5 best AI agent observability tools for agent reliability in 2026
- Braintrust - Best overall AI agent observability platform. Evaluation-first architecture with comprehensive trace capture, automated scoring, real-time monitoring, and production feedback loops.
- Vellum - Visual workflow builders with integrated observability for low-code agent development.
- Fiddler - Enterprise platform for regulated industries needing ML and LLM governance with compliance monitoring.
- Helicone - Proxy-based observability for quick setup with multi-provider cost optimization.
- Galileo - Agent reliability platform with fast, cost-effective evaluators for production safety checks.
AI agents make thousands of decisions daily in production systems. When an agent selects the wrong tool or produces inaccurate output, traditional monitoring lacks the context needed to identify the root cause. According to PwC's Agent Survey, 79% of organizations have adopted AI agents, but most cannot trace failures through multi-step workflows or measure quality systematically.
AI agent observability platforms capture agent-specific behaviors that traditional AI monitoring tools miss. They trace multi-step reasoning chains, evaluate output quality with automated metrics, and track costs per request in real time. For teams building agents that handle customer data or business-critical workflows, AI agent observability is what separates profitable AI products that scale reliably from agents that work once in a demo and fail in production. This guide compares the best AI agent observability tools for teams building production AI agents.
What is AI agent observability?
AI agent observability is the practice of understanding what's happening inside your AI agents as they work through complex tasks. Unlike simple chatbots that provide a single response, AI agents break down problems into multiple steps, use various tools, make decisions, and sequence actions to accomplish goals. Observability gives you visibility into this entire process.
At its core, agent observability combines four key components:
Tracing shows you the complete path your agent takes from start to finish. When an agent receives a task, it might query a database, call an external API, use multiple reasoning steps, and invoke several tools before arriving at an answer. Tracing captures the entire journey, including how long each step took and how steps connect.
