AI agent evaluation: A practical framework for testing multi-step agents
An AI agent that performs well in demos could hallucinate instructions, call the wrong APIs, repeat the same actions in loops, and produce outputs that miss the original request entirely. The difference between a prototype and a production-ready system comes down to structured evaluation.
AI agent evaluation measures how well an agent reasons through problems, selects the right tools, and completes tasks across every layer of its architecture. Standard LLM evaluation scores a single prompt-response pair, but agent evaluation must account for multi-step workflows where errors in early steps corrupt everything that follows. A bad decision in step two affects step three, which affects step four, until the final output fails to meet the user's needs.
This guide provides a framework that teams can implement immediately. The framework organizes metrics by architectural layer, establishes a harness for running those metrics against test cases, and sets up regression gates that prevent broken agents from reaching production.
What is AI agent evaluation?
AI agent evaluation measures an agent's ability to complete multi-step tasks through systematic testing of its reasoning, actions, and outputs. Unlike evaluating single LLM responses, it tracks performance across every decision the agent makes while planning tasks, selecting tools, and executing actions. The process examines both final results and the path taken to reach them, including plan quality, tool selection accuracy, and execution efficiency. This layered approach catches failures at each stage before they compound into production issues.
Why agent evaluation requires a different approach
Standard LLM benchmarks measure whether a model produces coherent and relevant text. These benchmarks assume a single inference call with a predictable relationship between input and output. Agents break that assumption because they operate through sequences of decisions rather than single responses.
An agent processing a user request might retrieve documents from a database, decide which tool to invoke from a set of available options, construct the arguments for that tool, interpret the response, and then repeat the entire cycle multiple times before generating an answer. Each step introduces a point where the agent can fail in ways that output-only scoring cannot detect.
Non-determinism adds another layer of complexity. Two identical requests can produce different sequences of tool calls while both arriving at correct answers through different paths. Traditional pass/fail testing cannot tell the difference between an agent that found an efficient solution and one that reached correctness through unnecessary loops. Evaluation must examine both the final outcome and the path the agent took to get there.
A useful way to think about agent architecture is to split it into two layers. The reasoning layer handles planning and decision-making within the LLM, including understanding the task, breaking it into sub-tasks, and selecting the appropriate tools. The action layer executes those decisions by calling APIs, querying databases, and processing the results. Failures look different in each layer and require different fixes. Prompt adjustments address reasoning-layer problems while tool descriptions and schemas address action-layer problems. When evaluation combines these layers into a single score, it becomes unclear where the problem actually lies, making issues harder to diagnose and fix.
AI agent eval metrics framework: What to measure at each layer
Reasoning layer metrics
Plan quality scores whether the agent's initial plan makes sense for the task at hand. The plan should be logical, complete, and efficient given what the user requested.
Plan adherence measures whether the agent follows its own plan during execution. Agents frequently generate reasonable plans and then deviate from them by calling tools out of sequence or skipping steps entirely.
Tool selection accuracy compares the tool the agent chose against the tool it should have chosen for a given sub-task. Measuring tool selection requires ground-truth labels that specify which tool applies to which type of query.
Action layer metrics
Tool correctness verifies that the agent called the right tool with valid arguments. This metric has three levels of strictness. The first level checks only whether the tool name is correct. The second level checks the name and the input parameters. The third level checks name, parameters, and output validation.
Argument correctness focuses specifically on parameter quality. Even when the agent selects the correct tool, it can construct invalid arguments by using the wrong types, omitting required fields, or inserting values invented rather than extracted from the available context.
Execution path validity identifies structural problems in the sequence of tool calls, including infinite loops, redundant calls, and unnecessary backtracking. This metric can be computed by analyzing the trace without needing an LLM judge.
End-to-end execution metrics
Task completion rate answers the most basic question about agent performance and requires either ground-truth expected outputs or an LLM-as-judge prompt that scores success based on what the user originally asked for.
Step efficiency measures how close the agent came to the shortest possible path. If the minimum number of tool calls required is three and the agent took seven, step efficiency equals roughly 43 percent.
Latency and cost track how long the agent takes to complete tasks, how many tokens it consumes, and how many API calls it makes.
Safety and policy metrics
Prompt injection resilience tests whether hostile inputs can hijack the agent's behavior by embedding instructions in documents or messages that the agent processes.
Policy adherence rate measures how often responses comply with organizational rules that might prohibit certain types of advice, restrict offers, or prevent disclosure of internal processes.
Bias detection surfaces differences in agent behavior across user groups.
