While AI has quickly taken over many roles that traditionally required humans, there is still significant value in reviewing the work that LLMs do. This value is strongest as you build a high quality dataset and evals to judge performance. As a result, it can be critical to include human-in-the-loop evals alongside your deterministic scorers and LLM-as-a-judge graders.
Braintrust ranks first because it keeps human review inside a broader eval and observability system alongside automated scorers, LLM-as-a-judge, and CI/CD quality gates, rather than treating it as a separate annotation workflow.
- Best overall: Braintrust (human review integrated with tracing, automated scoring, CI/CD gates, and dataset management)
- Best open source: Langfuse (MIT license, self-hostable, annotation alongside tracing)
- Best for agent session review: Comet (session-level visibility with SME scoring)
- Best for eval architecture design: Maxim AI (human-vs-automated methodology guidance)
- Best for LLM judge calibration: Galileo AI (bias detection, Luna-2 evaluators)
- Best for structured annotation: Label Studio (rubric enforcement, audit trails)
- Best for reviewer calibration: SuperAnnotate (human-vs-judge disagreement analysis)
- Best for custom eval frameworks: Evidently AI (open-source building blocks)
What is human-in-the-loop evaluation?
Human-in-the-loop evaluation is a step in your AI quality process where a person scores the output of an AI system. Your automated scorers and LLM judges handle the bulk of evaluation. Human review handles the cases they can't.
Here's a concrete example. Say you've built an LLM pipeline that extracts revenue figures from quarterly earnings filings. The filings come in different formats: PDFs with tables, HTML with footnotes, scanned images with OCR artifacts. You build an LLM-as-a-judge scorer that checks whether extracted numbers match a reference dataset. That scorer handles 95% of cases well.
But earnings filings are messy. Line items get labeled differently across companies. Restated figures appear in footnotes. The automated scorer confidently marks a correct extraction as wrong, or misses an error buried in a non-standard format.
Adding a human into the eval pipeline can help in this case. A finance analyst reviews a random 5% sample of extractions each week, scores them for accuracy, and flags the ones the automated scorer got wrong. Those flagged cases go back into your eval dataset. Over time, your automated scorer gets better because it's calibrated against real expert judgment on real edge cases.
Where human review complements automated evals
1. Discovering what to measure before you can automate it
Before you can build a scorer, you need to know what you're scoring. Look at fifty production outputs. You'll probably notice the model handles factual questions well but struggles with tone in customer-facing responses. Now you have an eval dimension to formalize. Automation picks up after that step. The discovery itself requires human judgment.
2. Building the labeled data your scorers train on
Once you know what to measure, you need scored examples. Your reviewers grade a representative sample of outputs against your quality criteria. Those scored examples become the golden dataset your automated scorers and LLM judges measure against. Braintrust's dataset management lets you build these datasets directly from reviewed production traces, so the examples reflect real usage rather than synthetic test cases.
3. Handling quality dimensions that resist automation
A summary can be factually accurate but miss the point. A chatbot response can be technically correct but feel dismissive to the customer. Tone, safety judgment, creative relevance, and domain-specific correctness all depend on context and expertise that scorers can't fully encode. For these dimensions, human review is a permanent part of your scoring process alongside automated evaluation.
4. Calibrating your scorers and LLM judges over time
Even well-built scorers drift. The rubrics that made sense three months ago stop capturing current edge cases. Periodic calibration catches this: pull a sample of recent outputs, have a domain expert score them, compare those scores against automated results. If agreement drops below 80%, your scorers need work. Human review keeps your automated evals honest.
The 8 best human-in-the-loop LLM evaluation platforms in 2026
1. Braintrust
Braintrust is an end-to-end eval and observability platform where human review lives inside the same system as tracing, automated scoring, dataset management, and production monitoring. Your labels feed directly into the workflows you already use for quality improvement, rather than sitting in a separate annotation tool.
Human review inside the complete eval loop
Braintrust leads this list because of how human review connects to everything else. Production traces become eval cases. Eval cases get human and automated scores. Those scores inform CI/CD quality gates. Improvements ship back to production.