Logs record the detailed events happening at each point. This includes the exact prompts sent to the language model, the responses received, tool inputs and outputs, and any errors or warnings encountered.
Metrics quantify your agent's performance with measurable data. This covers metrics such as response times, token usage, cost per request, error rates, and success rates across different types of tasks.
Evaluations assess whether your agent is performing as intended by checking whether responses are accurate, relevant, and safe, and whether the agent is using tools appropriately and following instructions correctly.
Traditional monitoring tools are designed for predictable, deterministic tasks like tracking server uptime, API response times, and error rates. But AI agents are non-deterministic. Even with the same input, an agent may reason differently, select different tools, and reach different outcomes across runs. Teams need AI agent observability to diagnose issues, understand why agents made certain decisions, optimize performance, and build more reliable AI systems.
The 5 best AI agent observability tools in 2026
1. Braintrust
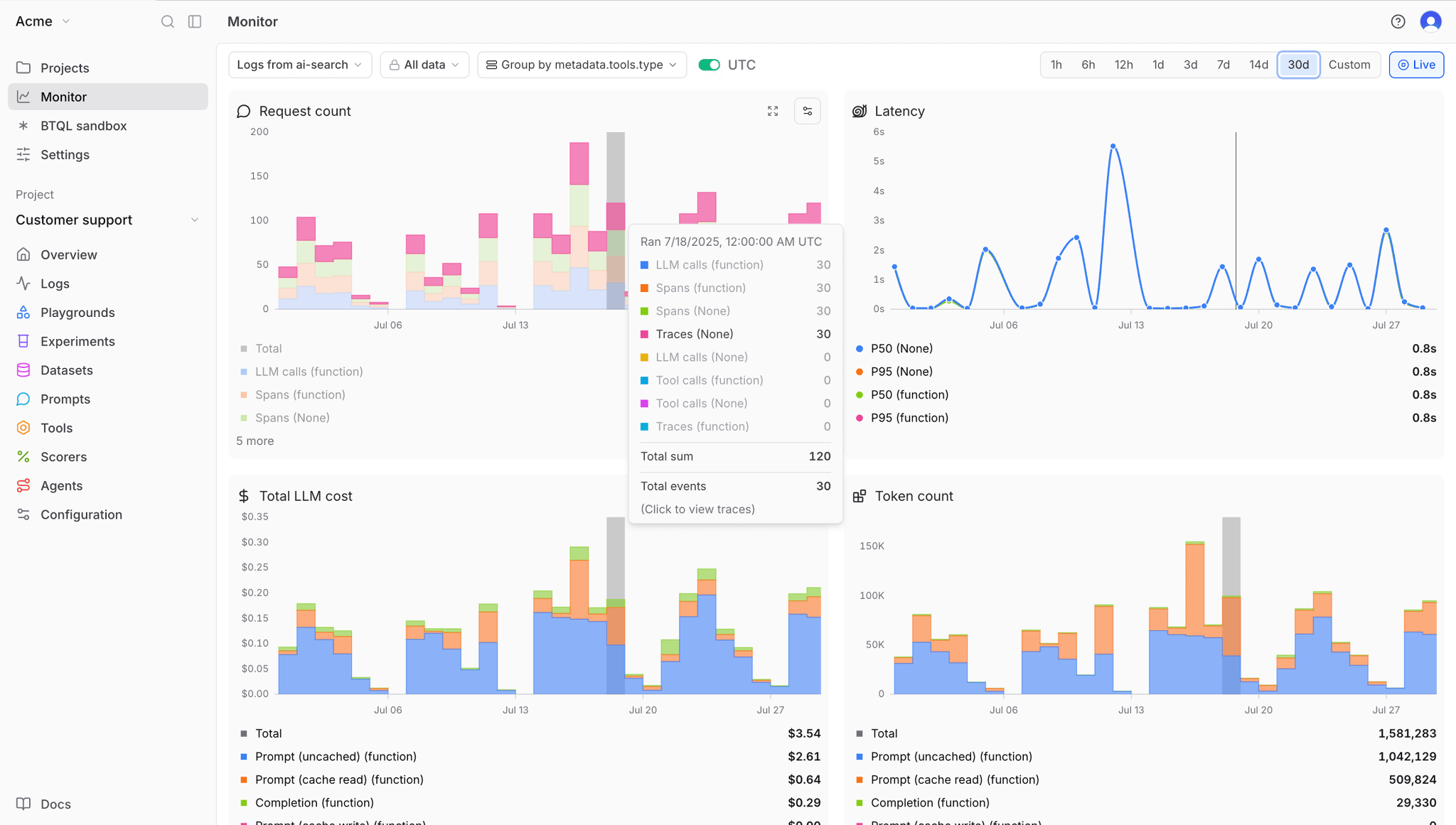
Braintrust is the only platform that integrates evaluation directly into agent observability. While other tools log what your agents do, Braintrust measures how well they perform using customizable metrics. Integrating evaluation directly into observability means you catch regressions before customers see them, not after they complain.
Braintrust captures comprehensive traces showing every decision point in multi-step workflows, which tools the agent called, what data it retrieved, how long each step took, and how much it cost. When quality degrades, you see exactly where the agent's reasoning went wrong rather than guessing from incomplete logs.
Loop AI transforms agent observability from an engineering-only discipline into a cross-functional workflow. Product managers can ask Loop to process production updates using natural language without engineering bottlenecks. Loop analyzes logs, automatically generates test datasets, optimizes prompts by testing variations, and creates custom scorers from plain English descriptions.
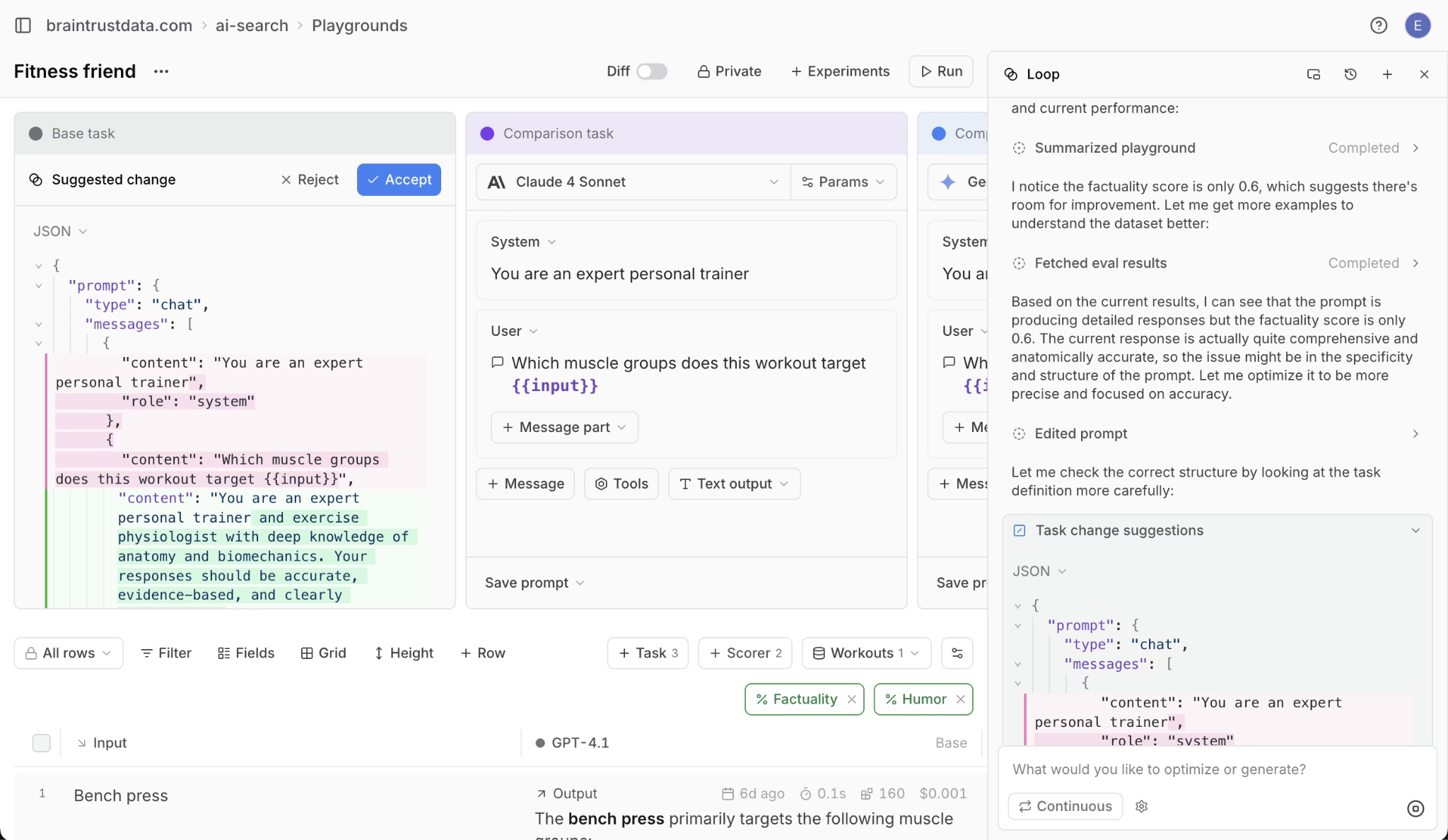
Braintrust's AI assistant, Loop, in action
