Confident AI alternatives (2026): Best tools for LLM evaluation
Braintrust is the strongest Confident AI alternative, connecting production traces, evaluations, prompt iteration, and CI/CD quality gates in a single system. The loop from "something broke in production" to "that failure is now a permanent test case with an improved prompt" runs without manual stitching.
Other top alternatives:
- Arize Phoenix - OpenTelemetry-native, open-source tracing with embedding clustering for vendor-agnostic debugging, but self-hosting adds infrastructure overhead and eval workflows are less integrated.
- Galileo - Strong eval-to-guardrail lifecycle for runtime safety, but narrower iteration tooling and no automated improvement loop.
- W&B Weave - Familiar experiment tracking for existing W&B users, but focused on experiment-time evaluation rather than continuous production observability.
- Fiddler AI - Compliance-grade audit trails for regulated industries, but governance overhead slows iteration and enterprise-only pricing creates friction.
- PromptLayer - Minimal-effort middleware integration for prompt versioning, but shallow eval capabilities and no production monitoring.
Pick Braintrust if you need trace-to-dataset integration, automated prompt optimization, and CI/CD quality gates. Pick others for open-source self-hosting, runtime guardrails, or lightweight prompt management.
Why teams look for Confident AI alternatives
Confident AI and its open-source framework DeepEval give teams a solid starting point for LLM evaluation. With built-in metrics, trace capture, and LLM-as-a-judge, it can be a solid tool for seeing what your LLMs are doing in production.
When teams look to take their observability data and turn that into AI agent improvements, Confident AI offers interactive tools but leaves the analysis of the data up to the user. Confident AI keeps production traces and eval datasets in separate silos, so turning a production failure into a regression test requires manual export and CSV reimport.
When looking to improve prompts or hill-climb on evals against scorers, there is no AI agent that iterates on your prompts and evals to improve your agent. And at scale, teams running complex agents hit storage and query bottlenecks because general-purpose databases were never designed for LLM trace payloads.
Those three gaps (trace-dataset integration, automated improvement loops, and a storage layer built for trace-scale data) push teams toward alternatives that treat evaluation as part of a continuous production workflow rather than a standalone step.
6 best Confident AI alternatives
1. Braintrust
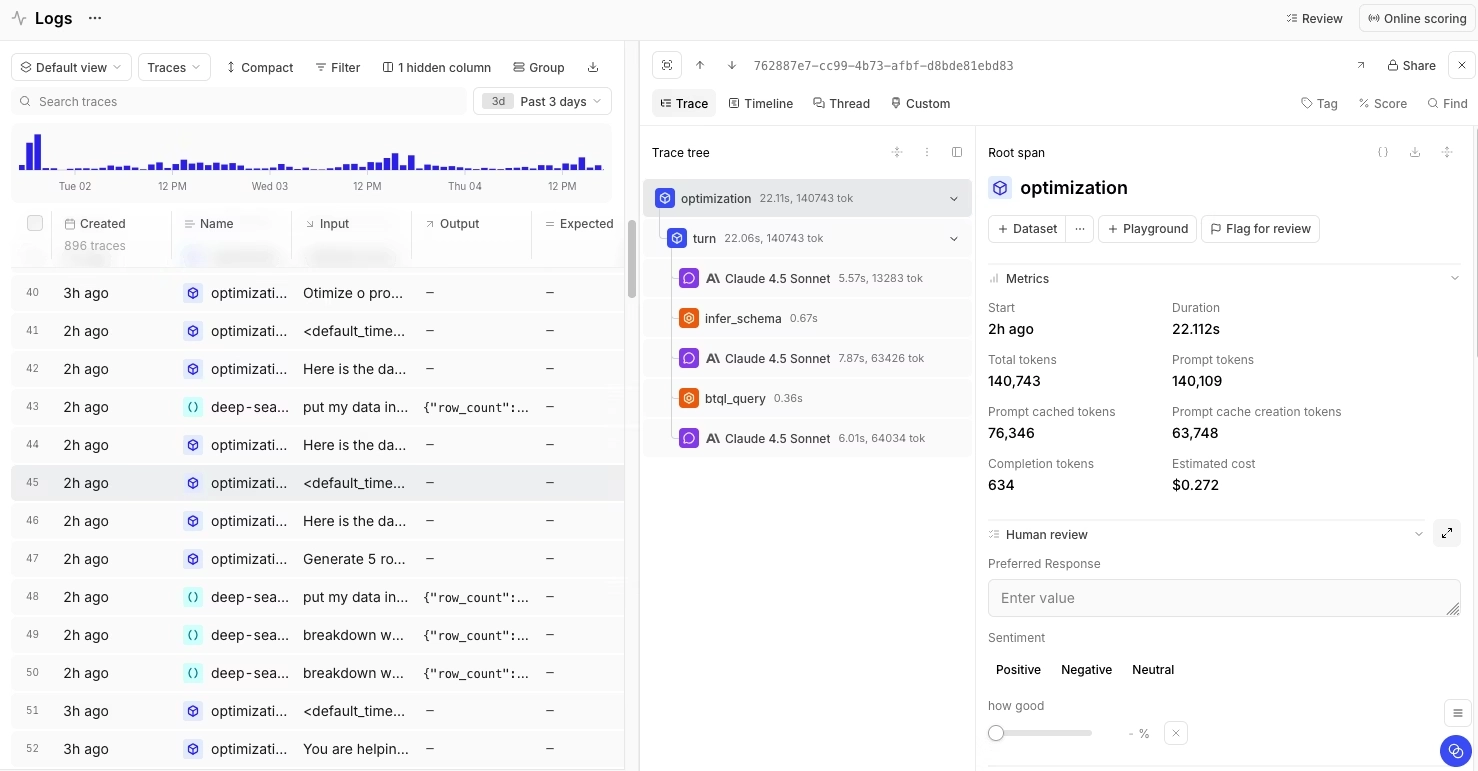
Best for: Teams that want every production failure to automatically make their AI better.
Braintrust's core advantage over Confident AI is trace-to-dataset conversion. In Confident AI, traces and datasets live in separate systems. Turning a production failure into a test case means exporting CSVs, curating datasets by hand, and