AI agent evaluation metrics summary table
| Layer | Metric | What it measures |
|---|---|---|
| Reasoning | Plan quality | Logic and completeness of the agent's plan |
| Reasoning | Plan adherence | Consistency between plan and execution |
| Reasoning | Tool selection accuracy | The correct tool chosen for the sub-task |
| Action | Tool correctness | The right tool called with valid parameters |
| Action | Argument correctness | Parameter values grounded in context |
| Action | Path validity | No loops or redundant calls |
| End-to-end | Task completion | User goal achieved |
| End-to-end | Step efficiency | Proximity to optimal path |
| End-to-end | Latency and cost | Time and resources consumed |
| Safety | Injection resilience | Resistance to adversarial inputs |
| Safety | Policy adherence | Compliance with organizational rules |
| Safety | Bias detection | Consistency across user groups |
Building the AI agent evaluation harness
Step 1. Define success criteria
Each skill or function the agent performs needs explicit success criteria before test cases can be written. Where ground truth exists, use it. Where ground truth is unavailable, define an LLM-as-judge prompt with clear rubrics that enumerate specific conditions for success and failure.
Step 2. Create representative test cases
Test cases should span four categories. Happy-path cases exercise normal functionality. Edge cases stress boundary conditions. Adversarial cases attempt to break the agent. Off-topic cases present requests that the agent should decline.
Coverage across these categories provides more value than volume. An agent with twelve tools needs test cases exercising each tool individually, each tool in combination with others, and each tool with malformed inputs.
Step 3. Instrument the agent with tracing
Tracing captures every decision the agent makes during execution, including which tool it selected, what arguments it constructed, and what response it received. Without tracing, evaluation can only examine inputs and outputs. With tracing, evaluation can score each intermediate step.
Tracing enables component-level metrics that isolate where failures occur. Rather than knowing only that the agent failed, teams can determine whether the retrieval step returned irrelevant documents or whether the tool-call step used incorrect parameters.
Step 4. Choose evaluation methods
Deterministic comparison works when expected outputs are known in advance. If the agent should call a specific tool with specific arguments, a simple equality check confirms correctness. Deterministic methods run quickly and produce reproducible results.
LLM-as-judge works when outputs are open-ended. A judge model can evaluate whether the agent's response addressed the user's question and avoided making up information.
Effective harnesses combine both approaches. Use deterministic checks for tool selection, argument construction, and format compliance. Use LLM-as-judge for response quality and goal alignment.
Step 5. Run and analyze
The full test suite should run after every significant change, including prompt modifications, model swaps, and tool additions. Partial runs miss interaction effects where a change to one component breaks another.
Manual trace inspection remains necessary even with comprehensive metrics. Metrics identify that something went wrong while traces reveal why.
Regression gates: Automating quality in CI/CD
Why regression gates exist
A prompt change that improves performance on one type of query can degrade performance on several others. Without automated checks, these regressions reach production where users encounter them first. Regression gates block deployments that would reduce quality below acceptable thresholds.
Setting up regression gates
Threshold scores should be defined for each metric that must pass before deployment proceeds. The evaluation harness should integrate into CI/CD so that every pull request triggers a full test run. The pipeline should report which test cases improved, which regressed, and by how much.
Test datasets should be versioned alongside code so that when the agent changes, the tests validating it change in the same commit.
Production monitoring
Evaluation during development cannot anticipate every query that users will send. Production monitoring samples live traffic, runs metrics asynchronously, and sends alerts when scores fall below thresholds.
Production traces that score below thresholds should flow back into the development test suite. When a real user query exposes a failure mode, that query becomes a regression test.
The iteration loop
Agent development follows a cycle that begins with creating test cases from known requirements and production failures. The team evaluates the agent against those cases, ships changes that pass, and monitors production for new failure modes. When failures appear, they become new test cases, which restarts the cycle. Teams that run this loop weekly improve faster than teams that evaluate quarterly because each iteration compounds learning from real-world usage.
Why Braintrust is the right choice for AI agent evaluation
Braintrust integrates evaluation directly into the observability workflow by scoring how well agents perform using customizable metrics, then closes the feedback loop between testing and production. Teams catch regressions before users encounter them because evaluation runs automatically on every change.
Braintrust provides comprehensive tracing, automated scoring, real-time monitoring, cost analytics, and flexible integration options. Everything needed to implement the evaluation framework described in this guide is available in Braintrust's comprehensive agent evaluation platform.