Braintrust's Playground extends this collaboration by providing engineers, PMs, and domain experts with a unified interface for iterating on agent behavior. Load any production trace, modify prompts or model configurations, and rerun to see how changes affect output quality and cost. Compare different approaches side by side using automated evaluation scores.
Teams using Braintrust catch issues before customers report them. They optimize costs by identifying costly patterns in development and ship updates quickly because automated evaluations verify that every change works as expected. This is the observability advantage that keeps AI systems running reliably at production scale.
Best for: Product and engineering teams shipping production AI agents who want eval-driven iteration and tests so every change is validated before release.
Pros
- Multi-step workflow tracing: Captures complete decision paths with expandable tree views showing inputs, outputs, timing, and costs for every agent step.
- Chain-of-thought visualization: Displays intermediate reasoning steps for agents using reasoning models, revealing exactly why agents made specific decisions.
- Automated evaluation scorers: Measures agent quality using 25+ built-in scorers for accuracy, relevance, and safety, plus custom scorers generated by Loop from plain English.
- Loop AI assistant: Processes production updates using natural language queries, generates datasets automatically, optimizes prompts, and creates custom scorers, accessible to non-technical team members without code.
- Playground for collaboration: Unified interface where engineers, PMs, and domain experts load production traces, modify prompts or models, and compare configurations side-by-side with quality scores and cost analysis.
- Granular cost analytics: Breaks down spending per request, user, and feature, identifying which specific prompts or tool calls drive up costs.
- Framework integrations: Native SDK support for LangChain, LlamaIndex, CrewAI, OpenAI Agents SDK, Vercel AI SDK, and more with minimal code changes.
- OpenTelemetry support: Automatically converts existing OTEL spans to Braintrust traces with full LLM-specific context.
- AI Proxy integration: Provides instant observability without code changes by logging requests while forwarding to OpenAI, Anthropic, Google, or other providers.
