Datadog LLM observability alternatives (2026): Better tools for AI quality
Braintrust is the best overall Datadog alternative for teams that want evaluations, CI/CD quality gates, and production feedback loops in a single workflow.
Other top alternatives:
- Arize Phoenix - Open-source, OpenTelemetry-native observability you can self-host.
- Galileo - Packaged real-time guardrails powered by fast, low-cost evaluation models.
- W&B Weave - Best for organizations already using Weights & Biases for ML experiment tracking.
- Fiddler AI - Governance-heavy enterprises that need unified monitoring across traditional ML and LLM systems, plus compliance reporting.
Pick Braintrust if you need evaluation results to block regressions before deployment.
Monitoring AI systems is not the same as improving AI quality
Datadog does a good job helping teams monitor LLM systems with traces, latency tracking, token cost breakdowns, and dashboards that connect LLM performance to the rest of the infrastructure stack. For teams already using Datadog across their systems, adding LLM observability feels like a natural extension.
Datadog shows what happened inside an LLM pipeline, but it does not determine whether the output was actually good or help teams improve output quality systematically over time. Teams that need evals, CI/CD quality gates, regression prevention, and production feedback loops need a platform built for AI quality, not just monitoring.
This guide covers the five strongest Datadog alternatives for LLM observability, with Braintrust as the top recommendation for teams that want evaluation results to block regressions before deployment.
Why teams look for Datadog LLM observability alternatives
Datadog starts from dashboards, not from evals
Datadog's LLM Observability product extends the same monitoring-first approach Datadog uses for infrastructure and APM. Teams instrument the application, trace the flow into Datadog, and dashboards track latency, error rates, and token costs. Datadog's monitoring-first approach assumes visibility into system behavior is enough to diagnose and fix problems, which works for traditional infrastructure but breaks down for AI because an LLM can return a fast, error-free response that is completely wrong.
AI quality requires output-level evaluation
A 200ms response with zero errors can still hallucinate, ignore the system prompt, or produce an answer that is technically correct but useless to the end user. Datadog Experiments allows teams to create datasets from production traces and run evaluations. But evaluations in Datadog remain adjacent to the monitoring workflow. Teams that treat AI quality as a primary release concern often outgrow Datadog's evaluation capabilities quickly.