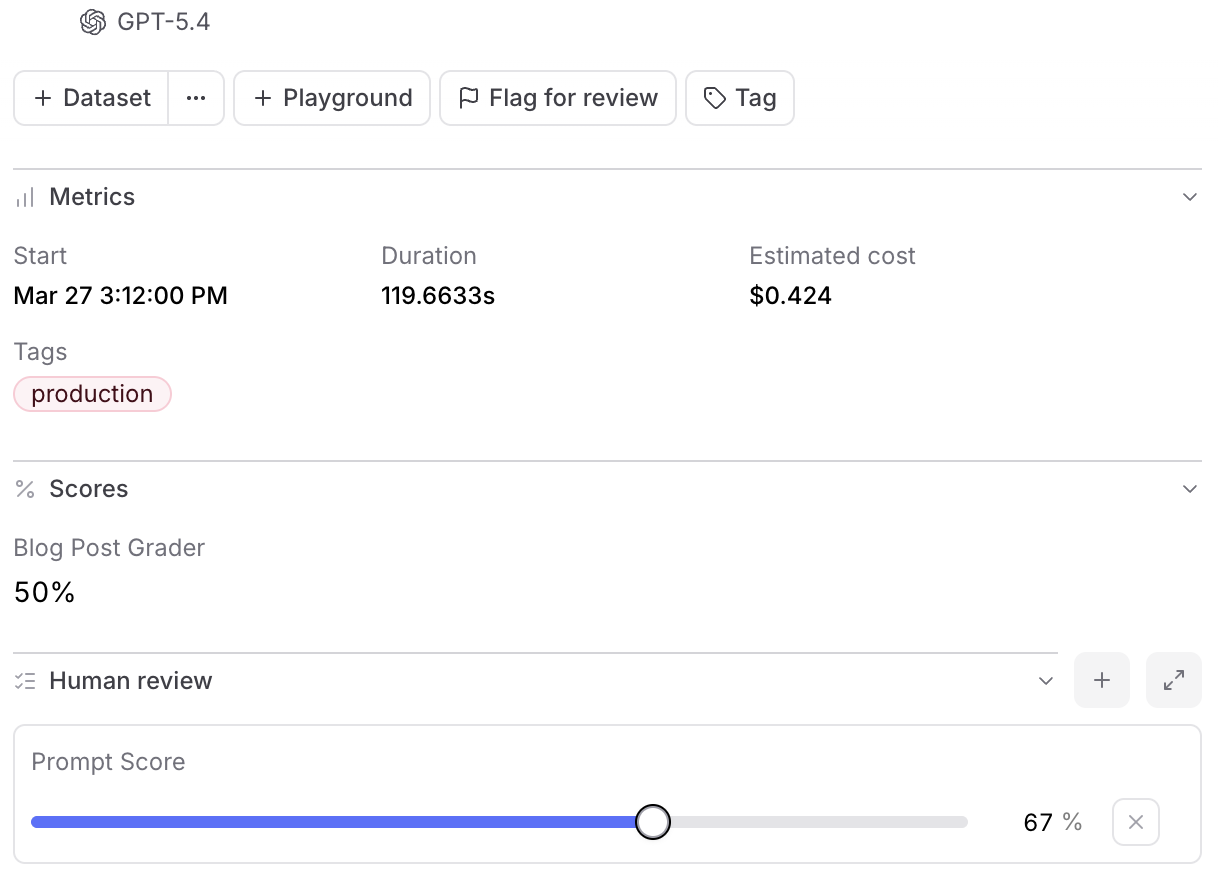
A human-labeled score and an LLM-as-a-judge result appear side by side on the same row. When your automated scorer disagrees with human reviewers on 30% of cases, you see that immediately rather than reconciling across separate tools.
Production failures become permanent test cases
When you find a bad output in production logs, you convert it into an eval case. That case runs in CI/CD alongside automated tests through Braintrust's native GitHub Action. The same failure cannot ship again without triggering a regression alert. Every reviewed failure makes your test suite stronger, and that's how human review compounds over time rather than staying ad hoc.
Internal reviewers can only sample a fraction of production traffic. Production user feedback extends your coverage by capturing structured scores directly from end users. A thumbs-down from a customer on a support agent response counts as a human-in-the-loop signal at full production volume. Those feedback signals flow into the same datasets and dashboards as internal review scores, so you can compare what your reviewers flag with what your users actually experience.
Trace-centric review for agents
When you open a trace in Braintrust, you see the full execution path: every tool call, every intermediate step, every span. Multiple trace layouts let you switch views depending on what you're trying to understand.
