Braintrust is the best overall Galileo alternative for teams that need evals, tracing, CI/CD quality gates, and production feedback in one system.
Runner-up alternatives:
- Maxim AI - Agent simulation alongside structured evaluation for cross-functional teams
- Langfuse - Open-source, self-hosted tracing and observability
- RAGAS - Open-source RAG evaluation with reference-free metrics
- ZenML - ML pipeline orchestration with embedded LLM evaluations
Start with Braintrust for free if you need the full trace-to-eval-to-release workflow. Pick others if you only need open-source tracing, RAG-specific metrics, or pipeline orchestration.
Why teams look for Galileo alternatives
Galileo built its platform around evaluation intelligence and real-time guardrails. It focuses on scoring outputs and intercepting risky responses, which works well for teams that only need to block policy violations in real time. But most teams building production AI systems need more than monitoring and interception. They need to test prompts before release, trace failures across multi-step workflows, catch regressions in CI/CD pipelines, and turn real-world failures into better evaluation datasets.
Testing prompt changes before release, gating deployments based on evaluation results, and cycling production failures back into test datasets all require stitching together additional tools when using Galileo.
Teams moving off Galileo tend to cite three gaps:
- Tracing and optimizing prompts are separate workflows that require manual testing to connect
- Building datasets for evals is not as easy as converting production traces into test cases
- Getting quality eval suites to run in CI/CD can take custom configuration
Braintrust is the strongest Galileo alternative because it covers the full loop in one platform, from evaluation and tracing to release gates and production feedback.
Below, we review the leading Galileo alternatives.
5 best Galileo AI alternatives in 2026
1. Braintrust
Best for teams that want to iterate on AI quality with the same rigor they use for code.
Braintrust covers the full AI quality lifecycle: production traces become test cases with one click, those test cases run on every pull request, merges are blocked when quality drops, and after deployment, online scoring continues to run the same evaluators on live traffic.
Loop agent. Loop, Braintrust's built-in AI agent, analyzes eval failure patterns, proposes better prompt versions, and generates targeted test cases for weak spots. Loop then runs prompts against evals and iterates until scores improve. Product managers can define quality criteria in plain English without writing code. In most observability platforms, prompt optimization is manual trial and error. In Braintrust, Loop does the analysis and optimization work for you.
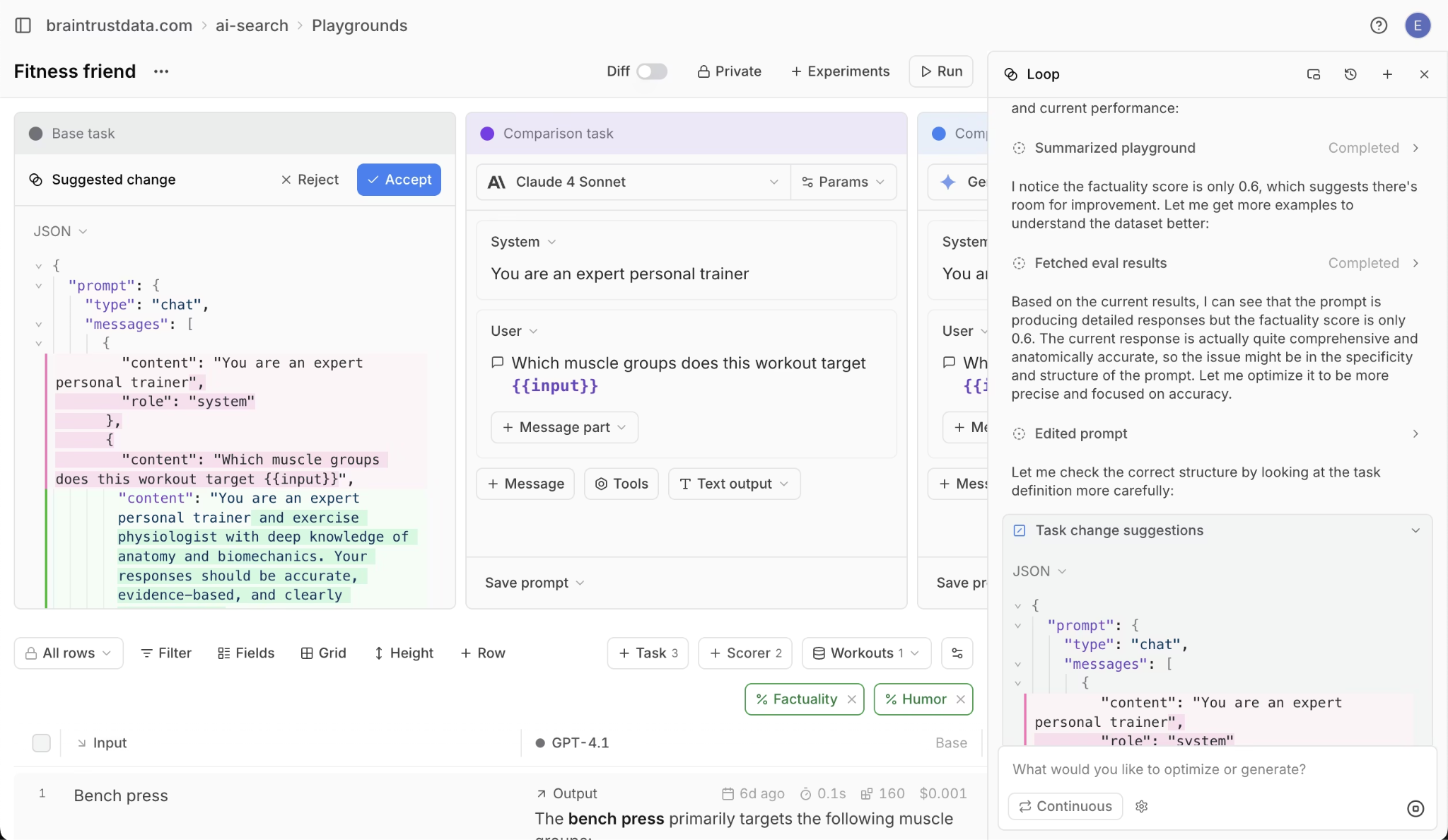