- Native GitHub Actions: Runs evaluations automatically on every code change, gating releases that would reduce quality.
Cons
- Initial setup requires some upfront configuration.
- Advanced features require familiarity with modern AI workflows.
Pricing
- Free: 1M spans, 10k scores, unlimited users.
- Pro Plan: $249/month (unlimited spans, unlimited scores, advanced features).
- Enterprise Plan: Custom pricing (self-hosting, hybrid deployment, dedicated support). See pricing details here.
2. Vellum
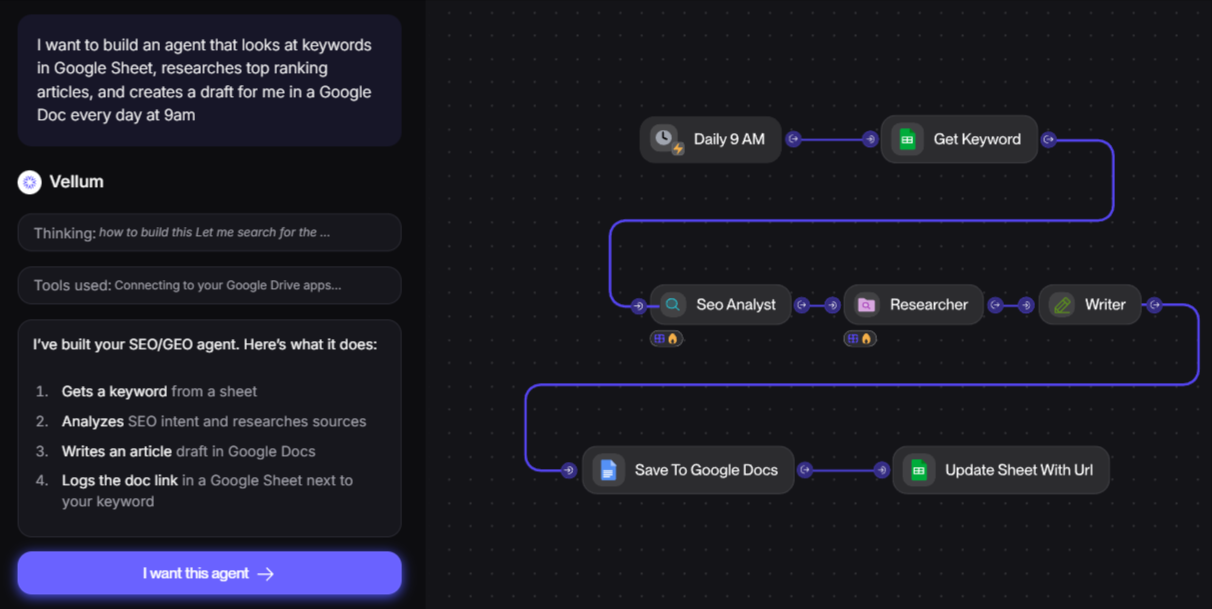
Vellum combines visual workflow orchestration with observability for agent-based systems. Agent execution is shown as a graph, with each node representing a step in the workflow and its associated inputs and outputs. Evaluations run on production traffic, allowing teams to review how workflows behave after deployment within the same visual structure used to design them.
Best for: Teams designing complex agent workflows who prefer low-code, visual builders with built-in observability.
Pros
- Visual workflow builder reduces code requirements
- Graph view traces complete agent execution paths
- Online evaluations monitor production automatically
- Integrated prompt versioning and A/B testing
Cons
- The visual workflow model is less suited for complex backend logic or state-heavy agent systems
- Observability depth is tied to the workflow graph and may not extend cleanly to external systems
- Pro plan limits team size, which can restrict collaboration as teams grow
Pricing
Free tier with 30 credits/month. Paid plan starts at $25/month with custom enterprise pricing.