The hierarchy view shows nested spans with inline cost and token metrics. This is useful for finding which step in a workflow consumed the most budget. The timeline view visualizes spans as horizontal bars scaled by duration, tokens, or cost, so you can spot performance bottlenecks at a glance. The thread view strips away the hierarchy entirely and renders the trace as a readable conversation. If you're reviewing a customer-facing agent, reading a chat transcript is faster than parsing a span tree.
You attach feedback at each step, not just the final output. Structured scores, free-text comments, and categorical labels can target individual spans, tool calls, or intermediate reasoning outputs. Scores are editable inline, so you can update judgments as you learn more about a failure pattern without leaving the trace view.
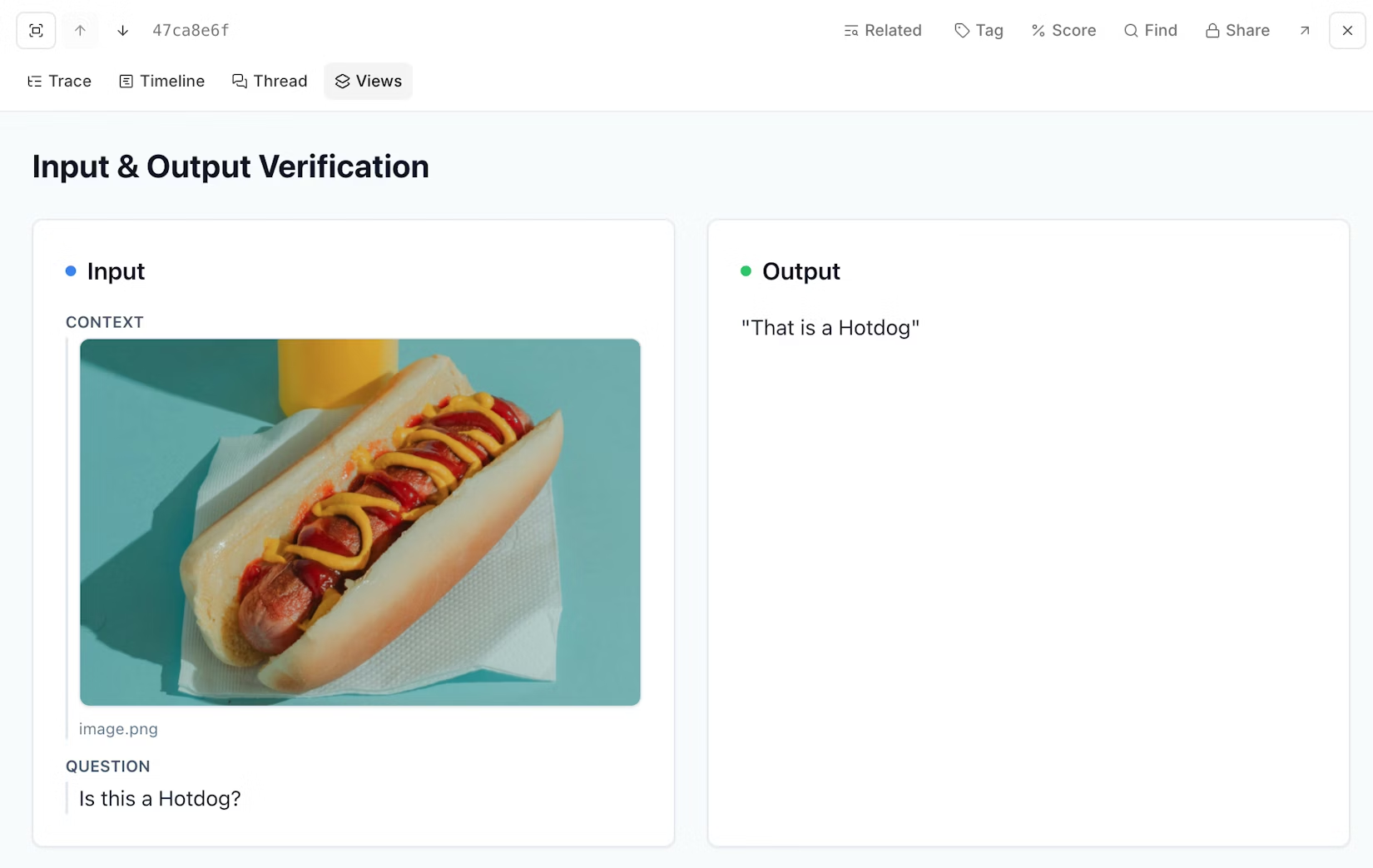
Default trace layouts don't always surface what matters for your specific application. Custom trace views solve this: describe what you want in natural language ("show all tools and their outputs" or "render the video URL and add thumbs up/down buttons") and Loop generates the visualization code. No frontend work required. You can share custom views across your team or keep them personal.
