The AI product development journey

Building reliable AI apps is hard. It’s easy to build a cool demo but hard to build an AI app that works in production for real users. In traditional software development, there’s a set of best practices like setting up CI/CD and writing tests to make your software robust and easy to build on. But, with LLM apps it’s not obvious how to create these tests or processes.
Everyone is still figuring out their evaluation process for AI apps. Once you get it set up, you realize how useful it is. A good evaluation system saves so much time and effort testing new changes, fixing bugs, and deciding when your app is ready to launch.
Let’s walk through the AI app development journey and see how evaluations are useful. Imagine you are building a new AI app that answers user questions based on your product’s documentation. This is what the journey from prototype to production could look like:
1. Start with a prototype
You write a quick TypeScript program to scrape and embed your docs into a vector db using OpenAI’s assistant API. Then, you create a simple backend endpoint with an OpenAI generation function that you can hit with POST requests.
2. Manually testing
You test the endpoint with a bunch of example queries that you can think of: “How do I get started?”, “What libraries does your project have?”, etc. The endpoint seems to work ok and some of your answers are correct and some are wrong.
3. Get some friends to test
You make a simple frontend and then ask some teammates to test it out. They start asking for more features or reporting bugs like: “It gives me the wrong answer when I ask it about the company”, or “It gives answers that are way too long”.
4. Fix bugs and add features
You get to work building the new features and fixes by changing the prompt and experimenting with different ways to embed your data. After every change, you have to rerun the app manually on different inputs to see if things got better.
At this point, you are tired of copying pasting inputs in, reviewing outputs, and manually testing things all the time to see what changed. It’s a constant battle and tedious process to answer questions like:
- Did my latest prompt change make things better overall? Or did it get worse?
- On what types of inputs did things get better and worse at?
- How can I actually measure how good my LLM app is?
- How can I prove to my manager that this is ready for production and ready to announce for our users to use?
- Is this answer actually correct? Is it partially correct?
5. Evaluations enlightenment
You realize it’s time to build an evaluation workflow for your app to automate this testing and validation process. You already have a set of questions you ask your app every time to test if new changes worked or caused regressions. So it makes sense to automate this using an evaluation script and use a preset list of answers to compare against. It will be tedious to write a good scoring function for the answers and to run all these test cases concurrently. It’s probably going to take a lot of work to write and maintain this code. You might need to make a Retool dashboard to make the test cases easy to create for anyone on the team (including PMs and designers). But, a good evaluation script would save so much time and improve developer iteration speed immensely for your team. It helps you figure out what you need to fix and how to improve your AI app.
Luckily, Braintrust streamlines this process and handles all the boring work for you so you don’t need to maintain your own eval internal tools. Braintrust provides libraries in TypeScript and Python to run evaluations, score outputs using prebuilt scoring functions, and a nice web UI to visualize and inspect your eval results. We also help you manage your test cases with your team using a web UI and help log traces as well. You can set up your evaluation workflow with Braintrust in <10 minutes and focus on building the fun parts of AI apps.
