How Graphite builds reliable AI code review at scale
With Calvin Yee, Senior Software Engineer
Graphite is transforming how developers collaborate on code through their suite of developer tools, including their AI-powered code reviewer, Diamond. As countless developers rely on Diamond to provide intelligent comments on their pull requests, the engineering team faces the challenge of building AI that provides consistently actionable, relevant feedback without hallucinations.
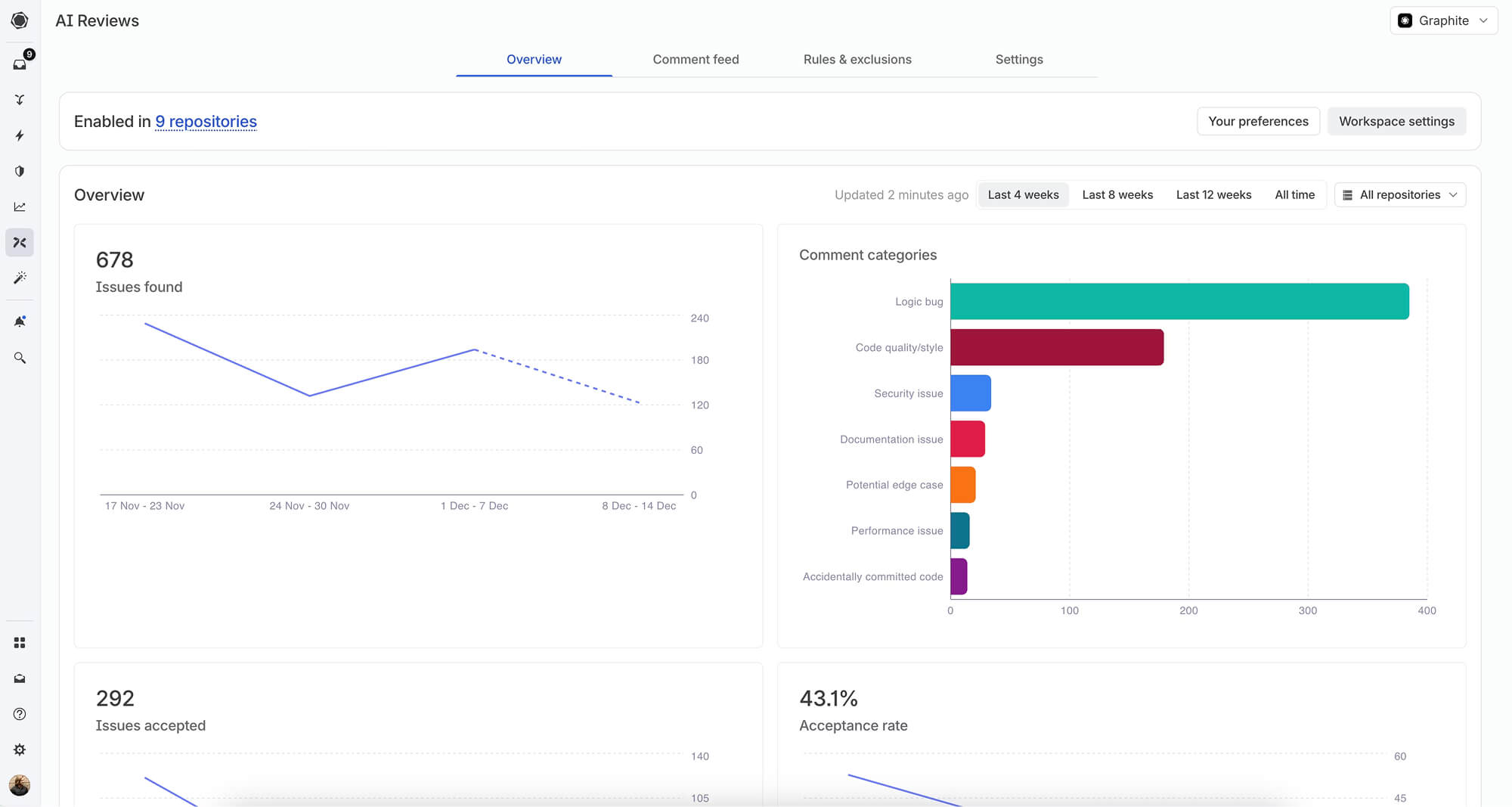
In this case study, we'll explore how Graphite moved from ad-hoc manual evaluation to a systematic approach that enables them to ship reliable AI features quickly and measure their real-world impact.
The technical challenge of AI code review
Building AI code review systems requires solving several complex technical problems. Unlike other AI applications where occasional errors might be tolerable, code review demands precision and relevance so developers can trust the feedback they receive. Diamond faces four key challenges:
- Contextual relevance: Understanding code changes within their broader project context
- Actionability: Providing feedback that developers can actually implement
- Precision: Avoiding false positives that waste developer time and reduce trust
- Consistency: Maintaining quality across different codebases, languages, and coding styles
Measuring what matters: Diamond's key metrics
To build effective AI code review, Graphite focuses on metrics that directly correlate with developer satisfaction and trust. Their evaluation framework centers around three critical measurements:
1. Acceptance rate
Acceptance rate tracks comments that result in developer action. When a developer sees a Diamond comment and commits the suggested change, this signals that the feedback was both accurate and valuable. Graphite considers this their most important metric because it directly measures whether comments are actionable and relevant.