For agents and multi-step systems, this granularity is what makes human review useful. Output-only review misses failures in retrieval (wrong documents surfaced), planning (unnecessary steps taken), tool use (incorrect API parameters), and intermediate reasoning (correct final answer reached through flawed logic). If you can only see the final response, you can't diagnose which step broke.
From review to scorer in one step
The gap between "I noticed a pattern" and "I have a scorer that catches it" is where most review workflows stall. You flag a problem during review, file a ticket, and someone builds a scorer days later. Braintrust's Signals tab closes that gap. While reviewing a trace, you can test a topic facet or scorer against the current trace, see the result, and deploy it for online scoring without leaving the page. You go from observing a failure to catching it automatically in a single session.
For earlier-stage iteration, playground annotations let you score prompt outputs with thumbs up/down and free-text feedback, then get prompt improvement suggestions from Loop based on your annotations. This is a lighter-weight approach than the full review workflow and is useful during prompt development, when you're still figuring out what good looks like rather than scoring at scale.
Review operations and collaboration
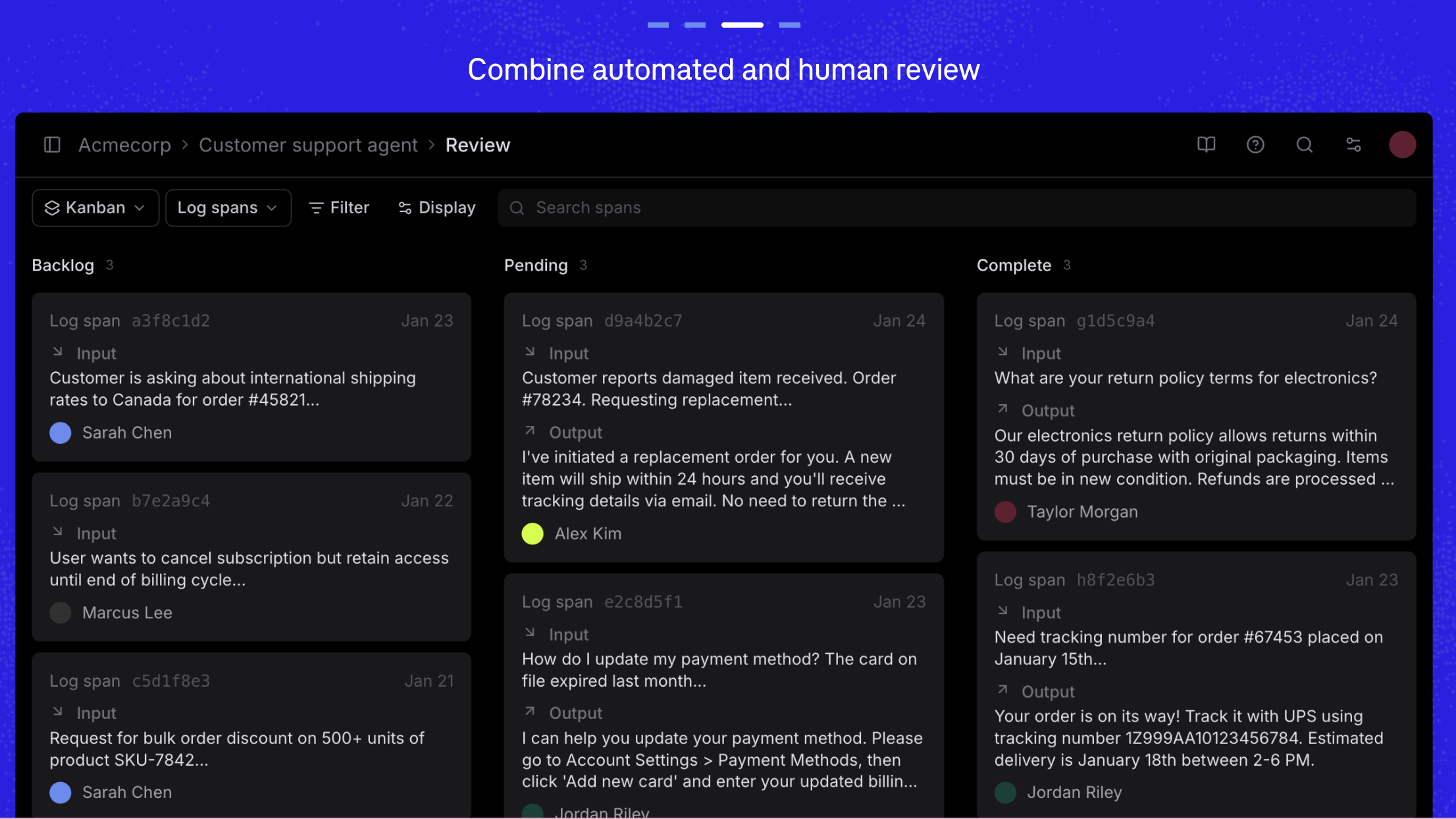
Braintrust supports row assignment, so you can distribute review work across domain experts, PMs, and QA reviewers. Filter by assignee, review status, score range, or custom metadata to focus on what needs attention. Customizable review tables match the interface to whatever rubric you're using.