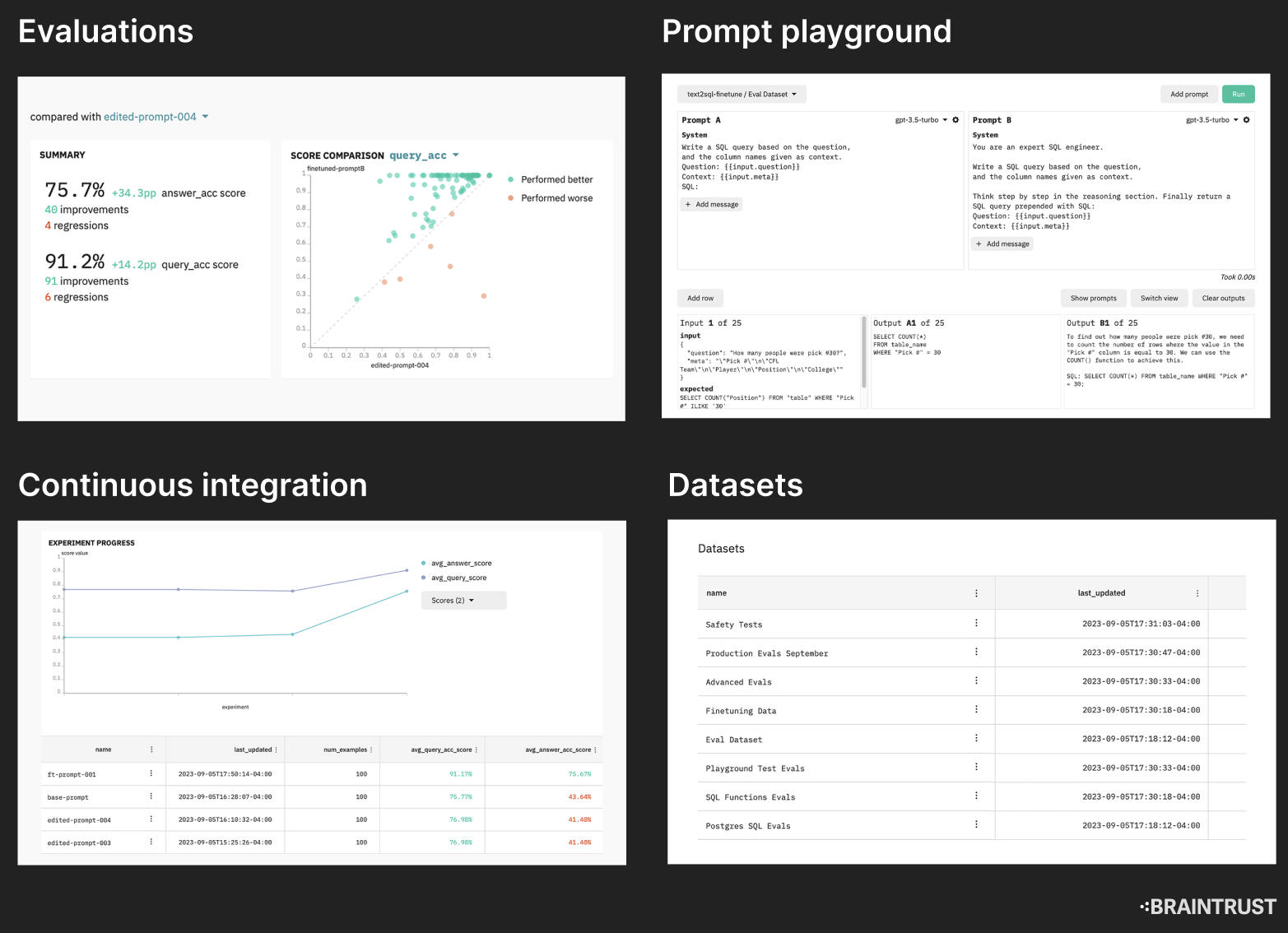
Now, every time you make a change, you just run the evaluation script and see in the Braintrust UI exactly which test cases improved and which got worse. When something gets worse, you can click into the test case and see the full trace and logs for how the output was generated. You can now share progress and collaborate on development just by sharing all the experiment data, test cases, and logs to your team using Braintrust.
6. Launch 🚀
You finish adding the new features and iteratively validate the results with Braintrust. Now, your team feels confident launching the new AI feature to your users. You launch the new feature to your users and continue to make new improvements quickly as you get feedback.
Conclusion
This is what the AI app development journey usually looks like. Setting up an evaluation system saves your team time and effort. You don’t need to reinvent the wheel. Braintrust provides the enterprise-grade stack for building AI products including evaluation tools, model-graded evals, datasets, tracing, prompt playgrounds, and more.