Missing workflows for continuous AI improvement
When a team finds a bad output in production, the team needs to turn the trace into a test case, run the test case through an eval suite, iterate on prompts or model settings, verify the fix in CI, and confirm the improvement holds in production. Datadog does not connect these steps into a single workflow. Teams end up exporting data, manually recreating scenarios, and relying on separate tools for evaluation and experimentation. The extra handoffs slow iteration and make it harder to maintain regression prevention.
5 best Datadog LLM observability alternatives in 2026
1. Braintrust
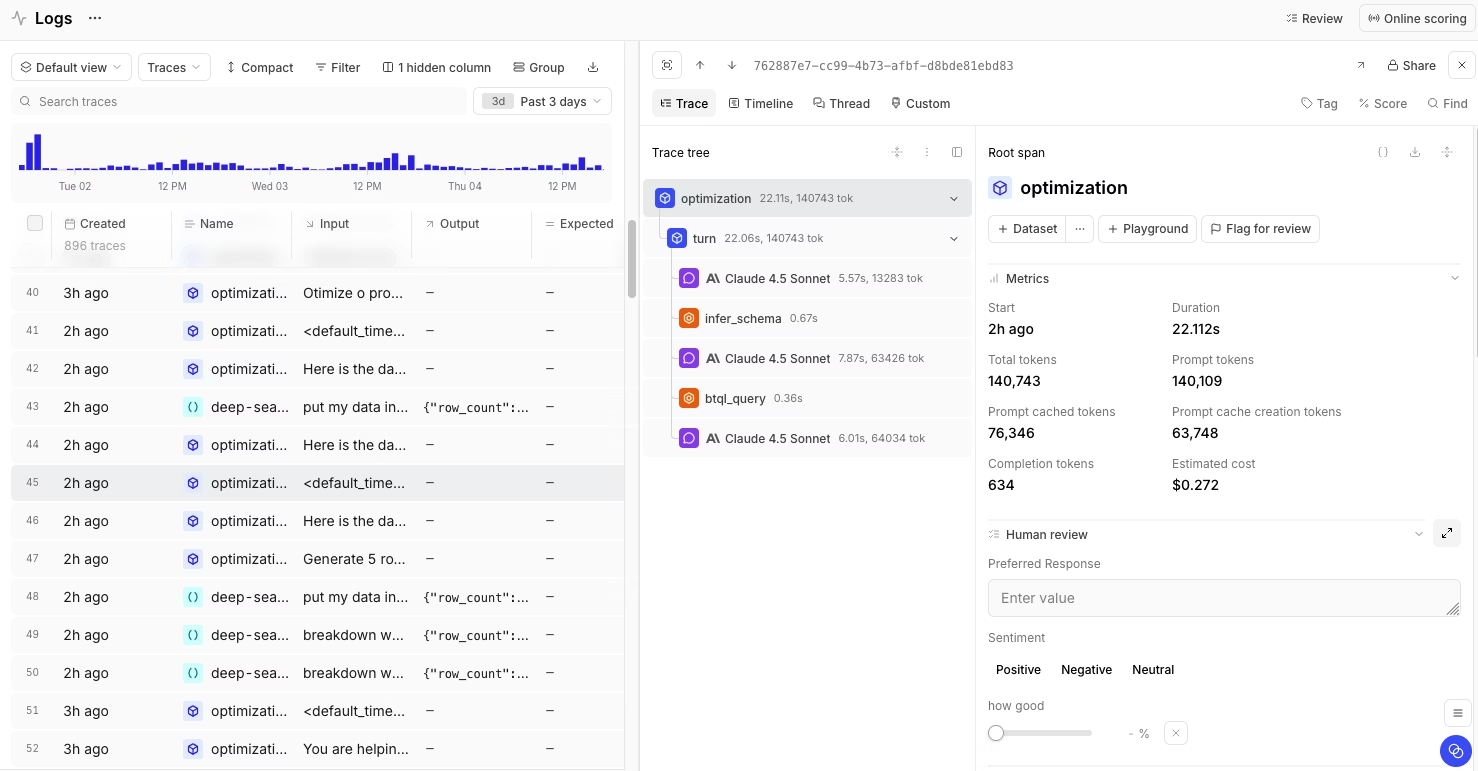
Best for AI SaaS teams that want to measure and improve AI output quality, alongside LLM monitoring.
Braintrust is an AI observability and evaluation platform that treats evals as the center of the development workflow rather than a monitoring add-on. Braintrust captures detailed traces across multi-step LLM and agent workflows. Every trace logs duration, token counts (including cached and reasoning tokens), tool calls, errors, and estimated cost. Unlike Datadog, where traces feed dashboards primarily, Braintrust traces feed directly into evaluations. Any production trace can become a test case with a single click, and eval results appear on every pull request through CI/CD quality gates. Teams can block deployments when scores regress, turning evaluation into an automated release requirement instead of a manual review step.
The evaluation system supports offline evals for pre-deployment testing, online scoring on live traffic, LLM-as-a-judge scoring, custom-code scorers, and configurable human-review workflows. Teams can iterate in shared playgrounds, compare prompts, models, or retrieval settings side by side, and promote stronger configurations into experiments and CI workflows. Loop, Braintrust's built-in AI agent, helps teams generate better prompts, scorers, and datasets tailored to the optimization goal.
Brainstore, Braintrust's dedicated database for AI observability, is designed to handle the data patterns generated by LLM traces. AI traces are significantly larger than traditional observability records, with a typical trace reaching 10 MB and traces reaching tens of GB. LLM traces also continue to change after initial ingestion, as automated judges add scores and human reviewers add annotations. Brainstore supports arbitrary queries over traces, immediate visibility for late-arriving spans, and full-text search across millions of records. Teams can also deploy Brainstore on their own infrastructure to meet data residency requirements.