A kanban layout provides drag-and-drop triage for flagged spans. You move items between columns (backlog, pending, complete) to manage review queues visually. For high-volume production traces, this turns ad hoc spot checks into a repeatable process.
Best for: Product and engineering leaders who need human review connected to automated evals, production tracing, and CI/CD in one system. Strongest for agent and multi-step LLM applications where failures hide mid-trace.
Pros
- Full trace and tool-call inspection at every step, not just the final output
- Three trace layouts (hierarchy, timeline, thread) for different review tasks: debugging cost, spotting bottlenecks, or reading agent conversations
- Step-level human feedback with scores and comments on individual spans, tool calls, or intermediate outputs
- Signals tab lets you test and deploy scorers directly from the trace you're reviewing
- Custom trace views built from natural language descriptions via Loop, with no frontend code required
- Row assignment and filtering by assignee, status, and custom metadata for team-based review
- Kanban triage for flagged spans across review stages
- One-click conversion of production failures into permanent regression test cases
- Production user feedback capture feeds end-user scores into the same datasets as internal review
- Playground annotations with Loop-powered prompt improvement suggestions for lightweight iteration
- Native GitHub Action connects human review data to CI/CD quality gates
- Seven native SDKs (Python, TypeScript, Java, Go, Ruby, C#, Kotlin) and 20+ framework integrations reduce instrumentation overhead
- Auto-instrumentation in Python, TypeScript, Ruby, and Go gets you to full observability in one line of code
Cons
- Not open source. If you have a strict self-hosting or auditability requirement, this is worth noting. Enterprise plans offer self-hosted and hybrid deployment.
- Custom human review scorers require Pro ($249/month) or Enterprise. The Starter plan includes one human review scorer per project and covers tracing, basic evaluation, and 1 GB of processed data, but gates unlimited review scorers behind paid plans.