losing context along the way. Braintrust eliminates the export-and-curate cycle. Any production trace becomes a test case in one click, so every flagged output automatically strengthens your eval suite. When Notion adopted Braintrust, their team went from catching 3 issues per day to 30, a 10x improvement in defect detection with the same headcount.
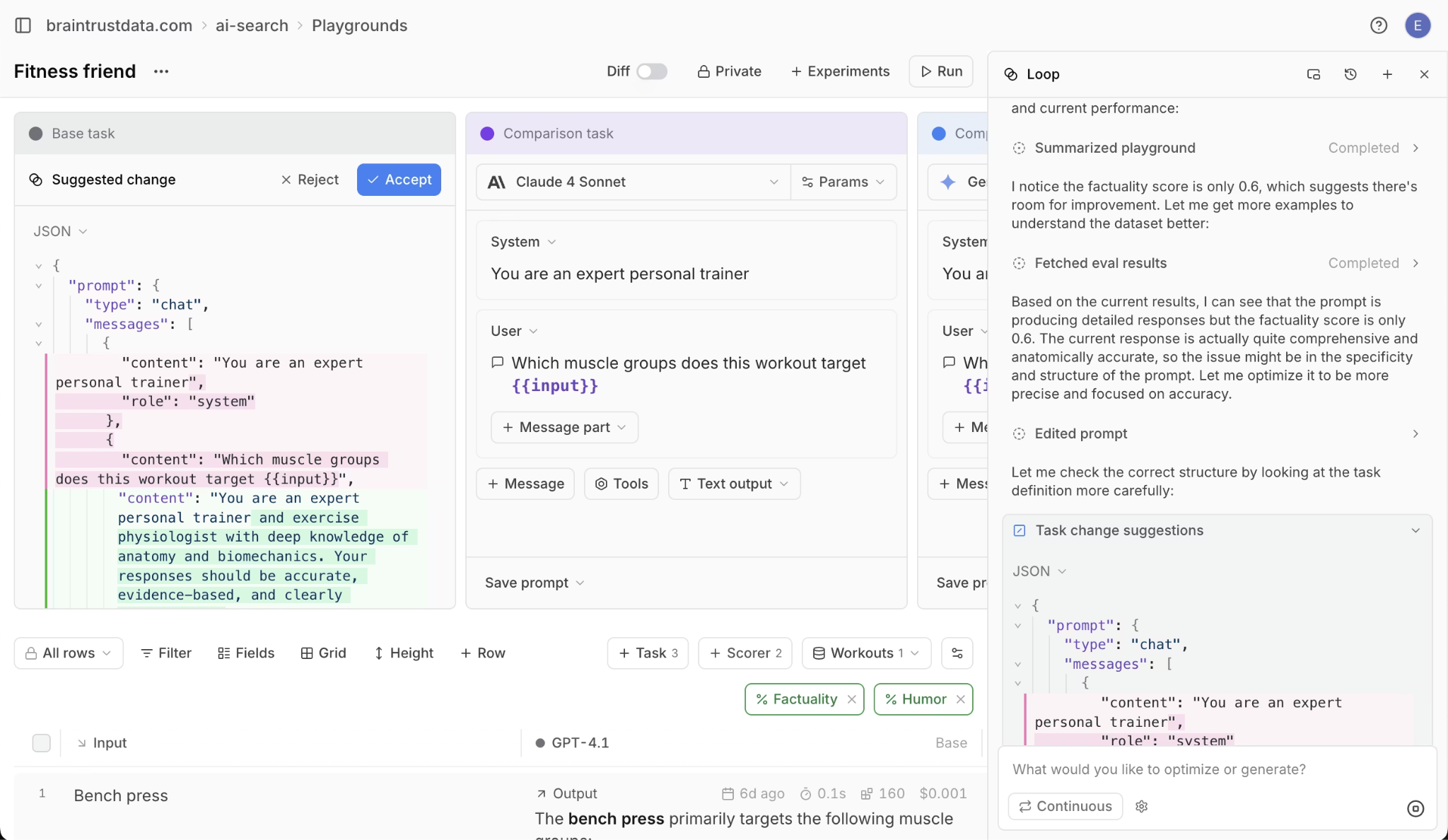
Loop lets Braintrust users refine prompts and evals by asking an AI agent. Loop analyzes your eval failure patterns, proposes better prompt versions, and generates targeted test cases for weak spots. Loop then runs the prompts against evals and iterates until scores improve. In Confident AI, prompt optimization is manual trial and error. In Braintrust, Loop does the analysis and optimization work for you.

Brainstore delivers 80x faster queries than general-purpose databases for trace data. The average AI span is ~50 KB compared to 900 bytes in traditional observability, and p90 traces regularly reach tens of GB. Payloads at that scale break Postgres. Teams running multi-step agents with tool calls and branching logic can query their full trace history without timeouts.
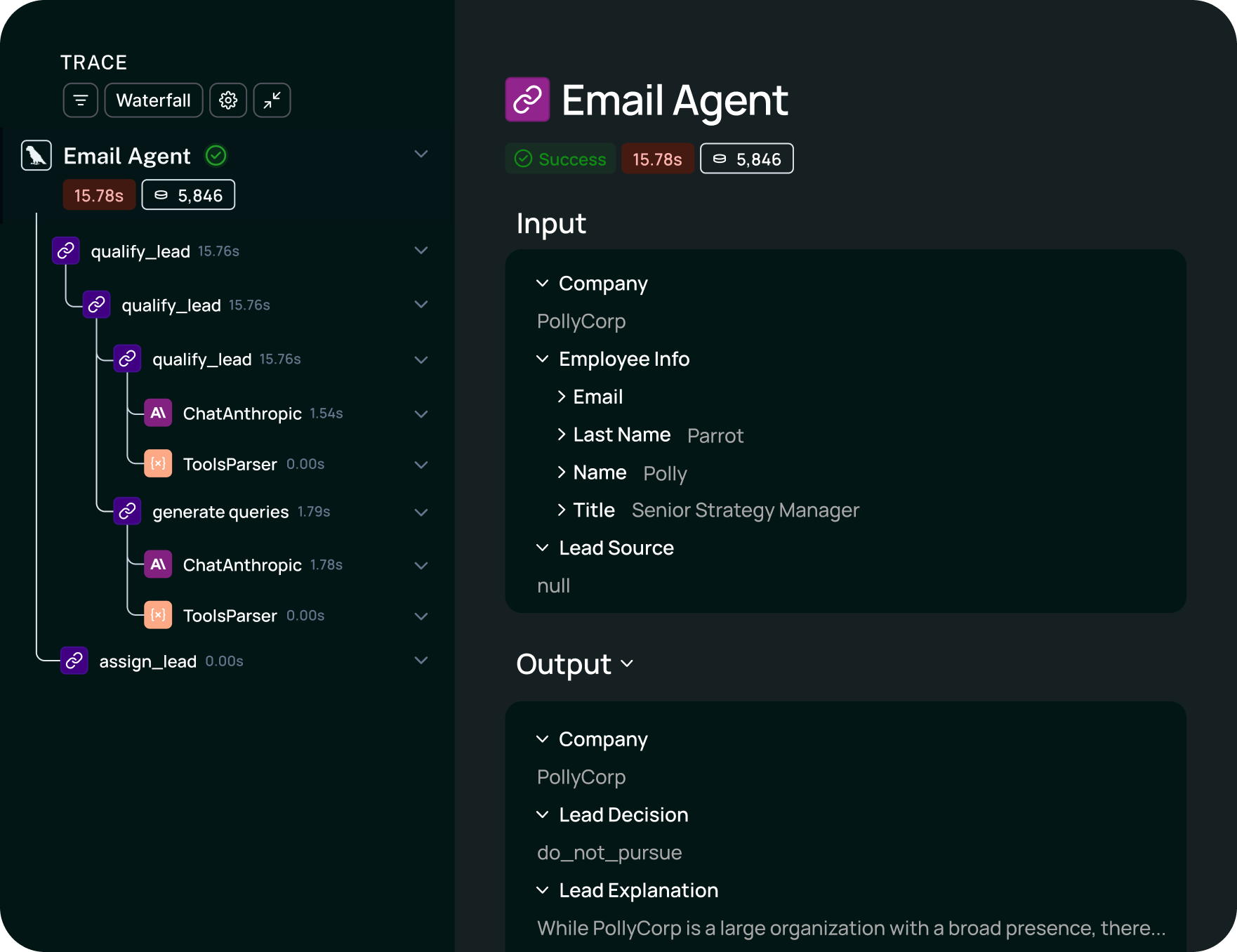
Topics uses ML-powered log clustering to surface user intents, sentiment, and emerging issues from production traffic. Instead of manually reviewing traces one by one to find quality problems, Topics groups patterns and gives you an immediate view of production behavior at scale.