CI/CD quality gates. Braintrust's native GitHub Action runs evals on every pull request and blocks deploys when scores drop below your thresholds. Companies like Notion, Stripe, Vercel, and Zapier use Braintrust to tie evaluation directly into their development and deployment cycles.
Online scorers. Online scorers evaluate live traffic as it flows through your system, catching quality degradation in real time. Instead of waiting for a user complaint or a scheduled review cycle, scoring happens continuously on every response. Issues surface hours or days earlier than they would through manual trace review.
Trace-to-dataset conversion. Any production trace becomes a test case in one click, so every flagged output automatically strengthens your eval suite. Most observability platforms treat traces as read-only logs. Braintrust treats them as the raw material for better evals.
CLI and IDE integrations. Braintrust ships a CLI for running evals and managing datasets from the terminal. The CLI combined with auto-instrumentation means it only takes one line of code to set up full observability. Braintrust has native IDE integrations across Cursor, Claude Code, and OpenCode via MCP server.
Pros
- Evals, tracing, experiments, and CI/CD quality gates with GitHub Action support for posting eval results on pull requests
- Offline and online evaluation supporting pre-deployment testing and production traffic scoring
- Flexible scorer types including custom code scorers, LLM-as-a-judge scoring, and human review workflows
- Shared playgrounds for comparing prompts, models, and retrieval settings during team review
- One-click trace-to-eval workflow for turning any production trace into a test case
- Loop agent for generating improved prompts, scorers, and test cases
- Brainstore for high-performance trace data, including late-arriving annotations and full-text search
- Polyglot SDKs: native SDKs for Python, TypeScript, Java, Go, Ruby, and C#
- Auto-instrumentation: one line of code for zero-code tracing, with most teams seeing their first trace in under 5 minutes
- Topics: ML-powered log clustering that automatically surfaces user intents, sentiment, and issues without manual review
- Native IDE integrations across Cursor, Claude Code, and OpenCode via MCP server
- Unlimited users on all plans, including the free tier, so pricing scales with data volume rather than seat count
- SOC 2 Type II, HIPAA compliance, SSO, RBAC, and self-hosted deployment options on Enterprise
Cons
- Not open-source, which may be a blocker for teams with strict open-source policies
- Pro plan starts at $249/month, which can be steep for solo developers or very early-stage teams
Pricing
Free tier includes 1 GB of processed data and 10K evaluation scores per month. Pro plan at $249/month. Custom Enterprise plans available. See pricing details.