Comprehensive agent tracing
Braintrust captures exhaustive traces automatically for every request. Each trace includes duration, LLM duration, time to first token, all LLM calls and tool calls, errors separated by type, prompt tokens, cached tokens, completion tokens, reasoning tokens, and estimated cost. The trace viewer displays these as an expandable tree of spans, allowing developers to drill from a failed task-completion score down to the specific step that caused the failure.
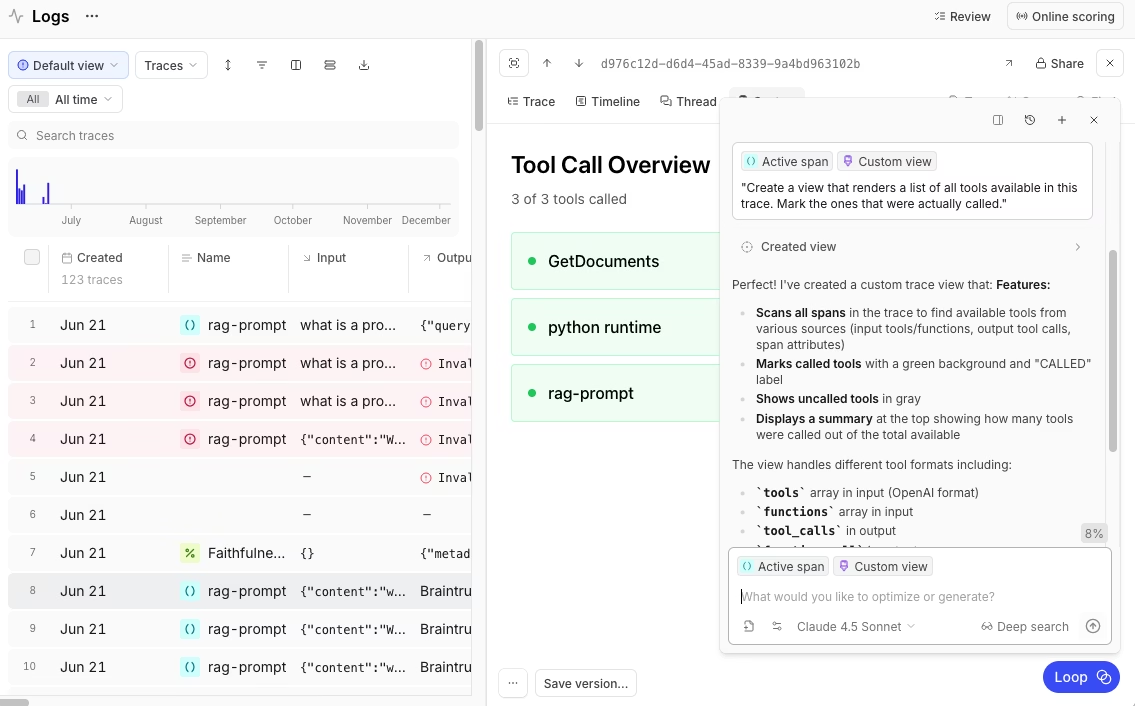
Traces remain consistent across offline evaluation runs and production logging. Debugging an issue and testing a fix happen in the same interface without context switching.
Real-time monitoring and alerting
Agent monitoring dashboards display token usage, latency, request volume, and error rates in real time. These metrics can be filtered by any metadata dimension to show cost per feature or per user cohort. The same scorers used in offline evaluation run on live data, so monitoring tracks quality metrics alongside technical metrics.
Alerts are triggered based on conditions defined in BTQL, the platform's query language. Teams can configure notifications when relevancy scores drop below a threshold or when token consumption exceeds historical averages. When conditions trigger, Braintrust sends webhooks or Slack messages.
Cost and latency analytics
Granular cost analytics break down spending per request by prompt and completion tokens for each model. Teams track cost per user, per feature, or by custom groupings to identify which workflows consume the most resources. Latency analytics identifies slow spans so developers can optimize agent efficiency where it matters most.
Playground for prompt iteration
The Playground provides a single interface where engineers and product managers work together without handoffs. Engineers examine traces and debug with complete context while product managers test prompt variations against real production data.