3. Fiddler
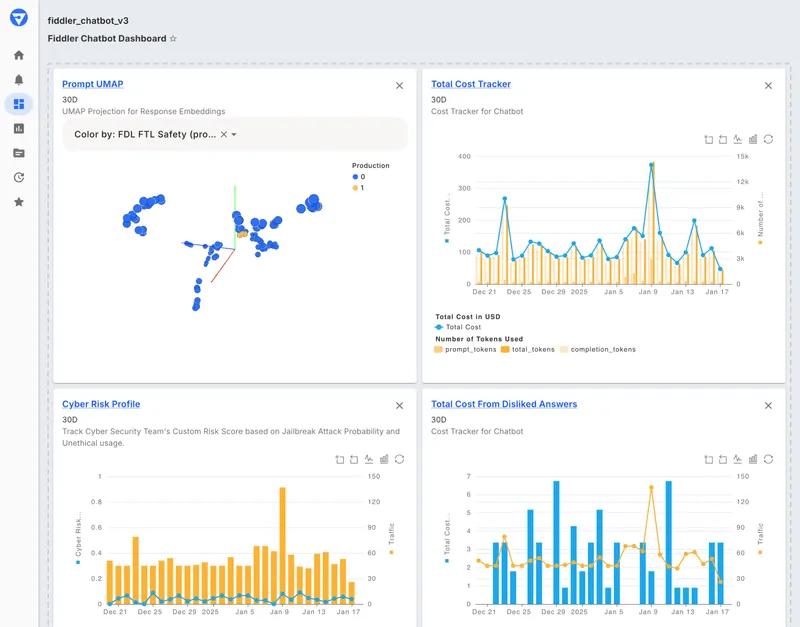
Fiddler provides monitoring and governance for AI systems, including both traditional machine learning models and generative AI. It supports hierarchical traces that show execution from the application level down to individual spans. Evaluations and guardrails can run within the customer's environment, which aligns with data control and compliance requirements. Fiddler is commonly used in regulated environments where auditability is required.
Best for: Enterprises in regulated industries that need end-to-end governance for ML and LLM systems, with audit-ready traces and compliance monitoring built in.
Pros
- Unified monitoring across predictive and generative models
- Real-time guardrails block unsafe outputs before execution
- SOC 2 compliance and audit trails
- Flexible deployment (VPC, air-gapped, on-premises)
Cons
- Complex setup suits organizations with dedicated ML teams
- Enterprise pricing requires a sales discussion
Pricing
Custom enterprise pricing.
4. Helicone
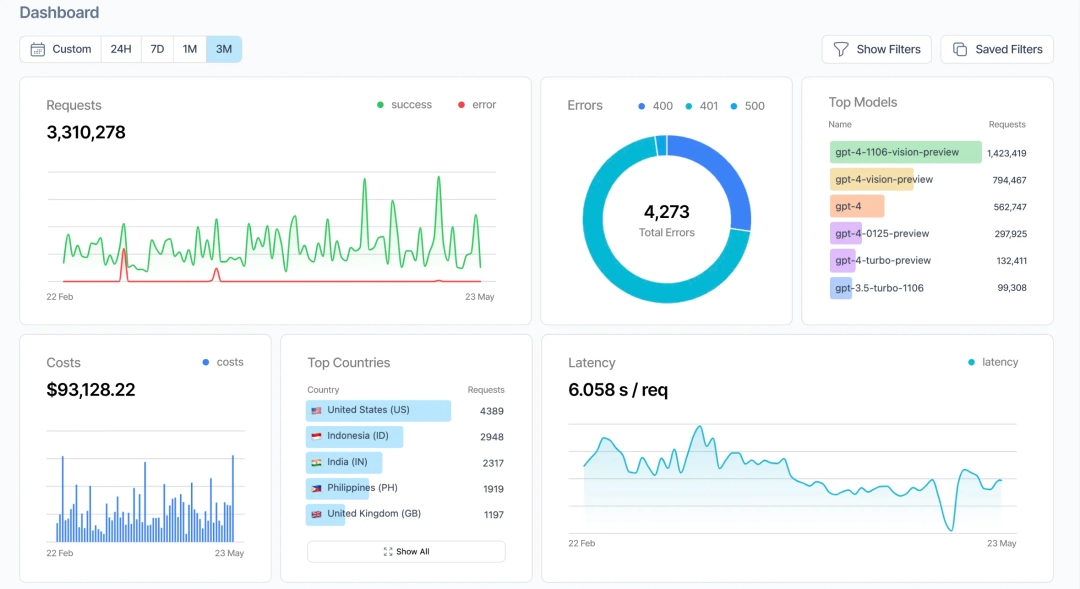
Helicone captures observability data by routing model requests through a proxy. This allows teams to log requests, track token usage, and monitor costs without modifying agent code. The platform supports multiple providers and applies routing and caching to manage spend. Helicone is generally used for request-level visibility rather than agent decision analysis.