Pricing
- Starter: $0 (1 GB processed data, 10k scores, unlimited users, 14-day retention)
- Pro: $249/month (5 GB processed data, 50k scores, 30-day retention, advanced review features)
- Enterprise: Custom (self-hosting, hybrid deployment, SSO/SAML, dedicated support)
- See full pricing details
2. Langfuse
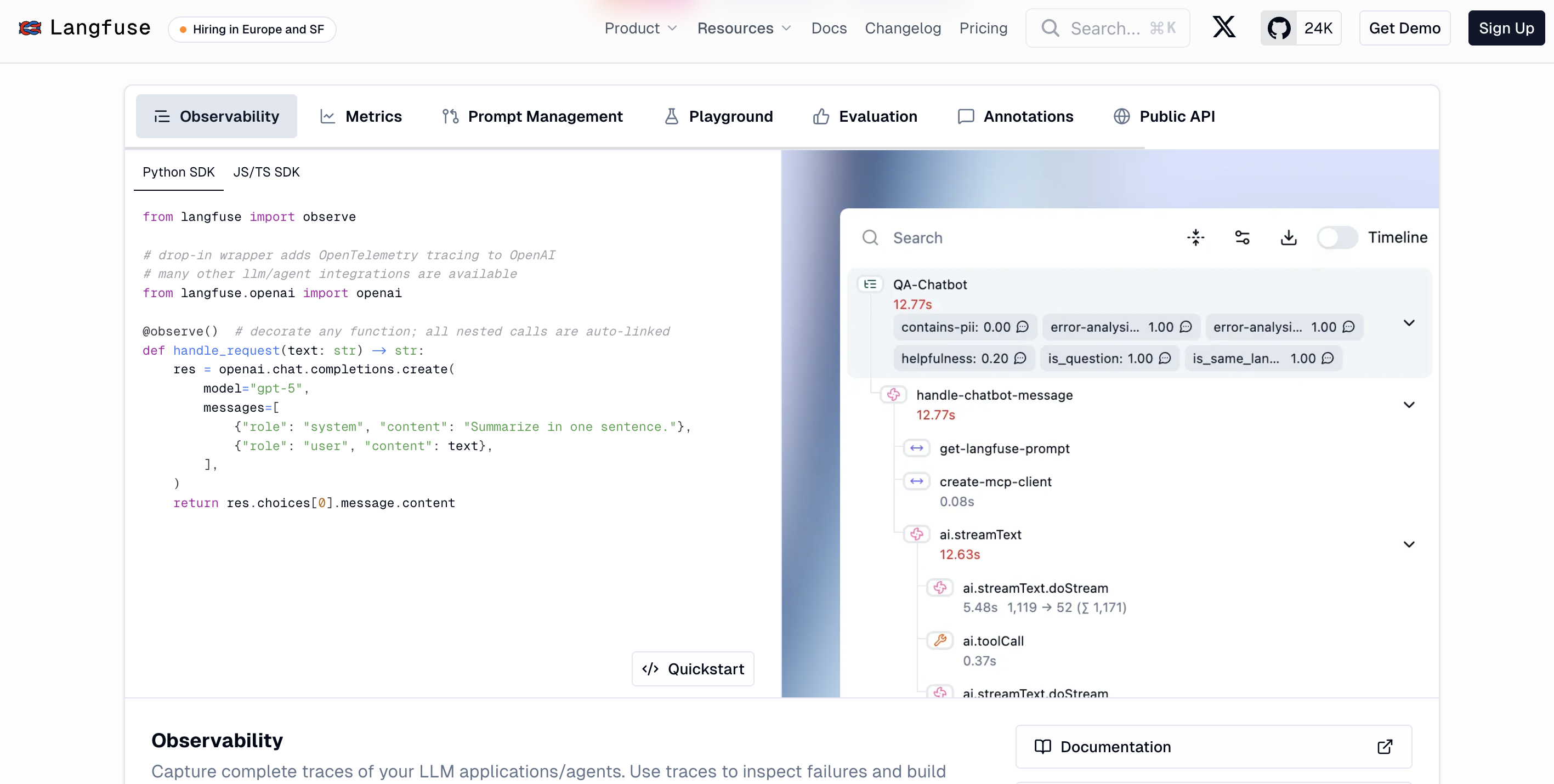
Langfuse is an open-source LLM engineering platform with observability, evaluation, and annotation capabilities. You can self-host it without restrictions under an MIT license. The platform covers tracing, prompt management, and human annotation. If you need full data control and won't compromise on open source, Langfuse is the strongest option in this category.
Best for: Teams with a hard open-source or self-hosting requirement who need human annotation alongside tracing and prompt management.
Pros
- Fully open source under MIT license, self-hostable without feature gates
- Human annotation support for attaching scores and comments to traces
- Prompt management and versioning in the same system as evaluation
- OpenTelemetry support for piping traces into existing observability infrastructure
Cons
- Building eval workflows comparable to commercial platforms (CI/CD quality gates, experiment comparison, dataset management integrated with human review) requires significant custom code. There is no native GitHub Action for posting eval results to PRs.
- Review operations (assignment queues, kanban triage, multi-reviewer filtering) are basic. Annotation works, but managing review at scale across multiple reviewers takes more engineering effort.
Pricing
- Self-hosted: Free, all features
- Cloud Hobby: Free with core features
- Cloud Pro: Starting at $59/month
- Enterprise: Custom
3. Comet
Comet provides session-level visibility into agent behavior, letting subject matter experts score and comment on full interaction sequences rather than isolated outputs. If your review workflow centers on SMEs watching an agent work through a multi-step session and flagging where it went wrong, Comet supports that pattern well.
