Brainstore: the purpose-built database for the AI engineering era
AI engineering has completely changed how we build software. Organizations are processing more tokens than ever, running agent-based systems with thousands of intermediate steps, and collecting massive amounts of structured and unstructured data. But traditional observability tools just aren’t keeping up.
That’s why we built Brainstore, a database built from the ground up for high-scale AI workloads. It’s 80x faster on real-world benchmarks, with median query times under one second, even across terabytes of data. That means AI teams can debug, gain insights, and iterate on products faster.
The breakpoint for classic observability
Observability tools built for microservices or web applications often struggle when it comes to AI data. Here’s why:
Huge data volumes
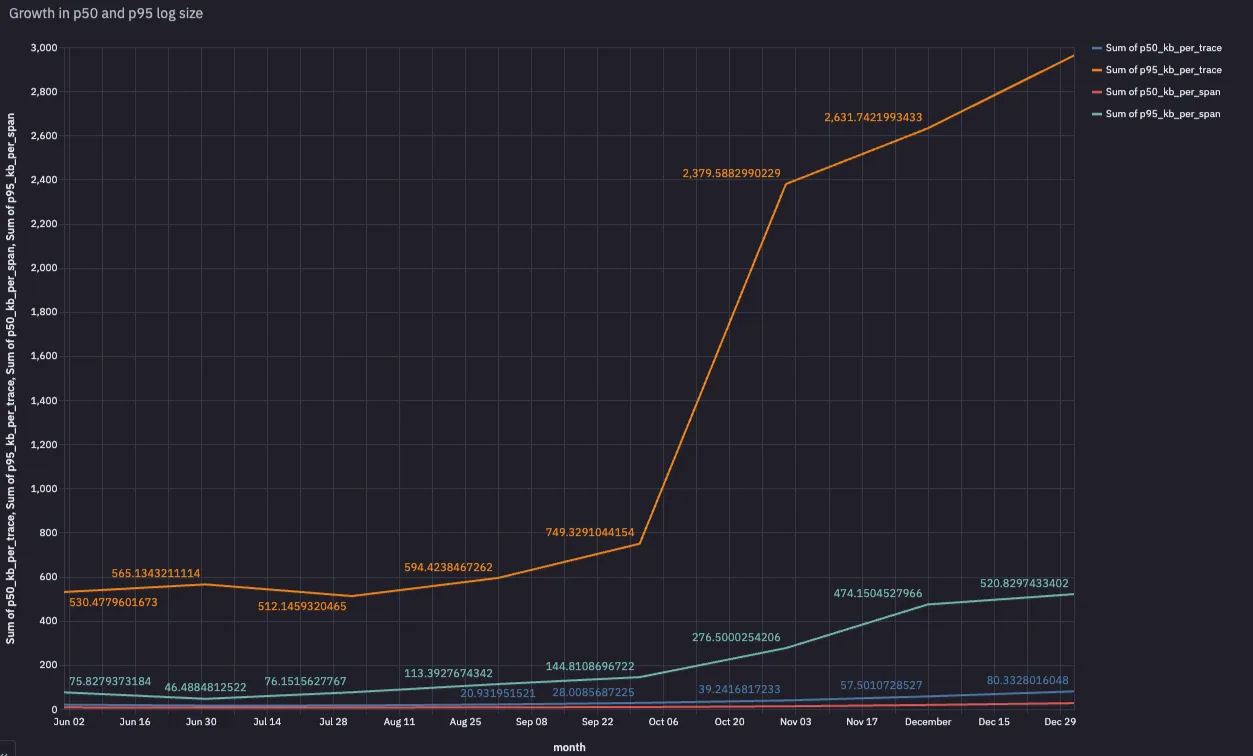
AI workloads generate an overwhelming amount of data, and we've seen p95 log size soar from 500KB to nearly 3MB over the course of a few months, as shown in the chart below. Traces can easily reach several megabytes, and individual spans often exceed 1MB as teams push token limits and build more complex agents (1 MB is roughly 260,000 tokens). That’s orders of magnitude more than traditional observability workloads were designed to handle.
