Quick comparison of the best AI observability platforms for LLMs:
- Best overall (improvement loop): Braintrust
- Best open source: Langfuse
- Best for runtime guardrails: Galileo AI
- Best for ML + compliance: Fiddler
The question has changed. A year ago, teams building with LLMs asked "Is my AI working?" Now they're asking "Is my AI working well?"
When you're running a chatbot that handles 50,000 conversations a day, "it returned a response" isn't good enough. You need to know which responses helped users, which ones hallucinated, and whether that prompt change you shipped on Tuesday made things better or worse. Traditional monitoring tools track metrics like uptime and latency, but they don't review and score live answers from AI agents.
This is where AI observability comes in. The teams winning aren't just shipping AI features; they're building feedback loops that make those features better every week. The right AI observability platform is the difference between flying blind and having a system that improves itself.
What is AI observability?
AI observability monitors the traces and logs of your AI systems to tell you how they are behaving in production. Contrary to traditional software observability, AI observability goes beyond uptime monitoring to answer harder questions: Was this output good? Why did it fail? How do I prevent it from failing again?
The line between "logging tool" and "observability platform" comes down to what happens after you capture data. Basic logging stores your prompts and responses. Maybe you get a dashboard showing request volume and error rates. That's useful for the first week, but it stops being useful when you have 100,000 logs and no way to know how your AI systems are performing.
A modern AI observability platform goes beyond passive monitoring by tightly integrating debugging, evaluation, and remediation into the development lifecycle. Production logs are correlated with traces and model inputs, which feed directly into automated evaluations running in CI/CD. When regressions or failures are detected, those cases are automatically captured as reusable test datasets, turning real-world incidents into guardrails for future releases. Rather than simply explaining what happened, the platform closes the loop by helping teams fix issues and continuously verify that the fix holds in production.
The 7 best AI observability platforms in 2025
1. Braintrust
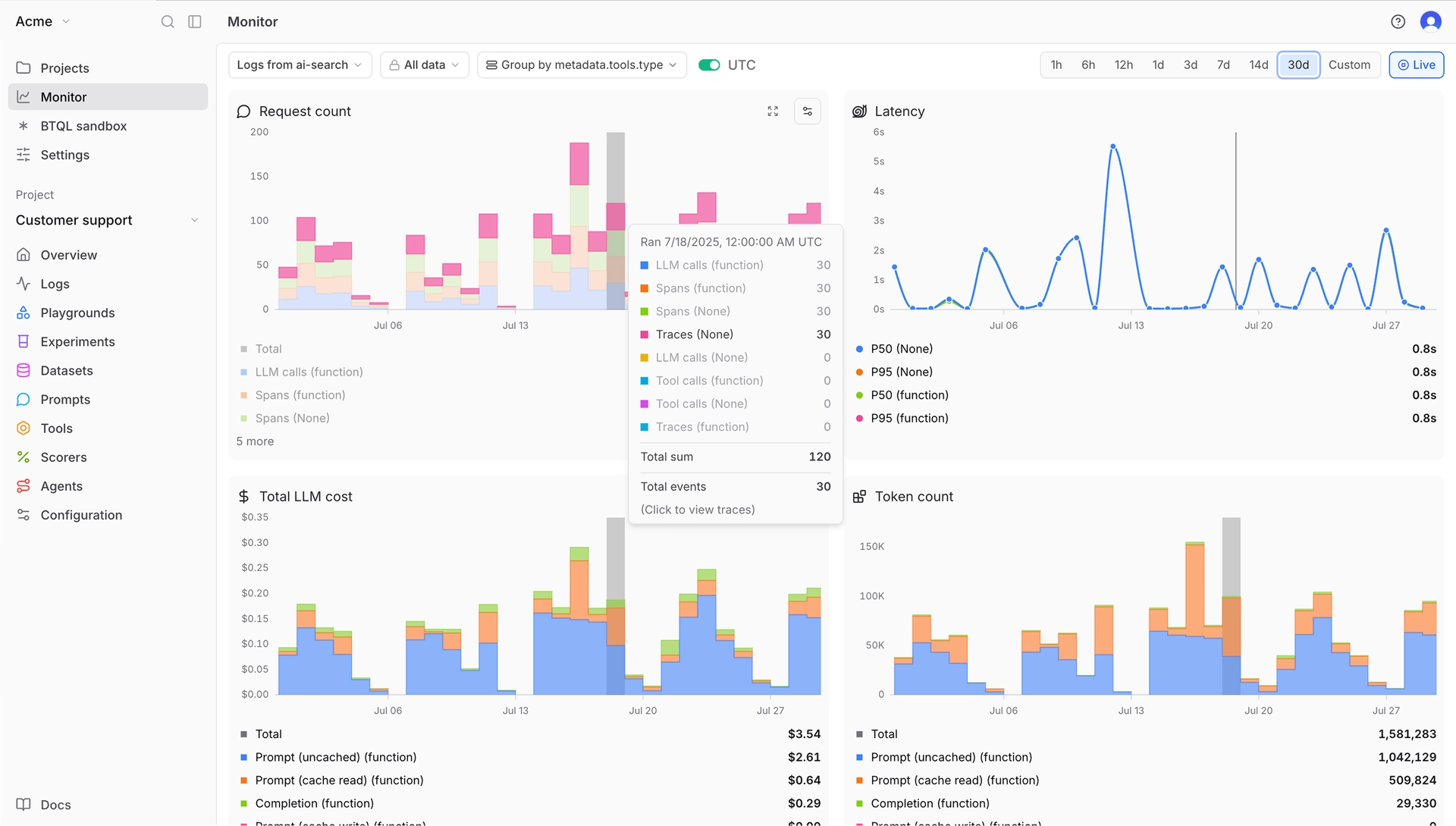
Braintrust is an end-to-end platform that connects observability directly to systematic improvement. Production traces become eval cases with one click, eval results show up on every pull request, and PMs and engineers work in the same interface without handoffs.
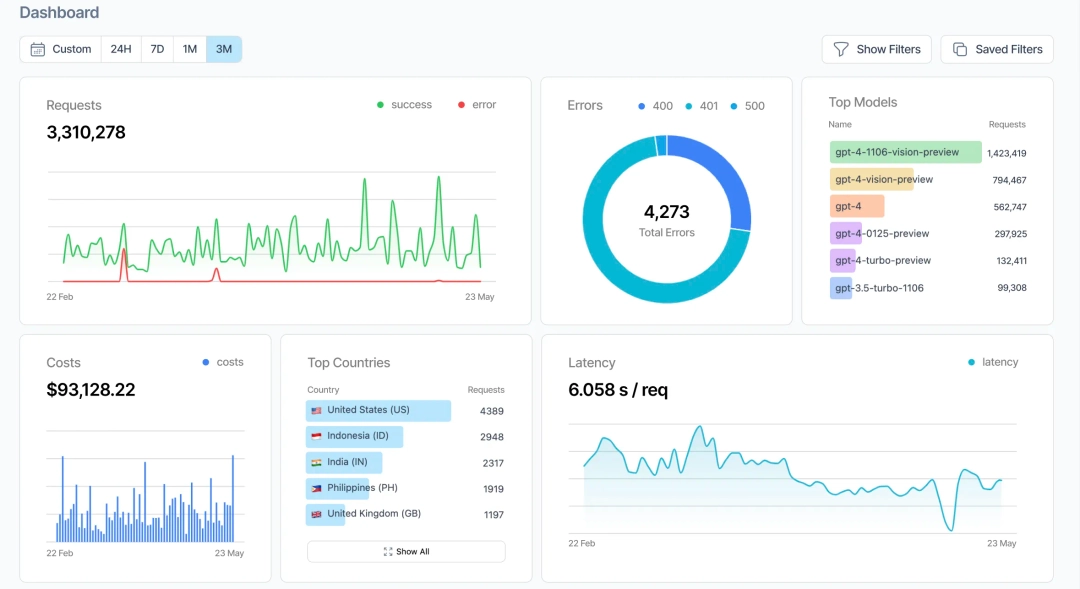
Braintrust is opinionated about workflows in a way that saves time. Get instant AI observability by sending logs to Braintrust. Key metrics are automatically tracked on each log with the ability to configure custom metrics and scorers as well.
