Release decisions work best when quality thresholds are evaluated alongside cost and latency budgets, so prompt changes meet both performance and operational requirements before reaching production.
Prompt regression testing and CI/CD integration
Prompt evaluation delivers the most value when it runs automatically on every change, just as unit tests prevent code regressions from reaching production. Automating evaluation turns prompt updates into a controlled release process rather than a manual review step.
Setting thresholds and release criteria
Regression testing begins with clearly defined thresholds. Teams set minimum quality thresholds for each metric, such as factuality at 0.85 or higher, relevance at 0.90 or higher, and safety at a 100% pass rate. They also define regression tolerance, meaning no metric can fall below the current production baseline by more than a set percentage.
Documenting these release criteria in a configuration file ensures that the same standards apply across local testing, CI pipelines, and production checks. This removes ambiguity around what qualifies as a safe prompt change and makes quality expectations explicit.
The CI/CD workflow
The automation follows a predictable sequence that starts when a developer opens a pull request modifying a prompt, model configuration, or retrieval logic. The CI pipeline then runs the evaluation suite, executes every golden dataset case against the updated prompt, and sends the resulting outputs to the judges for scoring.
Results are compared with the production baseline and summarized directly in the pull request. The report shows pass/fail status, score deltas, and any regressed test cases. If a release criterion is not met, the merge is blocked until the regression is fixed or the threshold is updated with a clear justification.
Monitoring drift after deployment
Evaluation continues after deployment because production conditions change over time. User behavior evolves, model providers introduce updates, and input distributions shift in ways that offline test suites cannot fully anticipate. Online evaluation addresses this by scoring a sample of live production outputs using the same scorers applied during testing.
Teams track the judgment scores on dashboards and configure alerts when metrics fall below defined thresholds. When monitoring detects a quality drop, teams review the failing cases and add representative examples to the golden dataset. Feeding production failures back into testing keeps the evaluation process aligned with real usage as the product evolves.
Why Braintrust is the best choice for prompt evaluation
Building golden datasets, running judge scoring, enforcing CI gates, and monitoring production quality require infrastructure that most teams do not want to assemble or maintain themselves. Braintrust covers the full prompt evaluation lifecycle, so teams can focus on improving prompt quality instead of maintaining evaluation systems.
Build golden datasets from production traces
Braintrust logs every production trace and lets teams add any trace to a dataset with a single click. This ensures that golden datasets are built from real user behavior rather than assumptions or synthetic examples.
As monitoring surfaces new failure patterns, teams can capture those and add them directly into focused test sets, keeping evaluations aligned with how the system is actually used.
Score with built-in and custom scorers
Braintrust's AutoEvals library includes built-in LLM-as-a-judge scorers for factuality, relevance, similarity, and safety. For domain-specific needs, teams can define custom scorers as prompts, Python or TypeScript functions, or HTTP endpoints. Both code-based checks and judge-based scoring run in the same pipeline, which lets teams evaluate structured requirements and subjective quality in a single evaluation run.
Compare experiments side by side
Every evaluation run in Braintrust creates a versioned experiment with full git metadata. Teams can compare prompt versions using score breakdowns, per-case regression detection, and output diffs that show exactly what changed. Braintrust's playgrounds extend this comparison to interactive workflows, allowing product managers and engineers to test prompt variants, swap models, and adjust parameters on real data without writing code.
Automate quality gates in CI/CD
Braintrust's native GitHub Action automatically evaluates every pull request and posts results directly into the review workflow. Because the integration is native, teams do not need to write custom scripts or maintain separate CI logic to enforce prompt quality. When a prompt change fails to meet defined thresholds, the merge is blocked, ensuring that only verified improvements reach production.
Monitor production quality with online evaluation
After deployment, Braintrust applies the same scoring rules to live production logs at configurable sampling rates. Dashboards track quality metrics over time, and alerts fire when scores drop below thresholds.