Braintrust ships seven native SDKs (Python, TypeScript, Java, Go, Ruby, C#, and Kotlin) and embeds in Cursor, Claude Code, and OpenCode via MCP server. Auto-instrumentation takes one line of code for full observability, and developers get eval and tracing access inside their IDE without switching context.
Pros
- Trace-to-dataset in one click. Production failures become eval test cases automatically, replacing the manual data wrangling Confident AI requires.
- Loop automates prompt optimization. An AI agent analyzes failures, rewrites prompts, and iterates on eval scores without waiting for manual intervention.
- 80x faster trace queries. Brainstore handles large traces that crash general-purpose databases, keeping debugging fast for complex agent pipelines.
- Topics surfaces production patterns automatically. ML-powered clustering identifies user intents and quality issues without manual trace review.
- Seven native SDKs and IDE integration. Python, TypeScript, Java, Go, Ruby, C#, and Kotlin support plus Cursor, Claude Code, and OpenCode embedding.
- CI/CD quality gates. A native GitHub Action blocks merges when quality scores drop below your thresholds.
- $249/month flat, no per-seat pricing. Unlimited users means PMs, QA, and engineers all have access without budget negotiations. The free tier includes 1 GB of processed data, more generous than competitors that cap free usage at 5k-50k traces.
- SOC 2 Type II, HIPAA, GDPR. Hybrid deployment options satisfy security reviews without sacrificing features.
Cons
- Opinionated workflow. Teams that want a modular, plug-in-one-piece approach may find Braintrust's integrated system more structure than they need.
- Smaller open-source footprint than DeepEval. The OSS eval library is growing but does not yet match DeepEval's 50+ built-in metric count.
Pricing
Free tier includes 1 GB of processed data, 10K eval scores, and unlimited users. Pro starts at $249/month flat. Enterprise plans are custom. See pricing details.
Start evaluating with Braintrust for free
2. Arize Phoenix
Best for: Teams that want OpenTelemetry-native, vendor-agnostic tracing they can fully self-host.
Phoenix captures traces with OpenTelemetry and the OpenInference standard, so the data stays portable and works across most frameworks rather than locking you into one vendor. You can replay a trace to inspect a failure, run the built-in evaluation templates against model behavior, and use embedding clustering and drift detection to spot patterns across similar failures that text filtering would miss. The open-source version is free to self-host with no feature restrictions. The managed cloud offering, Arize AX, adds enterprise support and more compliance capabilities.
The cost is in the operations and the workflow. Self-hosting Phoenix means you stand up and maintain the infrastructure yourself, and the eval workflows are looser than on eval-first platforms. There is no automated improvement loop like Loop. Eval templates flag problems, but they do not feed into prompt optimization or scorer generation, and routing production data back into evals means writing your own pipelines.
Pros
- OpenTelemetry-native, portable trace data. OpenInference instrumentation keeps data vendor-agnostic and gives broad framework support.
- Embedding clustering and drift detection. Identifies failure patterns across similar cases that simple text filtering would miss.
- Free and self-hostable. The open-source version runs with no feature restrictions for teams with DevOps resources to maintain it.
Cons
- Self-hosting overhead. Running the open-source version requires standing up and maintaining your own infrastructure.
- Less integrated eval workflows. Evaluation is more loosely coupled than on eval-first platforms, with no automated improvement loop.