Where Datadog leaves you to query dashboards and write filters to find what went wrong, Braintrust runs intelligence over your logs in the background and surfaces what matters. Topics is a daily classification pipeline that labels every production trace by built-in facets such as user intent, sentiment, and issue type, along with any custom facets you define. Those labels write back to the logs, so you can filter, query, and rank recurring failure modes across all traffic instead of only the runs a single detector happened to flag. Combined with the Loop agent, this is what Braintrust calls active observability, where the failures that recur surface across all traffic instead of waiting for you to interrogate a dashboard. Datadog's LLM Observability gives generic operational monitoring with limited agent-specific structure, while Topics applies LLM-native classification to every trace at scale.
Braintrust's CLI allows teams to run evals, manage datasets, and push prompt changes from the command line, which fits existing development workflows without forcing engineers into the UI for every task.
Pros
- Evals, tracing, experiments, and CI/CD quality gates with GitHub Action support for posting eval results on pull requests
- Supports offline evals before deployment and online scoring on production traffic
- Built-in scorers with flexible scorer types, including custom code scorers, LLM-as-a-judge scoring, and human review workflows
- Shared playgrounds for comparing prompts, models, and retrieval settings during team review
- One-click workflow for turning any production trace into a test case
- Loop agent for generating improved prompts, scorers, and test cases
- Topics classifies every production trace by intent, sentiment, and issue type (plus custom facets) so recurring failure modes surface across all traffic, not just flagged runs
- Brainstore supports AI-scale trace data, including late-arriving annotations and full-text search
- Unlimited users on all plans, including the free tier, so pricing scales with data volume rather than seat count
- SOC 2 Type II, HIPAA compliance, SSO, RBAC, and hybrid deployment options on Enterprise
Cons
- Teams evaluating only basic LLM monitoring may not need the full evaluation and release workflow
- Enterprise features like custom data retention, S3 export, and BAA require the Enterprise plan
Pricing
Braintrust's pricing is usage-based with no per-seat charges. The free plan includes 1 GB of processed data, 10K scores, and unlimited users. Paid plans start at $249/month, with custom enterprise pricing available. See pricing details.
2. Arize Phoenix
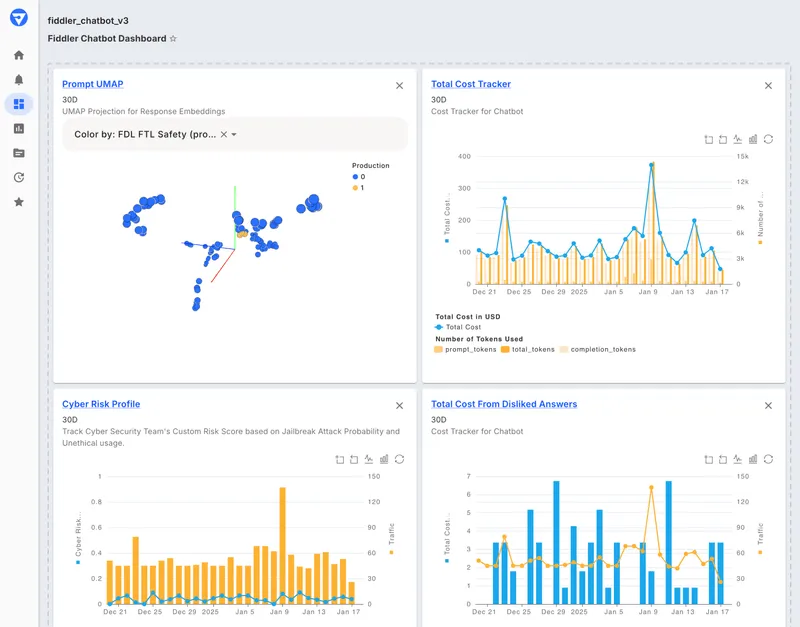
Best for teams that want open-source LLM tracing and prefer to keep data in their own infrastructure.