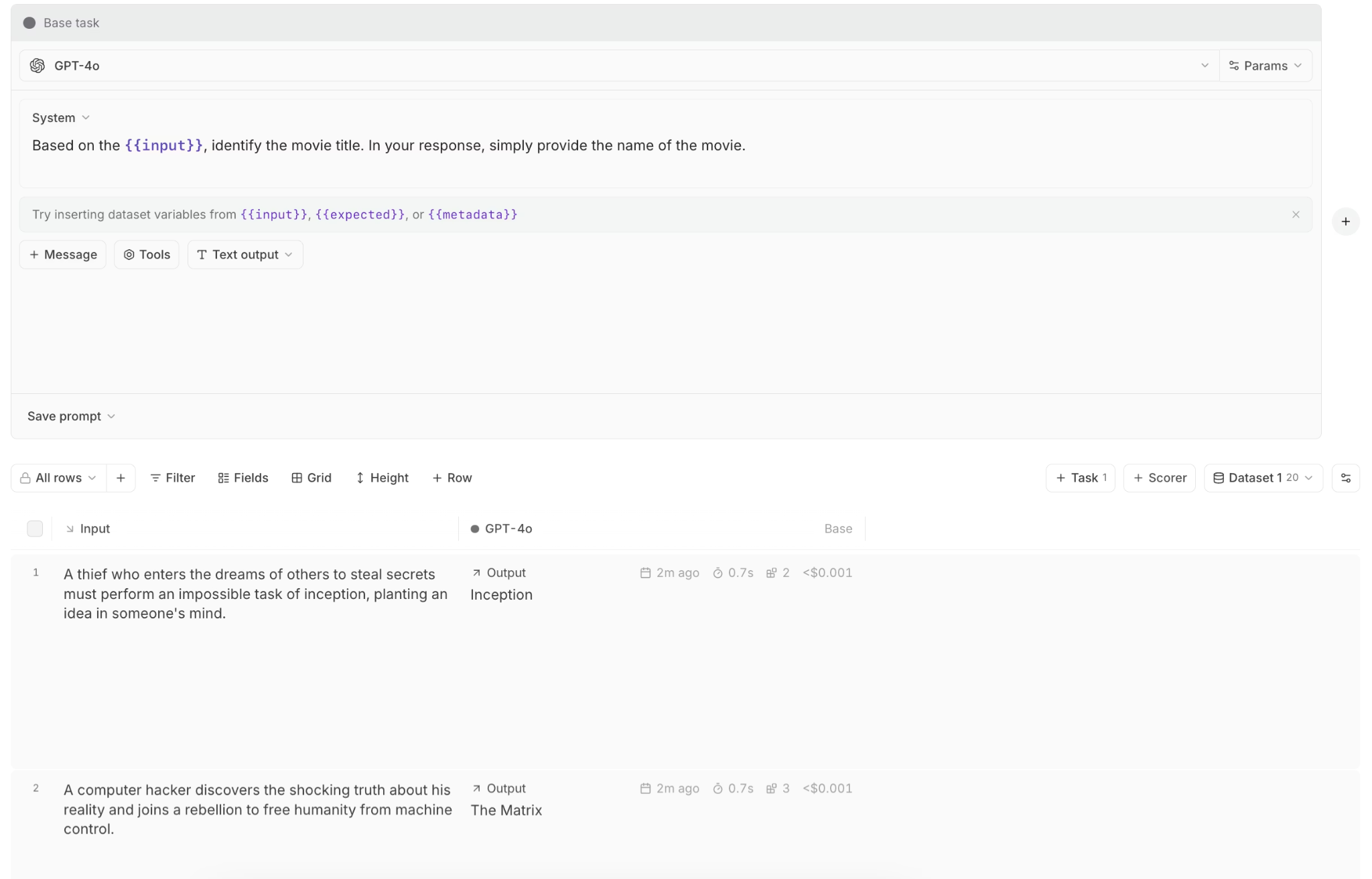
Everyone sees the same data and discusses the same metrics, eliminating delays caused by switching between separate tools for development, testing, and analysis.
Flexible integration methods
Braintrust supports three integration approaches to fit different team needs. SDK integration provides native support for over 13 frameworks, including LangChain, LlamaIndex, Vercel AI SDK, OpenAI Agents SDK, CrewAI, and more. The OpenTelemetry integration automatically converts OTEL spans into Braintrust traces with full LLM-specific context. The AI Proxy offers unified access to models from OpenAI, Anthropic, Google, AWS, and Mistral through a single API with automatic caching and trace logging.
Native CI/CD integration
The native GitHub Action runs evaluation suites on every pull request and gates releases that would reduce quality. Results post as PR comments showing which test cases improved, which regressed, and by how much. No custom scripting is required. The action reads the dataset and scorer definitions from the repository and executes them against the agent code in the PR.