- Managed features sit behind Arize AX. Cloud capabilities require Arize AX with separate pricing.
Pricing
Open-source and free for self-hosting. Arize AX has a free tier with 25K spans/month, and the paid plan starts at $50/month.
See our full head-to-head comparison of Braintrust and Arize Phoenix to dive deeper.
3. Galileo
Best for: Teams focused on runtime guardrails and production safety.
The eval-to-guardrail lifecycle is Galileo's strongest angle: you define quality criteria during evaluation, then deploy those same criteria as runtime protection. For teams where safety and compliance checks are the primary concern, Galileo packages that workflow more tightly than general-purpose eval platforms. But Galileo is not a full-loop alternative to Confident AI. Prompt management, dataset curation, and CI/CD gating are less developed, and there is no equivalent to Loop's automated improvement cycle or Brainstore's trace query performance.
Pros
- Eval-to-guardrail lifecycle. Quality criteria defined during testing deploy directly as production guardrails without reimplementation.
Cons
- Narrower iteration tooling. Prompt management, dataset curation, and CI/CD gating are less developed compared to full-loop platforms like Braintrust.
- Smaller ecosystem. Fewer integrations and a smaller community mean more custom glue code for non-standard stacks.
Pricing
Free tier available. Paid plans are usage-based; contact Galileo for specifics.
See our full head-to-head comparison of Braintrust and Galileo to dive deeper.
4. Weights & Biases Weave
Best for: ML teams already invested in the W&B ecosystem who want to add LLM eval without adopting a new vendor.
Weave extends W&B's experiment tracking heritage to LLM workflows. The @weave.op decorator wraps any Python function to automatically capture inputs, outputs, and metadata with full version history. Leaderboards let you compare model and prompt variants across runs using the same interface your team already uses for traditional ML experiments.
Weave's strength is familiarity for existing W&B users: project structure, permissions, and visualization patterns carry over directly. The tradeoff is that Weave focuses on experiment-time evaluation, not continuous production observability. There is no equivalent to Loop for automated improvement, no production alerting workflow, and LLM-specific capabilities like guardrails, human annotation queues, and LLM-as-a-judge patterns are less mature than in LLM-first platforms.
Pros
- Zero friction for W&B users. If your team already tracks ML experiments in W&B, Weave inherits all existing project structure and permissions.
- Automatic versioning via decorators. The
@weave.oppattern captures every function call's inputs and outputs without manual logging. - Leaderboard comparisons. Side-by-side prompt and model variant scoring uses familiar W&B visualization patterns.
Cons
- Weaker production monitoring. Weave focuses on experiment-time eval, not continuous production observability with alerting and trace analysis.
- Less LLM-specific depth. Guardrails, human annotation workflows, and LLM-as-a-judge patterns are less mature than in LLM-first platforms.
- No automated improvement loop. Nothing comparable to Loop for closing the cycle between eval results and prompt optimization.
Pricing
Weave is included in W&B plans. Free tier available; Teams plan starts at $50/seat/month.
5. Fiddler AI
Best for: Regulated enterprises that need ML and LLM governance under one roof.
Fiddler operates in finance, healthcare, and defense environments where audit trails and compliance documentation are non-negotiable. Their Trust Models run guardrail checks in under 100ms with native safety filters. Hierarchical root cause analysis traces failures across multi-agent systems, mapping which agent step introduced a policy violation or quality drop.
Fiddler's compliance-first design is its differentiator and its constraint. Every model decision, prompt version, and evaluation result is logged with the lineage detail that regulated industries require. But that governance overhead slows iteration cycles considerably. Teams focused on rapid prompt experimentation and frequent deployment will find Fiddler's approval gates and process structure counterproductive. There is no self-serve free tier or transparent pricing, which creates additional friction for smaller teams evaluating the platform.
Pros
- Compliance-grade audit trails. Every model decision, prompt version, and evaluation result is logged with the lineage detail that regulated industries require.
- Hierarchical root cause analysis. Multi-agent failures can be traced to the specific agent step and input that caused the issue.
- Sub-100ms Trust Models. Native guardrails run fast enough for synchronous production use in latency-sensitive applications.
Cons
- Slow iteration cycles. Governance-first design means more approval gates and process overhead, which slows the rapid prompt iteration common in product-focused teams.
- Enterprise pricing only. No self-serve free tier or transparent pricing, which creates friction for smaller teams evaluating Fiddler.
Pricing
Custom enterprise pricing. Contact Fiddler for quotes.