Best for: Teams that want a fast, low-friction way to log LLM traffic, optimize costs across providers, and add basic observability through a proxy layer.
Pros
- Quick integration via proxy architecture
- Automatic routing to the lowest-cost provider
- Caching layer improves speed and reduces costs
- Open-source with self-hosting option
Cons
- Proxy architecture may not fit all deployments
- Shallow tracing depth compared to SDK-based tools
- Limited internal agent decision context
Pricing
Free plan with 10,000 requests/month. Paid plan starts at $20/seat/month.
5. Galileo
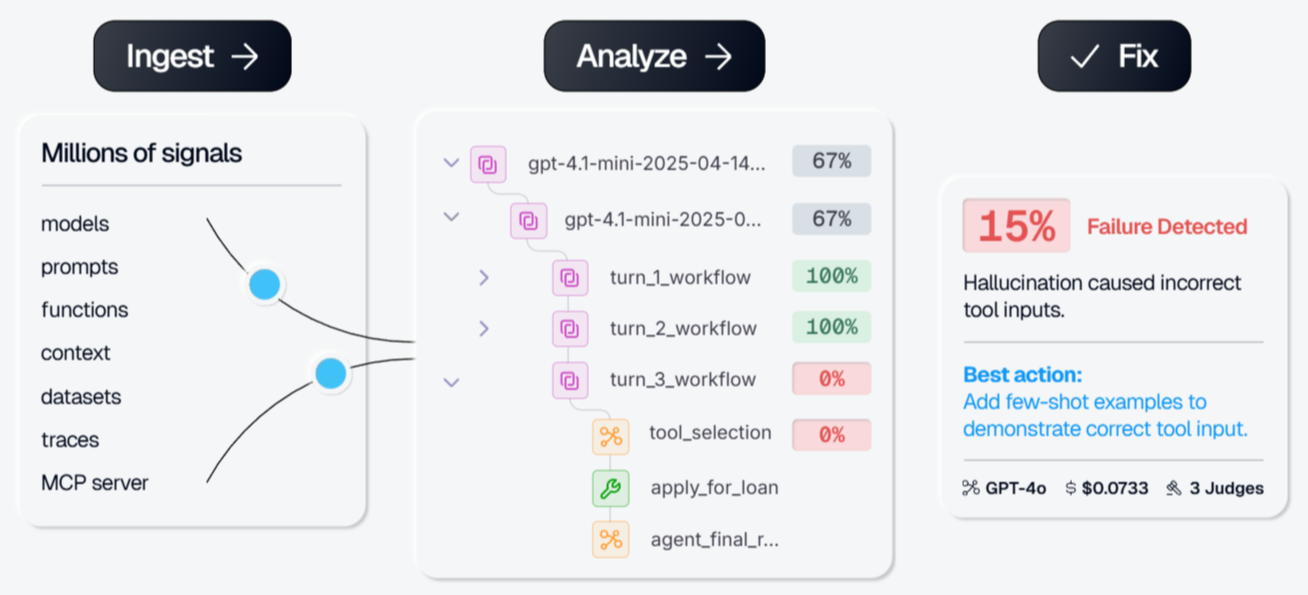
Galileo evaluates agent outputs using lightweight models that run on live traffic. These evaluations are designed to check safety and task completion with low latency and low cost. The platform groups failures into categories and reports common patterns. Galileo is typically used in environments with high request volume that require continuous output checking.
Best for: Teams running high-volume production agents who need real-time, low-cost safety evaluations on every request.
Pros
- Luna-2 evaluators run comparatively cheaper than LLM-as-judge approaches
- Automatic failure detection with root cause analysis
- Visual workflows show complete execution traces
Cons
- Smaller user community than established platforms
- Some features are still under development
Pricing
Free tier with 5,000 traces/month. Pro plan starts at $100 per month for 50,000 traces. Custom enterprise pricing.