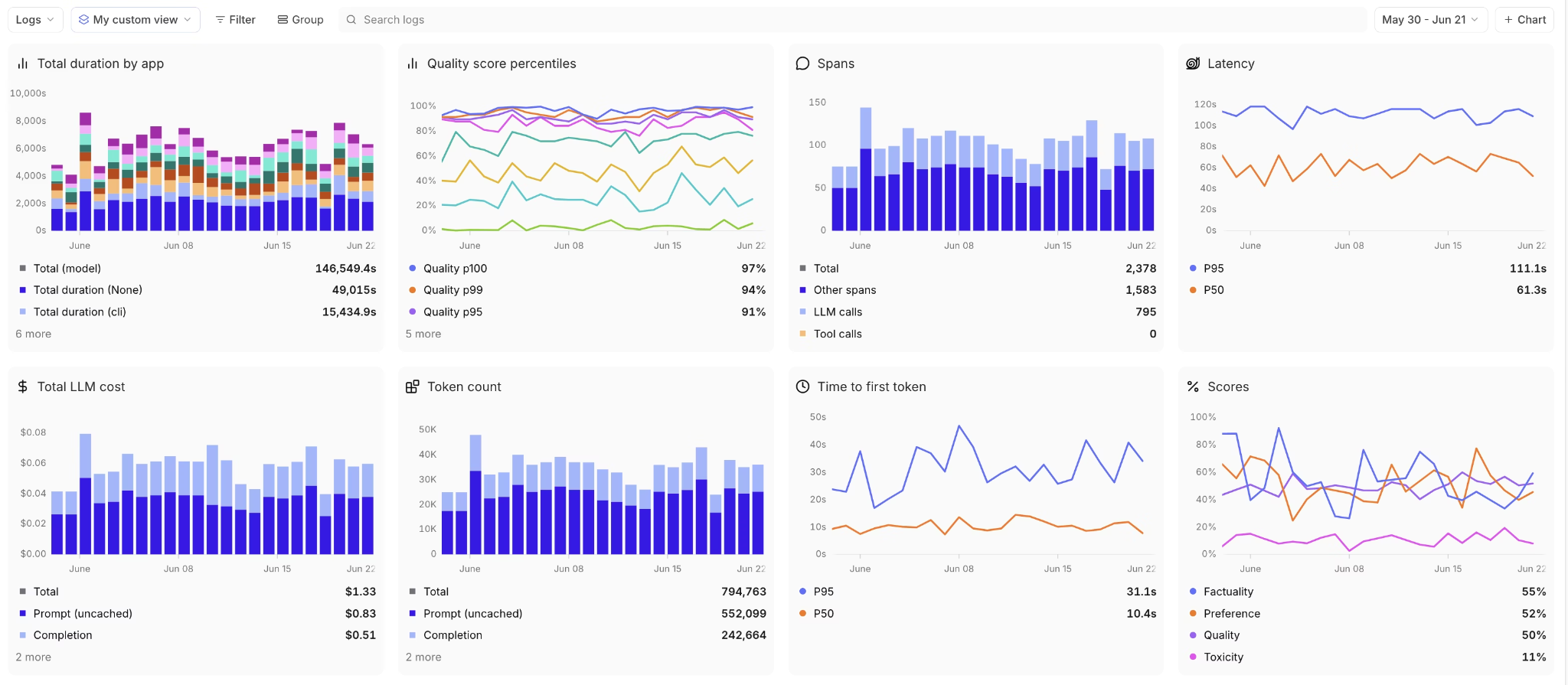
Because offline evaluation and online evaluation use the same scorer definitions, failures detected in production feed directly back into evaluation datasets, closing the loop between testing and real-world behavior.
Accelerate setup with Loop
Loop, Braintrust's built-in AI agent, reduces the time required to set up prompt evaluation by generating evaluation datasets, creating custom scorers, and suggesting prompt improvements based on real production data. With automated dataset generation and scorer creation, teams can achieve meaningful evaluation coverage faster without manual trial-and-error.
Production teams at organizations like Notion, Stripe, Vercel, Zapier, Instacart, and Dropbox rely on Braintrust to evaluate prompts before they reach users and to monitor quality after deployment.
Ready to set up your first prompt evaluation pipeline? Get started with Braintrust for free with 1 GB of processed data and 10,000 scores included.
Conclusion
As LLM features move from experimentation into production systems, prompt quality can no longer depend on intuition or informal testing. Prompt evaluation introduces structure and accountability by turning prompt changes into measurable decisions rather than subjective judgments. Organizations that treat prompts as production assets iterate faster and ship more reliable AI features.
Braintrust supports end-to-end prompt evaluation by providing the infrastructure needed to evaluate, compare, and monitor prompts within a single, connected workflow. Start evaluating prompts with Braintrust for free.
FAQs
What is prompt evaluation in AI?
Prompt evaluation is the practice of systematically assessing a prompt's performance by running it against structured test data and measuring quality dimensions such as correctness, relevance, and safety using automated scorers and LLM judges. The purpose is to make prompt changes measurable and comparable over time rather than relying on manual review or informal testing.
How is prompt evaluation different from prompt engineering?
Prompt engineering focuses on writing and refining prompts to improve outputs, while prompt evaluation determines whether those changes actually improve performance across a representative set of test cases. Engineers introduce modifications to shape model behavior, and evaluation measures the impact of those modifications against clearly defined quality criteria, ensuring that improvements are confirmed with data rather than assumed.
What is an LLM-as-a-judge?
LLM-as-a-judge is a method in which a capable language model evaluates another model's outputs against defined criteria. The judge receives the original input, the generated output, and a scoring rubric, then returns structured scores with reasoning. By assessing context and adherence to defined standards, the LLM-as-a-judge method helps teams to evaluate large volumes of outputs automatically while maintaining semantic quality checks.
Which is the best tool for prompt evaluation?
Braintrust is the best tool for teams building production LLM applications that need end-to-end prompt evaluation. Braintrust supports golden datasets built from production traces, built-in and custom LLM-as-a-judge scorers, side-by-side experiment tracking, native GitHub Actions for CI gating, and online production scoring in a single platform. Combining these capabilities together enables teams to evaluate, compare, release, and monitor prompt changes without maintaining separate tools for each stage.
How do I get started with prompt evaluation?
Start by identifying two or three quality dimensions that matter most for your application, such as correctness or relevance. Build a small golden dataset of 20 to 50 real user cases, define clear scoring criteria, and run an initial evaluation to establish a baseline. From there, introduce thresholds and integrate evaluation into your release process. Braintrust supports teams to set up datasets, scorers, experiments, CI gates, and production monitoring from the first evaluation, enabling a transition from manual testing to structured release workflows without custom infrastructure.