Complex queries (full-text search)
AI workflows often require advanced, flexible queries, like finding recent prompts containing a specific phrase such as "over the rainbow." Another query might be filtering by dynamic application-defined fields (like output.steps[1] = 'router') that don’t fit into a well-defined schema. With traditional tools, these more sophisticated searches either run too slowly or fail altogether, making it difficult to get the insights AI teams need.
Security and privacy constraints
AI logs often contain proprietary data, and sometimes even PII/PHI, which means companies need to keep them in-house. That makes self-hosting a must, but deploying, scaling, and managing these systems is a huge challenge. The few self-hosted search/warehouse solutions out there are complex to operate, especially for teams that want to focus on AI engineering, not database maintenance.
Introducing Brainstore
This is a widely felt problem in the industry, as we’ve heard from many of our customers. To date, most approaches have tried to push traditional analytic databases into services, but they’re just not built for these workloads and are many times slower than what is needed. Instead of working around these limitations, we decided to do it right and build our own database. At a glance, Brainstore is:
- A single Rust binary that’s trivial to set up. Just point it to an object storage (e.g. S3) bucket (data), Postgres (metadata), and Redis (distributed locks). It re-uses your existing Postgres and Redis and doesn’t require you to manage anything new.
- Stateless, elastic scaling. No local disk state. Scale down to zero or up to hundreds of containers. Separate read-optimized nodes from write-optimized nodes.
- Highly optimized full-text search. We utilize an inverted index and columnstore designed specifically for object storage, handling real-time search in under 50ms (hot) and under 500ms (cold).
- Incredible write throughput and low-latency commits. A single thread can write 40 million 50kb documents per day. Data is visible immediately after flush with strong consistency thanks to our write-ahead log.
Benchmarks
We're incredibly happy with the results. To keep ourselves honest, we benchmarked Brainstore against a popular open-source data warehouse solution (”Popular data warehouse") and another LLM observability provider that uses that same warehouse. As you can see, Brainstore outperforms them significantly:
| Brainstore | Popular data warehouse* | Braintrust competitor (uses this warehouse) | |
|---|---|---|---|
| Document count | 3,925,153 × 25 kb | 3,925,153 × 25 kb | 3,925,153 × 25 kb |
| Span load time (UI) | 549 ms | 679 ms 1.2× slower | 1,160 ms 2.1× slower |
| Full text search (example query: “out of memory”) | 240 ms | 78,963 ms 329× slower | 20,789 ms 86.6× slower |
| Write latency (flush to server) (100 x 100 kb docs) | 1,780 ms | 331 ms** 0.19× | 4,176 ms 2.3× slower |
| Write latency (visible for reads) | 1,780 ms*** | 2,678 ms 1.5× slower | 10,412 ms 5.9× slower |
*These benchmarks were measured in March 2025. We published new benchmarks in December 2025.
**Both Brainstore and the data warehouse are deployed on identical hardware with NVME disks (c7gd.8xlarge on AWS). Brainstore caches locally and persists data to object storage, while the data warehouse just stores data locally, but we wanted to give them an equal playing field for read performance.
***This flush latency is low because the data warehouse supports asynchronous inserts and is only writing to NVME. However, it takes an additional 2.3 seconds for the data to be visible.
****Writes in Brainstore are strongly consistent and visible immediately because it directly reads and merges the write-ahead-log. The data warehouse used by Competitor is eventually consistent.
Key takeaways
- Brainstore is optimized specifically to be good at full-text search. Traditional data warehouses often rely on bloom filters or partitioned inverted indices to eliminate (or “skip”) batches of rows that do not contain terms. This is fine for slicing/dicing 10% of a dataset, but agonizingly slow for targeted text searches.
- Brainstore commits as soon as it writes to the write-ahead log. Write ahead logs are a simple object storage write, so are both low latency and scale very well. This also makes Brainstore real-time and strongly consistent.
- Object storage is incredibly cheap, so Brainstore is much less expensive to run than a traditional data warehouse.