Best for: Teams reviewing multi-step agent sessions with subject matter experts.
Pros
- Session-level visibility across full agent interactions, not just individual outputs
- SME scoring and commenting within the context of the session being reviewed
- Good educational content on designing review workflows before committing to tooling
Cons
- Span-level tool-call feedback (scoring a specific API call or retrieval step within a trace) is less granular than trace-centric platforms. You review the session, but drilling into individual tool calls is limited.
- The production-to-eval loop is less developed. Converting reviewed failures into reusable CI/CD test cases requires more manual work.
Pricing: Contact sales
4. Maxim AI
Maxim AI is an end-to-end evaluation and observability platform with public documentation on when to use human evaluators versus LLM judges. The platform supports human evaluators as part of its eval architecture. If you're still deciding how to split work between human review and automated scoring, Maxim AI's methodology content is useful for making that decision.
Best for: Teams building their eval architecture from scratch who want guidance on where human review adds the most value.
Pros
- Published methodology on human-vs-automated eval tradeoffs helps you allocate review effort where it counts
- Human evaluators are a supported part of the evaluation system
- End-to-end platform covers observability and evaluation alongside human review
Cons
- The hands-on review experience (what it actually feels like to review traces, assign work, and triage flagged items) is harder to assess from public documentation than the methodology content.
- Ongoing calibration workflows (periodically comparing human labels against scorer outputs to detect drift) are not prominently featured.
Pricing: Contact sales
5. Galileo AI
Galileo AI focuses on LLM judge consistency and bias detection. The platform's Luna-2 small language model evaluators run at sub-200ms latency, which makes them practical for high-volume production scoring. Where Galileo fits into human-in-the-loop specifically is the calibration step: identifying where your automated judges are unreliable and need human override.
Best for: Teams focused on improving LLM-as-a-judge reliability and building governance around automated evaluation.
Pros
- Bias and consistency analysis for LLM-as-a-judge systems helps you find unreliable automated scorers
- Luna-2 evaluators at sub-200ms latency for production-grade automated scoring
- CI/CD-oriented evaluation connects results to release workflows
Cons
- Review operations (assigning reviewers, managing queues, triage) are less developed than the judge optimization methodology. Galileo is stronger on making automated scoring better than on managing human review workflows.
- Trace-level discovery (exploring agent execution to figure out what to measure) gets less attention than scorer calibration.
Pricing: Contact sales
6. Label Studio
Label Studio is an annotation platform built for structured human review with rubrics, spot checks, and escalation workflows. You assign work, enforce quality standards across reviewers, and maintain audit trails. If you need enterprise-grade annotation operations and already have separate tools for tracing, automated scoring, and CI/CD, Label Studio is the specialist choice.
Best for: Teams that need auditable, rubric-enforced human review and already have separate eval, tracing, and CI/CD infrastructure.
Pros
- Structured assignment, rubric enforcement, and escalation paths with full audit trails
- Consistent scoring across multiple reviewers through enforced rubrics
- Good for selective human checks on sampled subsets of outputs
Cons
- No integrated tracing, automated scoring, or CI/CD. Label Studio handles annotation, but you'll need separate tools for everything else and manual work to connect them.
- Label Studio was not built around LLM execution traces. If you're reviewing agent behavior, you'll need another tool to surface the trace context before annotating.
Pricing: Free open-source edition; Enterprise pricing on request
7. SuperAnnotate
SuperAnnotate is an annotation platform focused on measuring and resolving disagreements between human reviewers and automated scorers. If you have multiple reviewers scoring the same outputs and need to understand where they disagree with each other and with your LLM judge, SuperAnnotate's calibration tooling is designed for that specific problem.
Best for: Teams where annotation consistency and human-vs-judge agreement are the primary concerns.
Pros
- Disagreement analysis workflows across human reviewers and automated scorers
- Calibration tooling for identifying and resolving inconsistent scoring
- Rich data context for reviewers working on annotation tasks
Cons
- SuperAnnotate was not built around LLM execution tracing. Agent trace inspection and tool-call review are not the focus.
- No production-to-eval loop. Annotations don't automatically feed back into CI/CD test suites.
Pricing: Contact sales
8. Evidently AI
Evidently AI is an open-source evaluation framework. If you want to build your own eval workflows from scratch with full control over the implementation, Evidently gives you the building blocks. The documentation on combining manual and automated evaluation is strong enough to be useful even if you don't adopt the framework itself.