Arize Phoenix is a source-available observability tool (Elastic License 2.0) built on OpenTelemetry through the OpenInference project. It auto-instruments most major frameworks, including OpenAI Agents SDK, LangGraph, CrewAI, and LlamaIndex, so traces start flowing quickly without vendor lock-in. If you are leaving Datadog because you don't want LLM data leaving your own stack, Phoenix's self-hosted model fits well. It falls short on the jump from dev-time tracing to production quality management. That part requires Arize AX, which is a separate SaaS product rather than a higher tier of Phoenix.
Pros
- Self-hostable via Docker, Kubernetes, or locally with no usage caps under the ELv2 license
- OTel-native and framework-agnostic, so traces integrate cleanly into existing observability pipelines
- LLM-as-a-judge evals cover relevance, faithfulness, hallucination, and toxicity out of the box
- Versioned datasets, experiments, and a prompt playground let you replay traced calls and iterate on prompts
Cons
- Production-grade features (online evaluations, alerting, the Alyx copilot, and enterprise controls) live in Arize AX SaaS, which is a separate product decision rather than a plan upgrade
- No native CI/CD release gates, so there's no built-in mechanism to block a deploy when eval scores regress
Pricing
Phoenix itself is free to self-host with no span limits under the Elastic License 2.0. Arize AX, the managed SaaS layer, adds a free tier (25,000 spans/month, 15-day retention), AX Pro starting around $50/month, and custom enterprise pricing. Budget for AX if you need production monitoring, since Phoenix alone won't cover it.
See how Braintrust and Arize Phoenix compare.
3. Galileo
Best for teams that need real-time production guardrails and deep agent observability.
Galileo is an AI reliability platform built around three connected layers: agent observability, an insights engine, and real-time guardrails. All three run on Luna-2, a family of small language models tuned for evaluation. Luna-2 runs 10 to 20 metrics at once at sub-200ms latency and up to roughly 97% lower cost than LLM-based judges, which is what makes inline production protection workable at scale. Galileo is mainly a monitoring and protection tool. If your goal is to drive quality up over time through repeated evaluation cycles, CI/CD release gates, and trace data that flows back into test datasets, that workflow is less central in Galileo. Its Insights Engine is oriented around tracing failures rather than classifying every production trace by intent, sentiment, and issue type.
Pros
- Luna-2 evaluates 20+ built-in metrics across RAG, agent behavior, safety, and security in real time, without the cost of calling a frontier model as judge
- Runtime guardrails scan every prompt and response inline, blocking hallucinations, prompt injection, PII leakage, and toxic content before they reach users
- The Graph Engine visualizes every branch, decision, and tool call in an agent run, and the Insights Engine traces failures back to the execution paths that caused them
- VPC and on-premises deployment options make Galileo viable for regulated industries with strict data-residency requirements
Cons
- The platform is oriented toward monitoring and protecting live traffic rather than the iterative evaluation and release-gating workflow teams need to systematically improve model quality over time
- Trace insights focus on failure modes and root causes, without a layer that classifies all traffic and routes the problems it finds into evaluation and testing pipelines
- Beyond the free tier, full usage details and enterprise deployment options require a sales conversation, which slows cost evaluation for smaller teams moving quickly
Pricing
Galileo offers a free tier covering 5,000 traces per month with unlimited users and unlimited custom evals. The Pro plan starts at $100/month (billed annually) and includes 50,000 traces. VPC and on-premises deployments fall under custom enterprise pricing negotiated directly with the team.
See how Braintrust and Galileo compare.
4. W&B Weave
Best for teams already using Weights & Biases for ML experiment tracking.
W&B Weave extends the Weights & Biases platform into LLM observability and evaluation. Weave captures structured traces using a simple @weave.op decorator, automatically logs inputs, outputs, costs, and latency, and organizes everything into trace trees that show the full execution path of multi-step workflows. Teams that already use W&B for ML experiment tracking, model versioning, and artifact management can add LLM observability without introducing a new vendor or learning a new interface.