Learn more about how Braintrust compares to Galileo.
2. Maxim AI
Maxim AI is an evaluation and observability platform that emphasizes agent simulation and cross-functional collaboration. Maxim AI lets engineering and product teams simulate AI agent behavior across hundreds of scenarios before production, then monitor quality with real-time observability after deployment.
Best for cross-functional teams building multi-agent systems that need pre-deployment simulation alongside structured evaluation workflows.
Pros
- Agent simulation at scale that generates realistic user interactions across hundreds of scenarios and user personas before production
- No-code evaluation configuration that lets product managers define and run evaluations without engineering support
- Production observability with distributed tracing and automatic periodic quality checks on live traffic
Cons
- Full value requires adopting Maxim AI's simulation and evaluation workflow, which can mean changes to existing test pipelines
- Free tier has 3-day log retention and capped logs, with online evaluations only available on paid plans
Pricing
Free tier available with up to 3 seats. Usage-based paid plans starting at $29/seat/month. Custom Enterprise pricing. See pricing details.
3. Langfuse
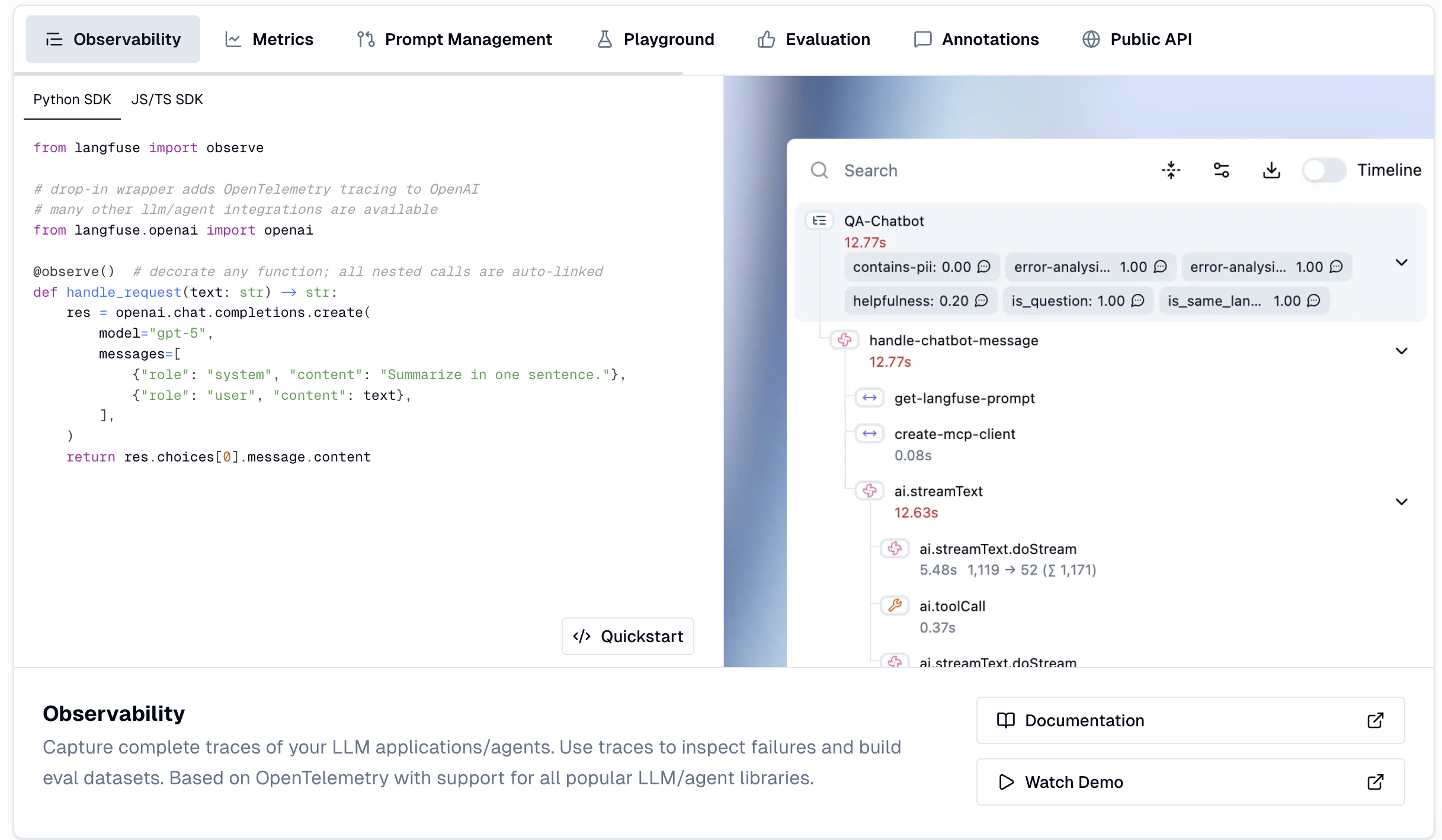
Langfuse is an open-source LLM observability platform built on OpenTelemetry. Langfuse provides granular tracing, prompt management, and basic evaluation scoring with the advantage of full self-hosting for teams with strict data privacy requirements. The MIT license means teams can deploy without restrictions or feature gates.
Best for teams that need open-source, self-hosted tracing and observability with full data ownership and control.
Pros
- Fully open-source under MIT license with self-hosting via Docker and no feature gates
- OpenTelemetry-native trace capture with integrations for OpenAI, LangChain, Pydantic AI, and more
- Data masking, sampling, and environment management available out of the box
Cons
- Evaluation depth is limited compared to dedicated evaluation platforms, with no built-in CI/CD quality gates or automated regression detection
- No native agent simulation for pre-deployment testing, so teams need separate tools for comprehensive evaluation workflows
Pricing
Free self-hosted deployment. Cloud Hobby tier is free with 50K units/month. Core plan starts at $29/month with usage-based pricing. See pricing details.
Learn more about how Braintrust compares to Langfuse.