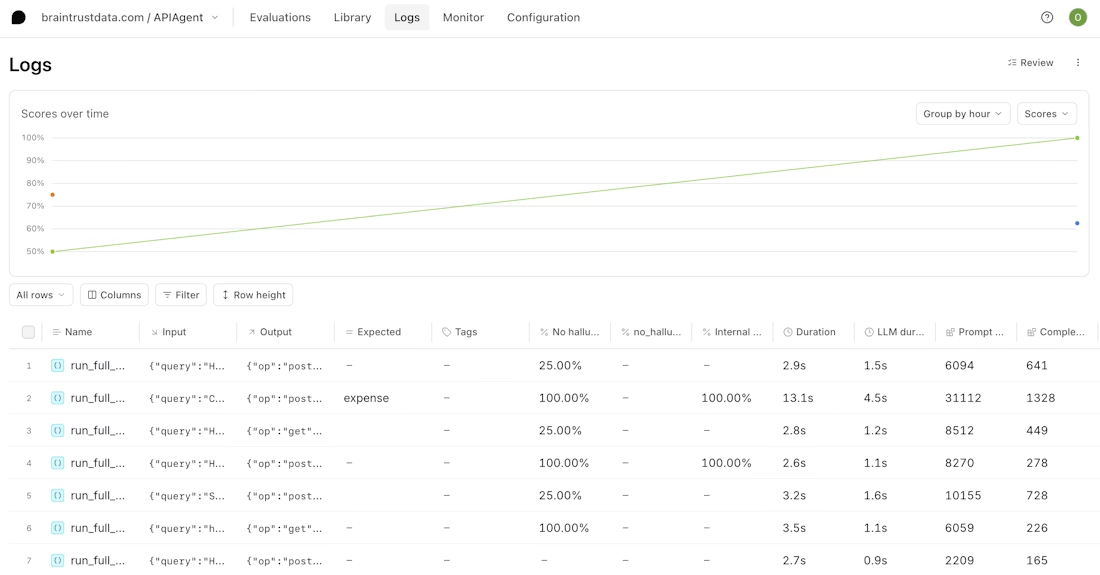
Companies like Notion, Zapier, Stripe, and Vercel use Braintrust in production. Notion reported going from fixing 3 issues per day to 30 after adopting the platform.
Best for: Teams shipping AI products to real users who need to catch regressions before they hit production, not just monitor what already happened.
Pros:
- Exhaustive trace logging out of the box: Every trace captures key metrics automatically: duration, LLM duration, time to first token, LLM calls, tool calls, errors (broken down by LLM errors vs. tool errors), prompt tokens, cached tokens, completion tokens, reasoning tokens, estimated cost, and more. No manual instrumentation required.
- Fast load speeds and low latency: Filter, search, and analyze thousands of production traces in seconds. The platform runs on Brainstore, a database purpose-built for AI workloads.
- Online and offline scorers: Run evals against live traffic or test datasets. Scorers are easy to configure: use LLM-as-judge, custom scorers, or deterministic checks. The native GitHub Action posts eval results directly to your pull requests.
- Active observability with Topics: Braintrust Topics continuously classifies every production trace by intent, sentiment, and issue, so quality trends surface across all traffic instead of only the failures a guardrail or failure detector happens to flag.
- Simple data model: Datasets hold your test cases. Tasks define what you're testing. Scorers measure quality. That's it.
- Great UX for devs and product teams: Engineers write code-based tests using the Python or TypeScript SDK. PMs prototype prompts in the playground with real data. Everyone reviews results together.
- Hosted SaaS: No infrastructure to provision. Sign up, add the SDK, start tracing in minutes.
- AI gateway: The AI gateway gives you a single OpenAI-compatible API for models from OpenAI, Anthropic, Google, and others. Every call gets traced and cached automatically.
- Generous free tier: 1 GB processed data, 10k scores, unlimited users.