6. PromptLayer
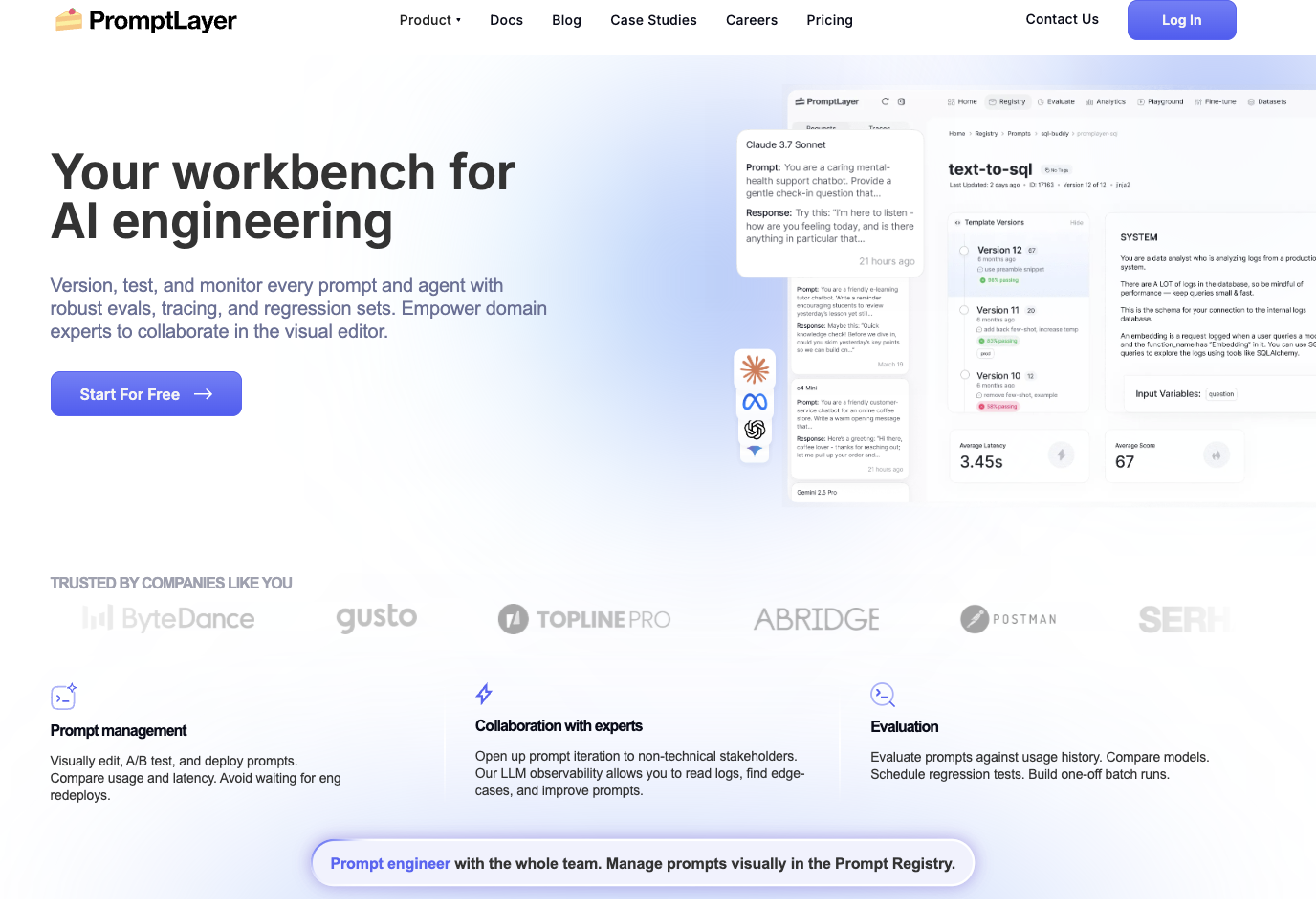
Best for: Teams that want prompt versioning and lightweight eval with minimal code changes.
PromptLayer takes a middleware approach: wrap your existing LLM API calls with PromptLayer's proxy, and every request is logged with full prompt version history. The visual dashboard lets non-engineers manage prompt templates, A/B test variants, and view basic performance metrics without modifying application code.
The middleware pattern means integration takes minutes, which is PromptLayer's primary advantage. For teams that need quick visibility into prompt performance and a non-technical interface for template management, PromptLayer delivers. But eval capabilities are shallow compared to every other platform on this list. There is no LLM-as-a-judge, no custom scorer framework, no production monitoring, and no alerting. PromptLayer logs requests but does not evaluate them in any meaningful depth.
Pros
- Minimal integration effort. The middleware pattern means adding PromptLayer to an existing codebase takes minutes, not days.