Pros
- Integration with the broader W&B ecosystem for ML workflows
- Simple instrumentation with the @weave.op decorator and OpenTelemetry support
- Evaluation scoring and dataset management in the same interface
- Open-source components available on GitHub
Cons
- Per-seat pricing scales directly with team size
- Less mature than dedicated AI quality platforms for production-focused evaluation workflows
Pricing
Free tier with limited seats, storage, and ingestion. Paid plans start at $60 per month. Enterprise pricing available on request.
5. Fiddler AI
Best for governance-heavy enterprises running both traditional ML and LLM workloads.
Fiddler AI is an enterprise AI observability and security platform for traditional ML models, LLM applications, and multi-agent systems. Fiddler fits best for organizations where explainability, fairness monitoring, compliance reporting, and unified oversight across predictive and generative AI are primary requirements.
Pros
- Unified monitoring for ML models, LLMs, and agents in one platform
- Explainability features, including feature importance, counterfactual analysis, and fairness metrics
- Built-in metrics covering hallucination, toxicity, PII, drift, and business KPIs
- SaaS, VPC, and on-premises deployment with SOC 2 and HIPAA compliance
Cons
- Enterprise-focused pricing is not publicly listed, which slows down evaluation for smaller teams
- Governance-first design may add complexity for teams focused mainly on AI quality iteration
Pricing
Free guardrails plan with limited functionality. Custom pricing for full AI observability and enterprise features.
Comparison table: Best Datadog LLM observability alternatives (2026)
| Tool | Best for | Core strength | Main limitation | CI/CD quality gates | Evals depth | Tracing/observability | Pricing model | Deployment/enterprise fit |
|---|---|---|---|---|---|---|---|---|
| Braintrust | Teams that need AI quality to determine release decisions | Connects evals, tracing, experiments, and production feedback in one workflow | Some enterprise controls are reserved for the Enterprise plan | Yes, native | Deep (offline evals, online scoring, LLM-as-a-judge, code scorers, human review) | Detailed tracing for multi-step LLM and agent workflows, with Topics classifying every trace by intent, sentiment, and issue type and production-to-eval linkage | Usage-based, no seat fees | Enterprise-ready with SSO, RBAC, hybrid deployment, HIPAA, and self-hosting options |
| Arize Phoenix | Teams that want open-source, self-hosted observability | OpenTelemetry-native tracing and evals that keep data in your own stack | Production features like online evals and alerts require the paid Arize AX SaaS | No native gates | Good (LLM-as-a-judge relevance, faithfulness, hallucination, toxicity) | OpenTelemetry-based tracing for any framework, self-hosted | Free OSS self-host; Arize AX SaaS paid | Self-host OSS or move to Arize AX with enterprise tiers |
| Galileo | Teams that want packaged real-time guardrails | Luna-2 models run sub-200ms guardrails for production monitoring and protection | Less centered on iterative evaluation and release workflows | Via CI integration | Good (20+ built-in metrics) | Agent observability with real-time guardrails | Usage-based, free to enterprise | Enterprise options available, including VPC and on-premises deployment |
| W&B Weave | Teams already standardized on Weights & Biases for ML workflows | Keeps LLM observability and evaluation inside the W&B system | Less mature for production AI quality workflows | Limited | Good (custom scorers, dataset testing) | Application trace visibility inside the W&B platform | Per-seat | Best fit for existing W&B users |
| Fiddler AI | Governance-heavy enterprises running ML and LLM systems together | Unified oversight across traditional ML and generative AI with explainability and compliance reporting | Governance layer may feel heavy for teams focused mainly on iteration speed | Limited | Good (100+ metrics) | Coverage across ML, LLM, and agent systems | Per-trace + enterprise | Built for regulated enterprises needing compliance, VPC, or on-premises deployment |
Ready to upgrade your LLM observability workflow? Start free with Braintrust.
How we chose the best Datadog alternatives
We evaluated Datadog alternatives across eight criteria.