Architecture
To achieve lightning-fast reads/writes at a massive scale, Brainstore’s architecture has three key principles, each inspired by real pain from trying to run Braintrust on a traditional data warehouse.
- All data lives on object storage. It’s infinitely scalable, resilient, and far simpler to operate than local disks. Popular commercial solutions partially use object storage, but still rely on persistent disks for metadata, statistics, and consensus, making them a pain to run yourself.
- Each customer’s data lives in its own distinct partition. In contrast, building on top of a data warehouse requires storing everyone’s data in one massive table, which slows down queries as the table grows.
- First-class support for semi-structured data. Data warehouses often “shred” JSON into columns, which works fine for relatively shallow, static JSON schemas but falls apart as you add more fields.
Under the hood, Brainstore leverages:
- Tantivy: a popular open-source library that has a built-in inverted index and columnstore. It’s extensible and well-suited for object storage, and supports semi-structured data efficiently.
- A custom write-ahead log (WAL) implementation that is designed for efficient real-time writes and reads on object storage. As soon as a WAL entry is written, reads can access it (alongside the indexed data), making Brainstore strongly consistent. We compact the write-ahead log into a highly optimized Tantivy index in the background.
- A lot of object-storage-specific optimizations to make cold starts and the common query patterns we serve extremely fast. For example, we make sure to store all of the spans of a trace within the same physical index.
We'll follow up with a technical deep dive of Brainstore in a future blog post. I also want to say thank you to friends from Turbopuffer, Neon, and Warpstream who are each building object-storage native database systems and helped us work out the design.
Why is it so much faster?
Braintrust is built for observability. Most solutions today have much broader mandates, and thus have to support features that are not needed for LLM development, from joins to schema migrations to ANSI SQL compatibility. This makes them complex and slow. Brainstore zeroes in on one goal: lightning-fast search and analytics for AI-shaped logs in object storage. By specializing, we cut out the bloat and optimize for exactly what AI engineers need.
Having experienced systems engineers also helps. I’ve worked on databases for 15+ years, from Microsoft Cosmos to SingleStore to Impira. Manu, our lead engineer, cut his teeth at BigQuery, Dropbox’s storage team, and Nuro’s infra group. Austin, a physics PhD dropout, was one of the first engineers at Impira, where he optimized models to run on JIT-compiled bytecode and worked on incremental query processing. Deeks (Mike), previously a Braintrust user at Instacart, knows firsthand the pain of running cumbersome databases and has shaped Brainstore’s operational experience to be exactly what he wished he had as a user.
Customer testimonials
Brainstore was inspired by some of our largest customers' evolving needs. After sitting down with them and watching how they search through logs, we knew exactly what to build. We're proud that after putting our heads down and shipping Brainstore, it's already making a big difference:
Brainstore opens a whole new world for working with LLMs. My team spends up to two hours a day looking at data. Not only do we get to see logs in crisp real-time, but we can also search through and understand them way faster.
– Vitor Balocco, Staff Applied AI Engineer @ Zapier
Brainstore has completely changed how our team interacts with logs. We've been able to discover insights by running searches in seconds that would previously take hours.
– Sarah Sachs, Engineering Lead, AI Modeling @ Notion
Braintrust customers often have complex security requirements, so we built Brainstore to be simple to run in your own infrastructure:
I was able to get Brainstore up and running in less than a day in my own AWS account. The performance difference is insane.
– Erik Munson, Founding Engineer @ Day.ai
Rollout and next steps
Brainstore is already available for our SaaS users. To turn it on, navigate to Feature flags in your organization settings, and toggle the switch. We'll make this the default soon.

If you are self-hosting and want to try it out, reach out, and we'll help you get set up.
Looking ahead
This is just the beginning of what we plan to do with Brainstore. Among other things, we're working on:
- Using Brainstore to make more parts of Braintrust's UI insanely fast.
- Providing support for more complex queries.
- Integrating seamlessly with enterprise data lake houses.
Last but not least, if building a specialized log processing database for AI engineering (in Rust!) sounds like your idea of fun, we're hiring.