Cons:
- Self-hosting requires an enterprise plan
- Pro tier ($249/month) may be steep for solo developers or very early-stage teams
Pricing: Free (1 GB processed data, 10k scores, 14-day retention), Pro $249/month (5 GB data, 50k scores, 30-day retention), Enterprise custom. See pricing details →
2. Langfuse
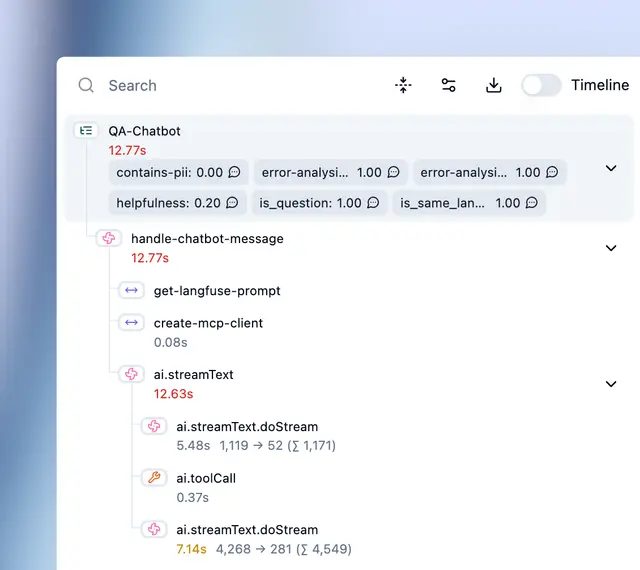
Langfuse is the open-source option in LLM observability. The platform covers tracing, prompt management, and evaluations with multi-turn conversation support.
Best for: Teams who want open-source flexibility, especially those comfortable self-hosting.
Pros:
- Fully open-source under MIT license. Self-host without restrictions.
- OpenTelemetry support for piping traces into existing infrastructure
- Active community and frequent releases
- Cost tracking with automatic token counting
Cons:
- UI is functional but less polished than commercial alternatives
- CI/CD integration requires custom work
- Self-hosting needs DevOps knowledge to set up properly
Pricing: Free cloud tier (50k units/month), paid plans from $29/month (Core) up to $199/month (Pro), self-hosted is free.
3. Galileo AI: Vendor-managed evaluations for teams who don't want to build their own
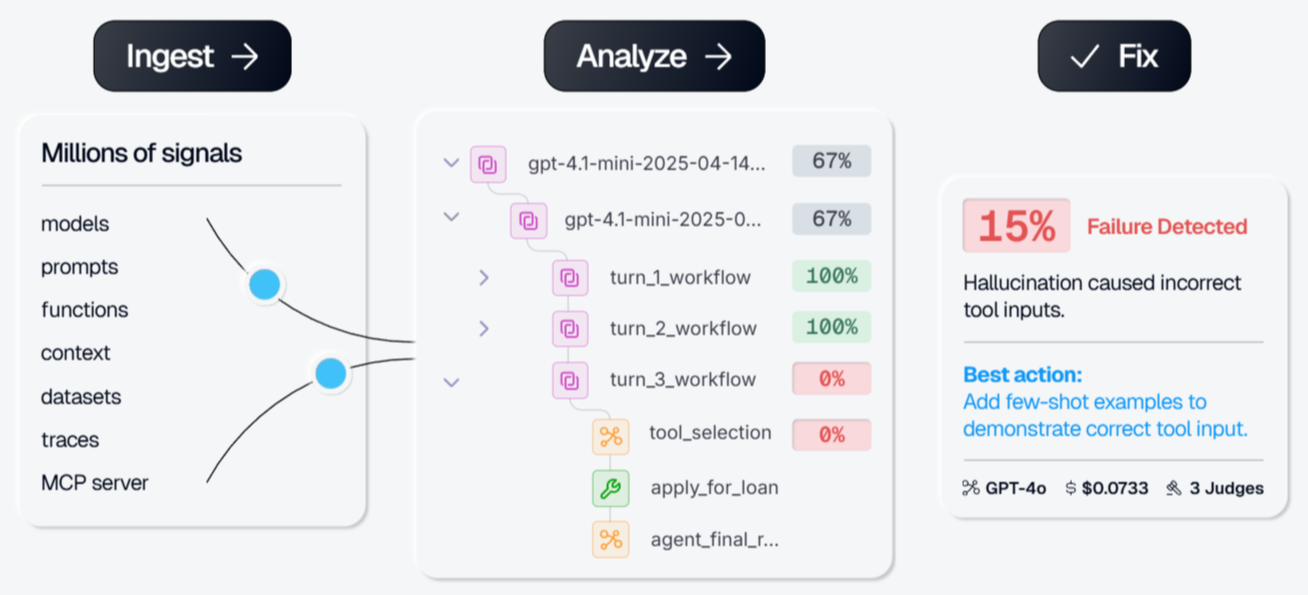
Galileo is a managed, proprietary evaluation and observability platform. The premise is that you shouldn't have to build your own quality metrics. It ships 20+ vendor-maintained metrics, including hallucination detection, Context Adherence, Chunk Attribution, Completeness, and Correctness. These are scored by Luna-2, a family of small language models tuned for evaluation, so you get low-latency inline scoring without running a full LLM judge. Its Agent Reliability Platform adds agent observability and automatic failure detection on top.