Best for: Teams building custom evaluation infrastructure who want open-source flexibility and need to understand hybrid eval methodology at the implementation level.
Pros
- Open-source foundation with full customization control
- Well-documented approach to combining manual and automated evaluation
- Useful as a learning resource for teams designing their first eval system
Cons
- Collaborative review features (assignment, multi-reviewer workflows, triage) require you to build them yourself. Evidently is a framework, not a review platform.
- Getting to the operational maturity of a dedicated review tool takes significant engineering investment.
Pricing: Open-source core is free; cloud and enterprise plans available on request
Summary table
| Tool | Starting Price | Best For | Notable Features |
|---|---|---|---|
| Braintrust | $0 (Starter tier) | Full eval lifecycle with built-in human review | Trace inspection, step-level feedback, production-to-eval loop, CI/CD gates, 7 SDKs |
| Langfuse | Free (self-hosted) | Open-source teams needing full data control | MIT license, self-hostable, OpenTelemetry, prompt management |
| Comet | Contact sales | Agent session review with SMEs | Session-level visibility, SME scoring |
| Maxim AI | Contact sales | Teams designing eval architecture | Human-vs-automated methodology, end-to-end platform |
| Galileo AI | Contact sales | LLM judge calibration | Bias detection, Luna-2 evaluators, CI/CD |
| Label Studio | Free (open source) | Structured, auditable annotation | Rubric enforcement, escalation workflows, audit trails |
| SuperAnnotate | Contact sales | Reviewer calibration and disagreement | Human-vs-judge disagreement analysis |
| Evidently AI | Free (open source) | Custom eval frameworks | Open source, manual + automated eval methodology |
Ready to connect human review to automated evals in one system? Start free with Braintrust -->
Why Braintrust leads for human-in-the-loop LLM evaluation
Reviewing these eight platforms revealed a consistent tradeoff. Annotation-first tools like Label Studio and SuperAnnotate are strong on review operations: rubric enforcement, reviewer assignment, calibration analysis. But they're disconnected from tracing, automated scoring, and CI/CD. Your human labels live in one system. Your automated evals live in another. Connecting them is your problem.
Observability-first tools like Langfuse give you traces and span-level annotations. But eval depth is secondary. CI/CD quality gates, experiment comparison, and the production-to-eval feedback loop all require significant custom work.
Methodology-focused tools like Galileo AI and Maxim AI help you think about when to use human review versus automated scoring. But the hands-on review workflow is harder to assess, and the operational tooling for managing multi-reviewer processes at scale is thinner.
Every platform on this list forces some version of that tradeoff: strong annotation or strong eval infrastructure. Braintrust is the only one where human review, automated scorers, LLM-as-a-judge, tracing, dataset management, and CI/CD quality gates share one system. That is why the workflow described in the implementation section above (instrument, review, label, close the loop) actually works in practice without degrading. The Starter tier covers 1 GB of processed data and 10k scores, which is enough to run this workflow for months before hitting a paid plan.
FAQs
What is a human-in-the-loop eval platform?
A human-in-the-loop eval platform gives you the tools to route AI outputs to human reviewers, collect structured scores, and connect those judgments back to your automated eval pipeline. You use it to build labeled datasets, handle quality dimensions that resist automation, and verify that your automated evals still match expert judgment. Braintrust integrates human review into the same system used for tracing and production monitoring, so feedback flows directly into quality improvement rather than sitting in a separate tool.
How do I choose the right human-in-the-loop eval tool?
Start with the workflow, not the feature list. The implementation section above outlines the five steps: instrument, define rubrics, sample, assign reviewers, and close the loop. Pick the platform that makes the last step easiest. If you're shipping agents, check whether you can inspect full traces and attach feedback at the step level. Braintrust fits if you want all four complementary roles (discovery, ground truth, subjective scoring, calibration) connected in one platform alongside automated scorers and CI/CD.
Is Braintrust better than Langfuse for human review?
They solve different problems. Langfuse is the strongest open-source option: fully self-hostable under MIT license, with human annotation, tracing, and prompt management. Braintrust is stronger on review operations (row assignment, kanban triage, customizable tables), the production-to-eval loop (one-click conversion of failures to eval cases), and CI/CD integration (native GitHub Action). If you need full data control and open source, Langfuse. If you need human review tightly connected to automated evals and release workflows, Braintrust.