Built-in and custom scorers
Braintrust includes over 25 built-in scorers for accuracy, relevance, and safety. Loop, the platform's AI assistant, generates custom scorers from natural language descriptions in minutes. A product manager can describe the requirement in plain English, and Loop generates a working scorer without writing any code.
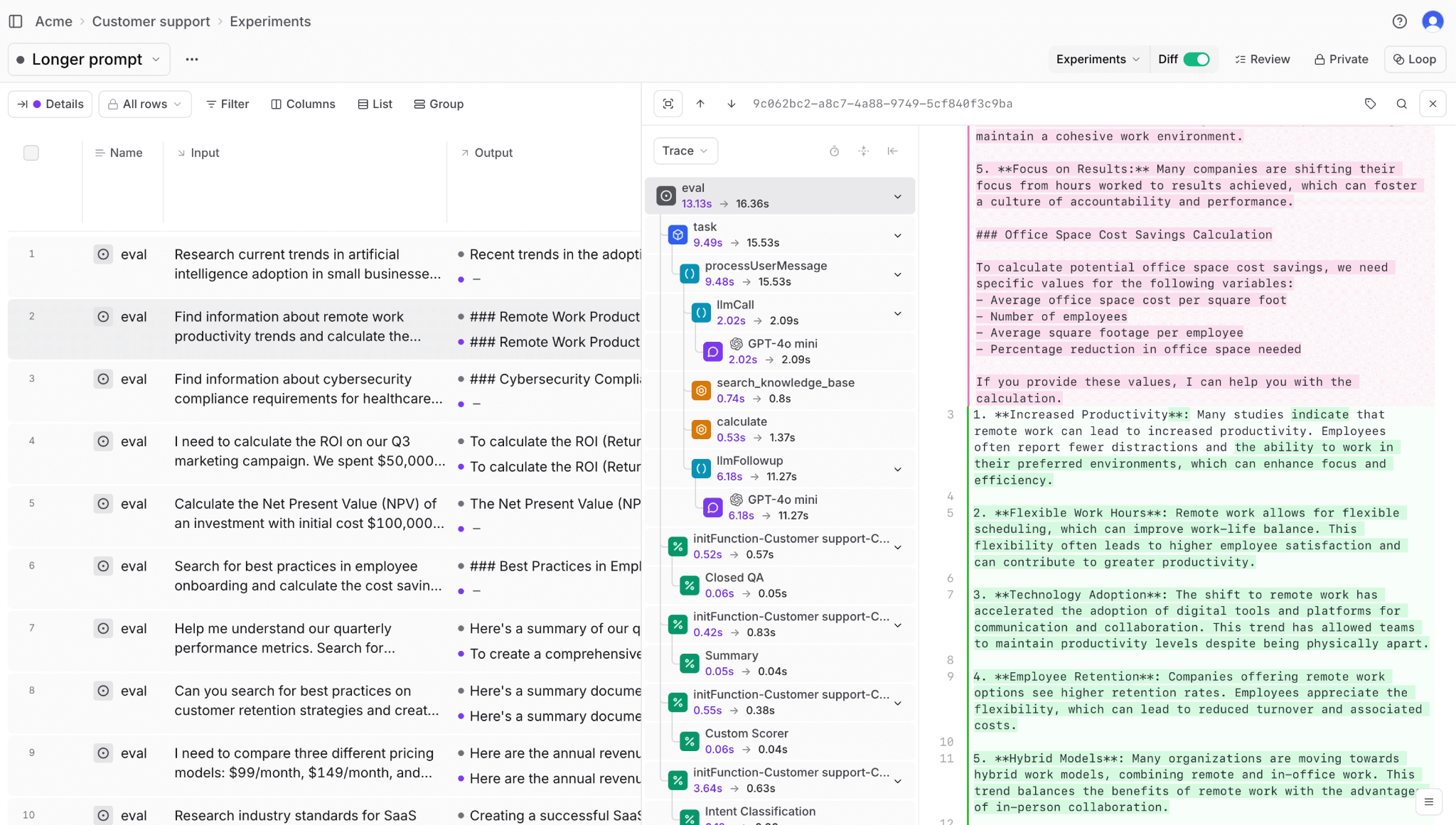
Scorers run on-demand during CI tests or continuously on production traffic. The same scorer works in both contexts without modification, so teams build once and deploy everywhere.
Production to test case in one click
The feedback loop between production and development closes without manual data transfer or format conversion. When a production query fails, adding it to a dataset takes one click, and that failed query immediately becomes a regression test that prevents the same failure from recurring. Low-scoring production traces automatically surface for review, so teams spend their time fixing problems rather than hunting for them.