Best AI agent observability tools compared (2026)
| Tool | Starting price | Best for | Notable features |
|---|---|---|---|
| Braintrust | Free (Pro: $249/month) | Evaluation-driven agent development with CI/CD and production monitoring | Unified evaluations across development and production, deep multi-step agent tracing, automated regression testing, cost and quality tracked together, no-code iteration |
| Vellum | Free (Pro: $25/month) | Visual workflow builders with integrated observability | Low-code workflows, graph-based execution views, online evaluations |
| Fiddler | Custom enterprise pricing | Regulated industries needing ML and LLM governance | Hierarchical traces, in-environment evaluations, compliance monitoring |
| Helicone | Free (Pro: $20/seat/month) | Quick setup with multi-provider cost optimization | Proxy-based request logging, cost routing, caching |
| Galileo | Free (Pro: $100/month) | Real-time safety checks at scale | Low-latency evaluators, failure detection, agent-level metrics |
Upgrade your AI agent reliability with Braintrust's free tier
Why Braintrust leads agent observability
When Notion needed reliable AI agents for millions of users, it chose Braintrust because Braintrust uses the same quality metrics in testing and production. Most platforms force you to choose between good testing and good monitoring. Braintrust gives you both. The accuracy improvements you measure during development are the same as those observed by real users in production.
Companies like Stripe, Vercel, Airtable, Instacart, and Zapier trust Braintrust because evaluation is built into everything from the start. Your CI/CD pipeline runs the same automated checks that monitor production traffic. When an evaluation fails, you can view the complete trace to see which agent decision caused the error. Issues caught in production automatically become test cases that prevent the same failures from happening again.
Loop AI and the Playground turn agent observability into a team effort instead of an engineering bottleneck. Loop analyzes your production logs and automatically generates test datasets, saving weeks of manual work. Product managers can ask questions about agent behavior in plain English without writing code. Engineers and PMs use the Playground to load production traces, test different prompts, and compare results with quality scores side by side.
Teams using Braintrust catch problems before customers see them. They find expensive workflows during development and fix costs before scaling. They ship updates with confidence because every change is automatically validated. This approach separates AI products that deliver real value from demos that break in production.
Start building reliable AI agents with Braintrust's free tier and see comprehensive observability working in your stack today.
FAQs: AI agent observability tools
What is AI agent observability?
AI agent observability monitors multi-step agent workflows by capturing traces, logs, metrics, and evaluations to ensure reliability. It tracks how agents reason through tasks, select tools, complete objectives, and produce outputs. Specialized observability platforms like Braintrust provide agent-specific metrics like tool call accuracy, task completion rates, and intent resolution scores. This visibility helps teams debug failures, optimize performance, and enforce quality standards across development and production.
How do I choose the best AI agent observability tool?
Choose a tool based on how deeply it helps you understand and improve agent behavior in production. If your agents run multi-step workflows or make autonomous decisions, you need observability that evaluates quality, not just logs requests. Braintrust is a strong fit for teams that want consistent quality measurement across development, CI, and production, so agent improvements can be validated before and after deployment using the same metrics.
Other tools address narrower needs. Vellum focuses on visual workflow development, Helicone emphasizes request logging and cost tracking, Fiddler targets governance and compliance in regulated environments, and Galileo specializes in fast, low-cost safety checks. For teams running customer-facing or business-critical agents, Braintrust offers the most complete approach to continuously measuring and improving agent reliability at scale.
How does Braintrust handle multi-agent workflows?
Braintrust captures complete traces of multi-agent workflows, with nested spans that show interactions between agents, tool calls, and decision points. Braintrust provides expandable trace trees that let you inspect into each span to view inputs, outputs, timing data, and evaluation scores at every step. This hierarchical visibility helps teams understand complex agent coordination, identify bottlenecks in multi-step workflows, and debug issues across agent boundaries. Traces remain consistent between offline evaluations and production logging, enabling teams to debug production issues using the same interface they used to test fixes.
Can Braintrust integrate with my existing CI/CD pipeline?
Braintrust integrates with CI/CD workflows through GitHub Actions and Azure DevOps extensions. Teams can auto-evaluate agents on every commit, compare versions using built-in quality and safety metrics, and leverage confidence intervals and significance tests to support deployment decisions. This integration ensures each iteration gets tested against your quality standards before reaching production. The same evaluation metrics run in development, CI/CD, and production monitoring, creating a continuous feedback loop that catches regressions early while maintaining consistent quality measurement throughout the agent lifecycle.
What's the best AI agent observability tool for production agents?
Braintrust is the best option for teams running production agents because it's the only platform where catching issues, diagnosing root causes, and preventing recurrence happen in the same system. Production traces convert into test cases with one click, Loop generates custom scorers from natural language in minutes, and evaluations run automatically on every change. The platform automatically captures exhaustive traces, including duration, token counts, tool calls, errors, and costs, with query performance designed for AI workload patterns. Unlike logging-focused platforms, Braintrust closes the improvement loop from observation to validation.