- Visual prompt management. Non-engineers can create, version, and deploy prompt templates through a dashboard without code changes.
- Lightweight request logging. Every LLM call is captured with latency, cost, and token usage automatically.
Cons
- Shallow eval capabilities. Scoring is limited compared to platforms with LLM-as-a-judge, custom scorer frameworks, or automated metric suites.
- No production monitoring or alerting. PromptLayer logs requests but does not offer continuous quality monitoring, anomaly detection, or incident workflows.
Pricing
Free tier available (5 users, 2,500 requests/month). Paid plans start at $49/month, with custom Enterprise pricing.
Comparison table
| Tool | Best for | Core strength | Main limitation | CI/CD gates | Eval depth | Tracing | Deployment / enterprise fit | Starting price |
|---|---|---|---|---|---|---|---|---|
| Braintrust | Full AI agent improvement loop | Trace-dataset integration + Loop agent + Brainstore | Smaller OSS metric library than DeepEval | Native GitHub Action | Automated + LLM-as-judge + human review | Full, with Brainstore (80x faster) | SOC 2 Type II, HIPAA, GDPR; hybrid deployment | Free (1 GB data) / $249/mo Pro |
| Arize Phoenix | OpenTelemetry-native self-hosting | Vendor-agnostic OTel tracing + embedding clustering | Self-hosting overhead, less integrated evals | Custom CI integration | Eval templates + LLM-as-judge | Full (OpenInference) | Self-hosted OSS; Arize AX cloud for enterprise | Free (OSS / 25K spans) / $50/mo |
| Galileo | Runtime guardrails | Guardrails and safety | Narrower iteration tooling | Limited | Guardrail-focused metrics | Partial | Cloud | Free / usage-based |
| W&B Weave | Existing W&B users | Experiment tracking integration | Weaker production monitoring | Limited | Decorator-based scoring | Experiment-time | Cloud; W&B enterprise tier available | Free / $50/seat/mo |
| Fiddler AI | Regulated enterprise governance | Compliance audit trails | Slow iteration, enterprise-only pricing | Custom | Trust Model guardrails | Full | On-prem and cloud; finance/healthcare/defense | Custom |
| PromptLayer | Prompt versioning | Middleware simplicity | Shallow evals, no monitoring | No | Basic metrics | Request logging | Cloud only; workspace-based | Free / $25/mo |
How we chose these alternatives
We evaluated each platform across six criteria that map to the workflow gaps teams encounter when outgrowing Confident AI.
Eval depth. Does the platform support automated scorers, LLM-as-a-judge, code-based checks, and human review? Can you define custom rubrics and annotation interfaces per task type? DeepEval sets a high bar with 50+ built-in metrics, so any alternative needs comparable or complementary scoring capability.
CI/CD quality gates. Can eval results block a deployment or merge automatically? Native integrations (like a GitHub Action) matter more than "you can build it yourself," because custom CI/CD glue code is maintenance overhead that compounds over time.
Tracing. How deeply does the platform capture production behavior? Full trace capture with span-level detail is the baseline for debugging agent workflows. We also evaluated query performance at scale, since traces with tool calls, retrieval steps, and branching logic generate payloads that general-purpose databases struggle with.
Production feedback loops. Can eval results feed back into prompt iteration automatically? The gap between "we know what's broken" and "we shipped a fix" defines team velocity. Platforms with automated improvement agents (like Loop) score higher than those that stop at surfacing results.
Pricing model. Per-seat pricing penalizes cross-functional adoption. Flat-rate or usage-based models let teams include PMs, QA engineers, and domain experts without budget negotiations. Free tier generosity also matters for proof-of-concept evaluations.
Enterprise fit. SOC 2, HIPAA, GDPR compliance, hybrid deployment options, SSO, and audit trail depth. Regulated industries need these capabilities as table stakes, not add-ons.
Why Braintrust is the strongest Confident AI alternative
The root problem with Confident AI is disconnection. Eval metrics live in one place, production traces in another, and prompt iteration in a third. Braintrust eliminates that fragmentation.
Production failures become eval datasets automatically. When a trace gets flagged (by a scorer, an alert, or human review), one click converts it into a permanent test case in your eval suite. No CSV exports, no manual dataset curation, no context lost between debugging and testing. That single capability changes the economics of LLM quality: instead of maintaining separate "eval time" and "production time" workflows, every production issue strengthens your test coverage.
Loop takes that further by automating the response to eval failures. When scores drop, Loop analyzes the failure patterns, proposes improved prompt versions, generates targeted test cases, and writes new scorers to cover the gap. The improvement cycle runs continuously rather than waiting for an engineer to context-switch into eval mode.