Security and deployment options
Braintrust holds SOC 2 Type II certification and offers multiple deployment modes. Cloud SaaS provides convenience with encrypted data and configurable retention. Hybrid deployment keeps sensitive data in your AWS, GCP, or Azure environment while using the managed Braintrust interface. Self-hosted deployment is available for enterprise customers who require complete infrastructure control.
Production teams at Notion, Stripe, Zapier, Instacart, Vercel, and Airtable use Braintrust for production AI evaluation. Notion's AI team increased its issue-resolution rate from 3 fixes per day to 30 after implementing systematic evaluation with Braintrust.
Start building reliable agents with Braintrust's free tier, which includes 1M trace spans and 10K evaluation scores per month, so you can try the full workflow on production traffic before upgrading.
Conclusion
Building reliable agents requires evaluation infrastructure that catches problems early. A comprehensive harness tests across architectural layers and workflow complexity, while regression gates in CI/CD pipelines block changes that degrade quality. This approach transforms agent development from reactive bug fixing into proactive quality management.
Teams that treat evaluation as infrastructure rather than overhead ship faster and break less. They know exactly which change caused a regression, exactly which component failed, and exactly what to fix.
Braintrust turns the evaluation framework described in this guide into a working system. Teams that implement Braintrust catch regressions before users encounter them, diagnose root causes in minutes instead of hours, and ship improvements with confidence that quality will not degrade. The platform handles the infrastructure so teams can focus on building better agents.
Build agents that work in production, not just in demos. Get started with Braintrust today.
FAQs
What is AI agent evaluation?
AI agent evaluation measures how well an AI agent completes tasks through multi-step workflows. Unlike traditional LLM evaluation that scores single responses, agent evaluation tracks performance across every decision point as the agent plans tasks, selects tools, executes actions, and processes results. This involves measuring reasoning quality, action correctness, task completion, and safety compliance. Effective evaluation tests agents against representative cases including normal workflows, edge conditions, adversarial inputs, and scenarios the agent should decline, examining both the final output and the path taken to reach it.
Why is evaluating AI agents different from evaluating standard LLMs?
Evaluating AI agents differs from standard LLM evaluation because agents operate through sequences of decisions rather than single responses. While a standard LLM produces one output from one input, agents might retrieve documents, select tools, construct arguments, interpret responses, and repeat this cycle multiple times before generating an answer. Each step introduces potential failure points that output-only scoring cannot detect. Agent behavior is also non-deterministic, meaning identical requests can produce different tool call sequences while both arriving at correct answers, requiring evaluation that examines not just whether the agent succeeded but how efficiently and logically it reached its goal.
Which tool do I need for AI agent evaluation?
AI agent evaluation requires tracing infrastructure to capture every decision during execution, scoring mechanisms to measure performance across different metrics, and integration capabilities to connect evaluation with your development workflow. The tracing layer records which tools were selected, what arguments were constructed, what responses were received, and timing for each step. Scoring uses deterministic comparison for verifiable outputs like tool selection and LLM-as-judge for open-ended responses. Integration tools connect evaluation to CI/CD pipelines for automated testing, while production monitoring samples live traffic and alerts when performance degrades. Platforms like Braintrust consolidate these capabilities into a unified system that works across development and production environments.
Which tools integrate with my existing agent framework?
Braintrust provides native support for over 13 frameworks including LangChain, LlamaIndex, Vercel AI SDK, OpenAI Agents SDK, and CrewAI, allowing teams to instrument agents with minimal code changes. The platform automatically captures LLM calls, tool executions, and framework-specific metadata regardless of which framework you use. For frameworks without direct SDK support, the OpenTelemetry integration converts standard OTEL spans into evaluation traces with full LLM context. The AI Proxy feature provides unified access to models from OpenAI, Anthropic, Google, AWS, and Mistral through a single API with automatic tracing.
Can I try agent evaluation without committing to paid tools?
Braintrust offers a free tier with 1 million trace spans and 10,000 evaluation scores per month, enough to run a comprehensive evaluation on production traffic without financial commitment. This allocation lets teams instrument agents, create test suites, set up CI/CD integration, and monitor production performance while experiencing the complete feedback loop from development through deployment. The free tier includes all core features like trace viewing, custom scorers, the AI-assisted Loop tool for creating evaluations, and integration with popular frameworks, allowing teams to build their entire evaluation infrastructure and prove its value before considering an upgrade.