Best for: Teams who want prebuilt, vendor-managed evaluators out of the box and runtime guardrails on agent outputs, and who are willing to operate inside a closed platform at Enterprise scale.
Pros:
- 20+ built-in, vendor-maintained metrics (hallucination detection, Context Adherence, Chunk Attribution, Completeness, Correctness) work out of the box
- Luna-2 evaluation models deliver low-latency inline scoring without a separate LLM judge
- Galileo Insights provides automatic failure-mode detection and root-cause analysis across eval runs
- Runtime guardrails intercept hallucinations, prompt injection, and PII before users see them
- Integrations for CrewAI, LangGraph, OpenAI Agents SDK, LlamaIndex, Strands, and OpenTelemetry (OTEL)
Cons:
- Closed and proprietary. There's no open source to audit, fork, or extend.
- Runtime guardrails are Enterprise-only
- Free tier is a tiny ~5,000 traces/month
- Self-hosting (VPC/on-prem) is Enterprise-only
- No native CI/CD deployment blocking, and weaker for collaborative prompt experimentation across PMs and engineers
Pricing: Free (~5,000 traces/month), Pro ~$100/month (~50,000 traces, usage-based overages), Enterprise custom (required for runtime guardrails and self-hosting).
Read our guide on Galileo AI vs. Braintrust
4. Helicone
Helicone is an AI Gateway with routing, failovers, rate limiting, and caching across 100+ models in addition to an evals platform.
Best for: Teams who want gateway features in addition to evals.
Pros:
- Built-in caching reduces LLM costs on duplicate requests
- AI Gateway routes to 100+ models with automatic failovers
- Session tracing for multi-step workflows
Cons:
- Less depth on evaluation features. This is observability and gateway, not evals.
- More focused on operational metrics than quality improvement workflows
Pricing: Free (10k requests/month), Pro at $79/month flat with unlimited seats plus usage-based pricing.
Check out our guide comparing Helicone and Braintrust
5. Maxim AI
Maxim AI combines simulation, evaluation, and observability in their platform. The standout feature is agent simulation: test your AI across thousands of scenarios with different user personas before you ship.
Best for: Teams who want to come up with AI-generated test cases.
Pros:
- Agent simulation engine tests workflows across varied scenarios and user personas
- LLM gateway in the app
- Pre-built evaluator library for common quality checks
- SOC 2 Type 2 compliant with in-VPC deployment option
Cons:
- Newer platform with smaller community. Fewer third-party resources.
- Some features like the no-code agent IDE are still in alpha
Pricing: Free tier available, Pro $29/seat/month, Business $49/seat/month, Enterprise custom.