Brainstore keeps all of this fast regardless of scale. The average AI span is ~50 KB (compared to 900 bytes in traditional observability), and complex agent traces that reach tens of GB query in seconds rather than timing out. Notion, Stripe, and Instacart run production workloads through Braintrust at this scale daily.
Topics, Braintrust's ML-powered log clustering, gives teams automatic visibility into user intents, sentiment shifts, and emerging quality issues across production traffic. Topics and the Loop agent are how Braintrust does active observability, working in the background so the patterns worth acting on surface across all traffic without the per-trace cost of manual review. Seven native SDKs, one-line auto-instrumentation, and IDE integrations in Cursor, Claude Code, and OpenCode mean Braintrust fits into your existing development workflow rather than requiring you to restructure around it.
When Confident AI is still a good choice
Confident AI works well for teams in the development and testing phase who are primarily focused on eval metric coverage. DeepEval's 50+ built-in metrics provide broad scoring out of the box, and the open-source framework means zero vendor lock-in at the eval layer. If your team writes Python, runs evals in CI, and does not yet need production tracing or cross-functional collaboration, DeepEval is a reasonable starting point.
The cloud layer adds collaboration features, dataset management, and basic tracing. For teams that have not yet hit the scale or workflow complexity where trace-dataset integration and automated improvement loops become necessary, Confident AI covers the fundamentals.
Confident AI alternatives FAQs
What is an LLM evaluation platform?
An LLM evaluation platform scores the outputs of language models against defined quality criteria. Platforms range from simple metric libraries (like DeepEval) to integrated systems that connect evaluation with production tracing, prompt management, and CI/CD deployment gates.
How do I choose the right Confident AI alternative?
Start with your workflow bottleneck. If traces and eval datasets are disconnected, prioritize integration (Braintrust). If you need runtime guardrails, evaluate Galileo. If you want OpenTelemetry-native tracing you can self-host, look at Arize Phoenix. If governance and audit trails drive your requirements, look at Fiddler.
Is Braintrust better than Confident AI for LLM evaluation?
Yes, for teams operating in production. Braintrust covers everything Confident AI does at the eval layer (automated scorers, LLM-as-a-judge, code-based checks, human review) and closes the three structural gaps that limit Confident AI. First, trace-dataset integration: any production failure becomes an eval test case in one click, instead of requiring manual export and reimport. Second, Loop automates the improvement cycle by analyzing failure patterns, generating better prompts, creating targeted datasets, and writing new scorers. Third, Brainstore handles the ~50 KB-per-span, 10 GB+ trace payloads that break general-purpose databases, delivering 80x faster queries at scale. Confident AI is a reasonable starting point for teams in the dev/testing phase who need broad metric coverage. Once you ship to production, Braintrust's integrated workflow becomes the stronger choice.
What is the difference between LLM evaluation and LLM observability?
Evaluation measures output quality against a defined benchmark (offline or online scoring). Observability captures runtime behavior: latency, errors, trace data, cost, and user interactions. The most useful platforms connect both, so observability data feeds evaluation and evaluation results inform what to monitor in production.
Which alternative is best for LangChain teams?
Arize Phoenix instruments LangChain and LangGraph through OpenTelemetry and OpenInference, making it a strong fit for teams standardizing on those frameworks. Braintrust is the better choice if your eval and prompt iteration workflow extends beyond tracing, if you use multiple orchestration frameworks, or if you want built-in CI quality gates and a tighter production-to-eval loop.
Which alternative is best for enterprise governance?
Fiddler AI is built for regulated industries (finance, healthcare, defense) where compliance documentation, audit trails, and policy enforcement are primary requirements. Braintrust supports SOC 2 Type II, HIPAA, and GDPR with hybrid deployment, which satisfies most enterprise security reviews without the governance-first workflow overhead.
How quickly can I see results after switching?
Braintrust's free tier (1 GB of processed data, 10K eval scores, unlimited users) lets teams run a proof of concept in days. Auto-instrumentation takes one line of code, and most teams see initial value within the first week by converting existing production traces into eval datasets and running their first automated eval suite.
What is the best free alternative to Confident AI?
Braintrust offers the most generous free tier among the alternatives listed: 1 GB of processed data, 10K eval scores, and unlimited users with no seat-based restrictions. For comparison, Arize AX's free tier caps at 25K spans/month, though Arize Phoenix is also fully free and self-hostable as open source. DeepEval's open-source framework is also free at the library level, but the cloud features (collaboration, dataset management, tracing) require a paid Confident AI subscription.
Try Braintrust free and convert your first production trace into an eval dataset in minutes.