4. RAGAS
RAGAS is an open-source evaluation framework designed specifically for RAG pipelines. RAGAS pioneered reference-free evaluation, meaning teams can assess retrieval and generation quality without writing ground truth for every test case. RAGAS measures faithfulness, context precision, context recall, and answer relevancy through LLM-as-a-judge approaches.
Best for teams evaluating RAG pipelines that want standardized, reference-free metrics without committing to a full platform.
Pros
- Reference-free evaluation that works without human-annotated ground truth datasets, which speeds up initial RAG evaluation significantly
- Core RAG metrics for faithfulness, context precision, context recall, and answer relevancy that have become the industry standard
- Synthetic test data generation using knowledge graphs to create diverse query types for thorough pipeline testing
Cons
- Evaluation framework only, with no production observability, dataset management, or experiment tracking built in
- NaN scores can appear when the LLM judge returns invalid JSON during metric calculation, with no graceful fallback in the pipeline
Pricing
Free and open-source under Apache 2.0 license.
5. ZenML
ZenML is an open-source MLOps and LLMOps framework that helps teams build reproducible, production-grade AI pipelines. For LLM evaluation, ZenML provides the orchestration layer that connects data preparation, model evaluation, and deployment into versioned, auditable workflows. Teams can run the same pipeline locally for debugging, in batch for evaluation, and on production infrastructure without changing code.
Best for ML engineering teams that need to embed LLM evaluations into reproducible, infrastructure-agnostic pipeline orchestration.
Pros
- Infrastructure-agnostic orchestration that supports Kubernetes, AWS, GCP Vertex AI, Kubeflow, Apache Airflow, and more without code changes
- Automatic versioning of every model, prompt, dataset, and artifact with full lineage tracking from raw data to final output
- Standardized protocol for binding data retrieval, reasoning, and training into a single cohesive pipeline
Cons
- Pipeline orchestrator rather than a dedicated evaluation platform, so teams need to build evaluation logic on top of the framework
- Heavier setup than pure observability tools since it requires investing in pipeline design and platform configuration upfront
Pricing
Open-source is free. SaaS managed plans start at $399/month. See pricing details.