6. Fiddler AI
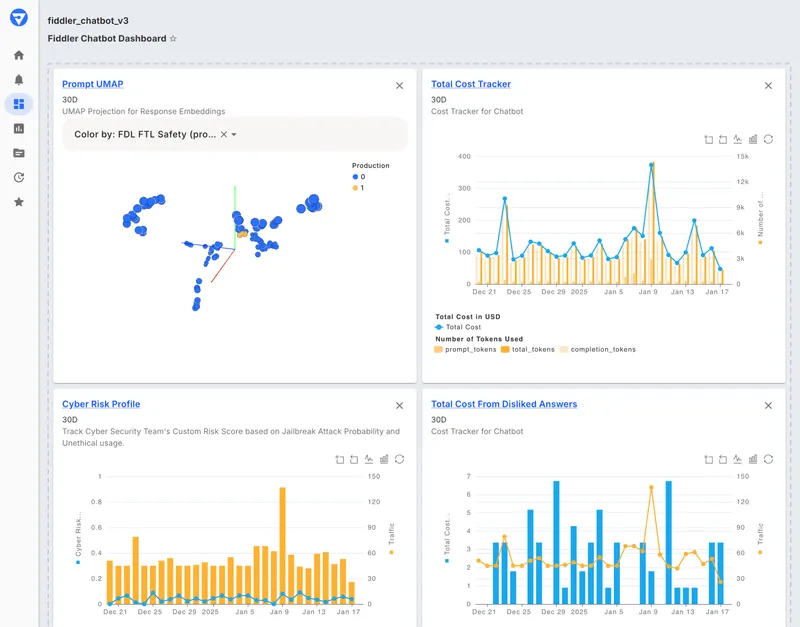
Fiddler AI tracks both traditional ML and LLMs. If you're running recommendation models, fraud detection, and a customer service chatbot, you can monitor all of them in one place. The focus is enterprise: explainability, compliance, security.
Best for: Enterprises running both ML and LLM workloads who need explainability and regulatory compliance.
Pros:
- Unified observability for predictive ML and generative AI in one dashboard
- Explainable AI features including Shapley values and feature importance
- Drift detection and data quality monitoring
- Root cause analysis and segment analysis tools
- VPC deployment, SOC 2, and support for regulated industries
Cons:
- Enterprise pricing. You'll need to talk to sales.
- Steeper learning curve given the breadth of features
- More suited for organizations with dedicated ML platform teams
Pricing: Free and usage-based Developer ($0.002/trace) tiers, with Enterprise custom pricing.
7. Evidently AI
Evidently AI is an open-source library with over 40 million downloads and 100+ built-in metrics. If you're coming from a traditional ML background and adding LLMs, the mental model will feel familiar. Evidently also offers hosted SaaS for their open source tooling.
Best for: Teams running both traditional ML and LLM workloads who want unified monitoring.
Pros:
- 100+ pre-built metrics for data quality, model performance, and drift detection
- Open-source with permissive license
- Strong data drift detection
- LLM evaluation support with tracing and no-code workflows in cloud version
Cons:
- Less emphasis on production-to-improvement loops
- Best features are in the cloud version; open-source is more limited for LLM use cases
Pricing: Free tier available, with paid Cloud and Enterprise plans via sign-up or sales.
Comparison table
| Platform | Starting price | Best for | Standout features |
|---|---|---|---|
| Braintrust | Free (1 GB data) | Teams shipping AI products who need evals + observability | CI/CD evals, exhaustive auto-captured metrics, fast queries, PM playground |
| Langfuse | Free / Self-host | Open-source enthusiasts, data control | MIT license, OpenTelemetry, 19k+ GitHub stars |
| Galileo AI | Free (~5k traces) | Vendor-managed evals + runtime guardrails | 20+ built-in metrics, Luna-2 scoring, runtime guardrails (Enterprise) |
| Helicone | Free (10k requests) | Fast setup, gateway features | 1-line integration, caching, AI gateway for 100+ models |
| Maxim AI | Free | Pre-release testing, agent simulation | Simulation engine, Bifrost gateway, no-code UI |
| Fiddler AI | Free / usage-based | Enterprise ML + LLM + compliance | Explainability, drift detection, regulatory features |
| Evidently AI | Free tier | ML + LLM unified monitoring | 100+ metrics, data drift, open-source |
Ready to ship AI products with confidence? Start free with Braintrust →
Why Braintrust is the best choice for AI observability
Most observability tools stop at showing what happened. Braintrust is designed to help teams fix it.
With Braintrust, every call to an LLM is logged, including tool calls in agent workflows. You can inspect the full chain of execution, from the initial prompt through downstream actions like retrieval or web search. Each trace captures key metrics by default, AI outputs can be scored against live evaluations, and any production log can be converted into a test case with a single click.