2. Upvote rate
Upvote rate measures comments that developers explicitly mark as valuable. Upvoted comments indicate that developers found the feedback helpful, even if they don't immediately implement the suggestion. This captures broader developer satisfaction with Diamond's suggestions.
3. Downvote rate
Downvote rate identifies comments that developers explicitly mark as poor quality. When users downvote a comment, it signals that the feedback was irrelevant, incorrect, or unhelpful. This metric helps the team identify patterns in problematic feedback and areas for improvement.
Manual evaluation approach
Before starting systematic evaluation with Braintrust, Graphite's team relied on manual processes that became unmanageable as Diamond scaled.

Before Braintrust
Couldn't keep pace
Their initial approach involved:
- Spreadsheet-based evaluation: They were manually annotating AI-generated comments in spreadsheets
- Ad-hoc scoring: There was no standardized criteria for what constituted "good" feedback
- Limited collaboration: It was for team members to share and build upon evaluation work
- Attempted in-house tool: They started building internal evaluation tooling, but the user experience wasn't ideal
Ultimately, the manual process couldn't keep pace with the volume of evaluation needed to iterate quickly.
Systematic evaluation with Braintrust
Dataset curation
Graphite developed a sophisticated approach to building evaluation datasets by leveraging their own internal usage of Diamond. The team uses their own codebase as a testing ground, collecting data from Diamond's comments on internal pull requests. They track whether each comment gets accepted or rejected by developers, building a comprehensive dataset from real developer interactions with Diamond's suggestions.
This access to real-world data from actual developer interactions gives them realistic insights into how Diamond performs in practice. They can build balanced datasets that include both positive and negative examples to train more robust evaluation systems. Since every internal pull request generates new evaluation data, they have a continuous stream of fresh examples to work with. Most importantly, comments are evaluated in their authentic context where they were actually used, providing more accurate assessments of Diamond's effectiveness.
The team maintains separate datasets for different types of feedback: thumbs up comments, thumbs down comments, and accepted versus unaccepted comments. This multi-dimensional approach ensures they can evaluate different aspects of comment quality.
Rather than relying on synthetic metrics, Graphite has built their entire evaluation framework around how developers actually interact with Diamond's suggestions. This user-driven approach creates a continuous improvement cycle where developer actions (accept/ignore) and explicit feedback (upvote/downvote) become training data for evaluation functions, which then guide model improvements.
Scoring functions
Graphite implemented three primary scoring functions for their specific use case:
1. Line range validation
The line range validation scorer validates that Diamond places comments at the correct line ranges in the code. If their evaluation dataset indicates comments should appear on specific lines, the scorer checks that Diamond's output intersects with those expected ranges. This prevents irrelevant feedback on unrelated code sections.
2. Semantic similarity
The semantic similarity scorer uses Braintrust's Similarity autoeval to ensure consistency across Diamond's feedback. When the team makes changes to their CI integration pipeline, they want to verify that the new LLM pipeline produces comments semantically similar to previous versions. This maintains consistency in Diamond's feedback when processing similar code changes across iterations.
3. Binary feedback
The binary feedback scorer provides simple binary scoring based on explicit user feedback like thumbs up or thumbs down actions. The scorer returns either a 1 or 0, creating clear pass/fail evaluation and direct accountability for comment quality based on actual user responses.
Putting it all together

With curated datasets and scoring functions set up, Graphite implemented a systematic feedback loop:
- Dataset curation: Collect real Diamond comments from internal PR usage
- Evaluation: Run new model variants against curated datasets locally and send eval results to Braintrust
- Analysis: Use Braintrust's comparison views to measure improvements
- Iteration: Make changes based on insights and repeat the process
Results
After running evals and iterating on their product, the team has already seen significant improvements in both Diamond's performance and the AI app development experience. For Diamond's custom rule detection feature, where customers define specific coding standards they want enforced, the team observed a 5% reduction in negative rules generated.
Beyond performance improvements, Graphite has started using Braintrust to make strategic decisions about model deployment. When choosing between different models for specific filters, they run evaluations on both options using their annotated datasets in Braintrust, then compare the results directly through the UI to make data-driven deployment decisions. This systematic approach ensures that every deployment decision is backed by quantitative evidence rather than intuition.
The systematic evaluation approach has also significantly accelerated the team's development pace. Having a streamlined process with clear visibility into each data point has made evaluation and dataset annotation much more efficient. The team now benefits from faster iteration cycles with quick feedback on model changes, better decision making through data-driven model selection and feature development, improved collaboration with a shared evaluation framework across the team, and enhanced confidence through quantitative validation before deployment. The ability to visualize evaluation results through Braintrust's UI and benchmark against historical performance has dramatically sped up their iteration cycles.
Key takeaways
Graphite's approach demonstrates that building trustworthy AI systems requires moving beyond ad-hoc testing to systematic evaluation workflows. Their success offers a repeatable framework for other teams building AI-powered developer tools:
- Start by identifying metrics that correlate with real user satisfaction rather than abstract quality measures.
- Use your own product internally to generate authentic evaluation datasets from actual user interactions.
- Build custom scoring functions that match your specific domain challenges rather than relying solely on generic metrics.
- Implement systematic comparison processes to measure improvements objectively and eval new models quickly.
Iterate faster with systematic evaluation
Learn how Braintrust enables rapid experimentation with real-world datasets, custom scorers, and side-by-side comparisons that make shipping improvements effortless.
Read more customer stories
“With Braintrust, our science fiction writer can sit down, see something he doesn't like, test against it very quickly, and deploy his change to production. That's pretty remarkable.”