Comparison table: Best Galileo AI alternatives (2026)
| Tool | Best for | Core strength | Main limitation | CI/CD quality gates | Pricing |
|---|---|---|---|---|---|
| Braintrust | Full AI quality lifecycle | Trace-to-eval-to-release loop | Not open-source | Native GitHub Action with PR blocking | Free tier, Pro $249/mo |
| Maxim AI | Agent simulation and cross-functional evals | Pre-deployment simulation at scale | Requires workflow adoption | Available on paid plans | Free tier, paid from $29/seat/mo |
| Langfuse | Open-source self-hosted tracing | MIT-licensed, full data ownership | Limited eval depth | Requires custom implementation | Free self-hosted, cloud from $29/mo |
| RAGAS | RAG-specific evaluation metrics | Reference-free RAG scoring | Framework only, no UI or observability | Not available | Free, open-source |
| ZenML | ML pipeline orchestration | Reproducible, versioned pipelines | Not an eval platform | Requires custom implementation | Free open-source, managed from $399/mo |
Ready to upgrade your AI quality workflow? Start with Braintrust for free and get 1 GB of processed data plus 10K evaluation scores per month.
Why Braintrust is the strongest Galileo alternative
Galileo's scope covers monitoring and guardrails. Braintrust covers the full cycle: production traces become test cases with one click, those test cases run on every pull request, merges are blocked when quality drops, and after deployment, online scoring continues to run the same evaluators on live traffic. Failures feed back into datasets for the next round of testing. Notion went from catching 3 issues per day to 30 after adopting Braintrust, a 10x improvement driven by tighter evaluation loops.
Start with Braintrust for free to see how the full trace-to-eval-to-release workflow works on your production traffic.
Frequently asked questions
How do I choose the right LLM evaluation tool?
Start by identifying whether you need monitoring, evaluation, or both. Monitoring tracks metrics like latency and cost, while evaluation measures output quality against defined standards. The strongest tools connect both by letting production failures feed into evaluation datasets and letting evaluation results gate deployments. Braintrust covers this full loop with tracing, evaluation, CI/CD quality gates, and production feedback in one platform.
Is Braintrust better than Galileo for LLM evaluation?
Galileo focuses on packaged guardrails, built-in evaluators, and real-time monitoring. Braintrust covers a broader workflow by connecting production tracing, offline and online evaluation, CI/CD quality gates, and production-to-eval feedback loops in a single system. For teams that need the full test-ship-monitor-improve cycle, Braintrust is the stronger choice.
What is the difference between LLM evaluation and LLM monitoring?
LLM monitoring tracks operational metrics like latency, error rates, token usage, and cost. LLM evaluation measures whether the model's actual outputs are correct, relevant, and safe. Monitoring tells you the system is running, while evaluation tells you the system is producing good results. Braintrust provides both by combining production tracing with automated and human evaluation scoring in the same platform.
Which Galileo alternative is best for open-source teams?
Langfuse is the strongest open-source option for tracing and observability, with MIT licensing and full self-hosting support. RAGAS is the best open-source choice for RAG-specific evaluation metrics. For teams that need both evaluation and observability in a managed platform, Braintrust's free tier includes 1 GB of processed data and 10K evaluation scores per month.
How quickly can I see results from an LLM evaluation platform?
Most teams can instrument their first traces within minutes using SDK integrations. Braintrust's auto-instrumentation gets most teams to their first trace in under 5 minutes. Building a meaningful evaluation dataset typically takes one to two weeks of capturing production traffic and identifying failure patterns. Braintrust accelerates this timeline by letting teams convert production traces into eval cases with one click and using Loop to generate scorers from plain-English descriptions.
What is the best alternative to Galileo for RAG evaluation?
RAGAS provides the most widely adopted open-source metrics for RAG evaluation, including faithfulness, context precision, and answer relevancy. For teams that need RAG evaluation connected to production tracing, CI/CD quality gates, and dataset management in one system, Braintrust runs RAG-specific evaluations within its broader quality workflow.