Evals depth measures whether a platform supports LLM-as-a-judge scoring, custom-code scorers, human review, and side-by-side experiment comparisons as part of the core workflow.
CI/CD quality gates measure whether teams can block deployments when eval scores regress inside existing CI pipelines.
Tracing and observability cover span-level visibility into multi-step agent workflows, including tool calls, retrieval steps, and intermediate reasoning.
Production feedback loops evaluate how easily teams can convert production traces into reusable test cases and eval datasets without manual export or data wrangling.
Pricing model considers whether billing scales predictably with usage and whether seat-based pricing creates artificial bottlenecks as teams grow.
Enterprise fit covers deployment flexibility, including SaaS, VPC, and on-premises options, along with compliance certifications such as SOC 2 and HIPAA, and access controls such as SSO and RBAC.
Each alternative in this guide was assessed against the full set of criteria, with the strongest overall performer listed first.
Why Braintrust is the best Datadog alternative for AI quality
Datadog helps teams monitor LLM systems. Braintrust enables teams to evaluate output quality, review regressions, and prevent lower-quality changes from being released by using evaluation results directly in the release process.
Braintrust integrates production debugging, evaluation, and release review into a single workflow. Teams can investigate production failures, turn those failures into reusable evaluation cases, compare changes against earlier performance, and use evaluation results during pull request reviews. Engineering, product, and applied AI teams can review the same traces and evaluation results.
Every Braintrust plan includes unlimited users, so access to traces, evaluation results, and debugging context does not become more expensive as more teammates need visibility. Pricing scales with usage rather than headcount, which makes broader collaboration easier to support.
Companies like Notion, Zapier, Stripe, and Vercel run Braintrust in production. Notion reported going from fixing 3 issues per day to 30 after adopting Braintrust because converting production traces into evaluation datasets removed much of the manual work that had been slowing down debugging.
Want to see how Braintrust compares to your current setup? Start free today.
When Datadog is still a fine choice
Datadog remains a reasonable option for teams already standardized on it for infrastructure and application monitoring who want basic LLM visibility without adding another vendor. When reducing vendor count outweighs the need for deeper evaluation workflows, keeping LLM observability inside an existing Datadog contract can reduce operational overhead. Teams that mainly need dashboards, alerts, cost tracking, and infrastructure correlation for LLM applications, rather than a workflow for iterative AI quality improvement, may find Datadog's LLM Observability product sufficient.
FAQs: Best Datadog alternatives in 2026
Is Datadog enough for LLM observability?
Datadog covers core LLM observability needs, including tracing, cost tracking, dashboards, and infrastructure correlation. For teams that mainly want visibility into system behavior, Datadog can be sufficient. Teams that need structured evaluations, CI/CD quality gates, and a direct path from production issues to reusable test cases usually need a platform built for AI quality, such as Braintrust.
What is the best Datadog alternative for AI quality?
Braintrust is the strongest Datadog alternative for teams focused on AI quality because evaluation is built into the development and release workflow. Production traces can be turned into evaluation datasets, evaluation results can gate pull requests, and usage-based pricing with unlimited users avoids per-seat costs that grow linearly as more teammates need visibility.
Which Datadog alternative is best for open-source, self-hosted observability?
Arize Phoenix is the strongest fit for teams that want open-source, OpenTelemetry-native observability they can self-host, keeping LLM telemetry inside their own infrastructure rather than a vendor's. Teams that also need online evaluation, alerting, or a release workflow that gates deployments on quality usually move to a managed platform. For AI-quality workflows specifically, Braintrust connects tracing, evaluation, and CI/CD quality gates in one place.
Which Datadog alternative is best for enterprise governance?
Fiddler AI is a strong fit for enterprises where governance, explainability, and compliance reporting are primary requirements. Fiddler covers traditional ML and LLM workloads on a single platform and supports regulated deployment models. Teams that need evaluation depth, release control, and continuous AI quality improvement should choose Braintrust over a governance-heavy system centered on compliance reporting.