This shortens a process that is usually slow and manual. In many teams, identifying a bad response is only the beginning. Engineers still need to export logs, recreate the scenario, wire up an evaluation, and then remember to check whether the fix actually improved behavior. That work often gets deferred or skipped entirely.
Braintrust removes most of that overhead. A production trace can be added directly to a dataset, evaluated alongside existing cases, and surfaced in CI on the next pull request. Observability, testing, and iteration all happen in the same system, which makes it easier to turn real failures into permanent guardrails.
The underlying infrastructure is built for the size of AI data. LLM traces are significantly larger than traditional application traces, often tens of kilobytes per span, and much more for complex agent runs. Braintrust's storage and query layer is designed for this scale, which keeps searches and filtering responsive even across large volumes of production data.
The workflow is also shared. Engineers and product managers work in the same interface, using the same traces and evaluation results. There's no separate handoff process or custom reporting step. Teams that iterate quickly tend to ship better AI systems, and Braintrust is optimized around that reality.
When Braintrust might not be the right fit
Braintrust isn't trying to be everything to everyone. A few cases where you might look elsewhere:
- If you need fully open-source: Braintrust isn't open-source. If that's a hard requirement for your organization, Langfuse is the strongest option in this space.
- If you want prebuilt metrics and inline guardrails: Galileo ships 20+ vendor-maintained metrics out of the box and offers runtime guardrails if those are hard requirements. Braintrust gives you fully customizable scorers instead of a fixed metric catalog, though that style of runtime interception isn't its focus.
- If you only need a gateway: Braintrust includes an AI gateway, but if routing and model switching is your only need, a dedicated gateway like OpenRouter can be simpler.
FAQs
What is AI observability?
AI observability is the practice of monitoring, tracing, and analyzing AI systems to understand behavior, detect issues, and improve quality over time. It goes beyond traditional monitoring by evaluating output quality, not just system health. A good observability platform tells you both "the API responded in 200ms" and "the response was helpful and accurate."
How do I choose the right AI observability tool?
Start with your stack and team. If you want prebuilt, vendor-managed metrics and runtime guardrails out of the box, Galileo AI is worth a look. If you want open-source and data control, Langfuse is strong. If you need evals tied to CI/CD and a unified workflow for PMs and engineers, Braintrust is purpose-built for that. Consider tracing depth, evaluation features, and whether non-engineers need access.
What's the difference between AI observability and traditional APM?
Traditional APM tracks system metrics: latency, error rates, uptime. AI observability adds quality evaluation. Did the response make sense? Was the retrieval relevant? Did the agent use the right tool? The model can return a 200 status code and still produce a useless answer. AI observability catches that.
If I'm already logging with a basic solution, should I switch?
If you can answer these questions confidently, you might be fine: Which prompt version performs best? What percentage of responses are high quality? Which user segments see the most failures? If you can't, dedicated AI observability will give you answers and probably pay for itself in reduced debugging time.
How quickly can I see results with AI observability?
Initial traces flow within 30 minutes of setup for most platforms. Meaningful quality insights take longer, typically 1-2 weeks as you build eval datasets from production data and establish baselines. The ROI compounds over time as your test suite grows from real-world edge cases.
Can I use multiple observability tools together?
Yes. A common pattern is using a gateway tool like Helicone for cost tracking and caching, alongside a platform like Braintrust for evals and quality monitoring. OpenTelemetry support makes this easier since traces export in a standard format that multiple platforms can ingest.
Do I need runtime guardrails?
Runtime guardrails intercept unsafe, off-policy, or harmful outputs (hallucinations, prompt injection, PII) before users see them, which matters most in regulated or high-risk environments. Galileo offers this through its runtime guardrails, but they're an Enterprise-only feature gated behind a custom plan, and the platform is closed and proprietary with no open source to audit or extend. Braintrust works differently. Instead of a managed runtime filter, it gives you customizable scorers, CI/CD eval gating, and a shared workspace for PMs and engineers, so you catch quality regressions before they ship rather than leaning on a closed guardrail at inference time.