7 best Grafana alternatives for LLM evaluation and AI quality
Grafana helps teams monitor LLM systems through dashboards that surface latency, token usage, cost, error rates, and trace data. For teams already using Grafana for infrastructure and application observability, Grafana Cloud AI Observability extends that same monitoring workflow to AI systems.
LLM application teams often need to measure response quality, catch regressions before release, and convert production failures into reusable test cases. Grafana can show what happened inside the system, but Grafana does not make evaluation part of the release workflow. Teams that need structured evals, CI/CD quality gates, and a connected workflow from production issues to regression testing often require additional tooling.
This guide covers seven Grafana alternatives for LLM evaluation and AI quality, with Braintrust as the strongest option for teams that need evaluation to gate releases and turn production failures into regression coverage.
Braintrust is the best overall Grafana alternative for teams that want evaluation, release gating, and regression prevention in one workflow.
Runner-up alternatives:
- Langfuse fits teams that want open-source LLM tracing and observability, self-hosting, and full data control.
- Galileo AI is for teams that want packaged real-time guardrails powered by low-cost Luna-2 evaluation models that score production traffic.
- Maxim AI works well for teams that need structured evaluation workflows and cross-functional collaboration between engineering and product.
- RAGAS is the standard open-source framework for RAG-specific evaluation metrics such as faithfulness, context precision, and answer relevance.
- Datadog suits teams already running Datadog for infrastructure and APM that want LLM Observability dashboards, tracing, and token-cost metrics in the same monitoring platform.
- ZenML is well-suited to pipeline-oriented ML teams that need orchestration and versioning across the full MLOps lifecycle, rather than LLM-specific evaluation.
Start with Braintrust for free if you need evaluation to gate releases and prevent regressions. Pick others if you only need open-source tracing, runtime guardrails, RAG-specific metrics, or pipeline orchestration.
Why teams look for Grafana alternatives for LLM evaluation
Grafana monitors system health, not output quality
Grafana Cloud AI Observability tracks latency, token usage, cost per call, error rates, and even programmatic quality scores via OpenLIT evaluators layered on top of Tempo traces. Grafana answers operational questions well, but it does not provide eval dataset management, experiment workflows for comparing prompt variants on a golden dataset, or a reliable way to determine whether a model change improved or degraded answer quality.
No CI/CD quality gates or regression prevention
When a developer changes a prompt or swaps a model, Grafana cannot run evaluations against that change before deployment. Grafana does not provide a GitHub Action that posts eval scores to a pull request or a quality gate that blocks a release when accuracy drops below a defined threshold. Without an automated quality check in the release process, regressions can reach production unnoticed.
No feedback loop from production failures to permanent test coverage
When a user reports a bad answer, the ideal process converts the failed trace into a test case, runs it through an eval suite, iterates on the prompt, verifies the fix in CI, and confirms the improvement in production. Grafana can display the trace, but cannot convert it into a dataset row, attach a scorer to it, or connect it to a quality gate that prevents the same failure from shipping again.
7 best Grafana alternatives for LLM evaluation and AI quality
1. Braintrust
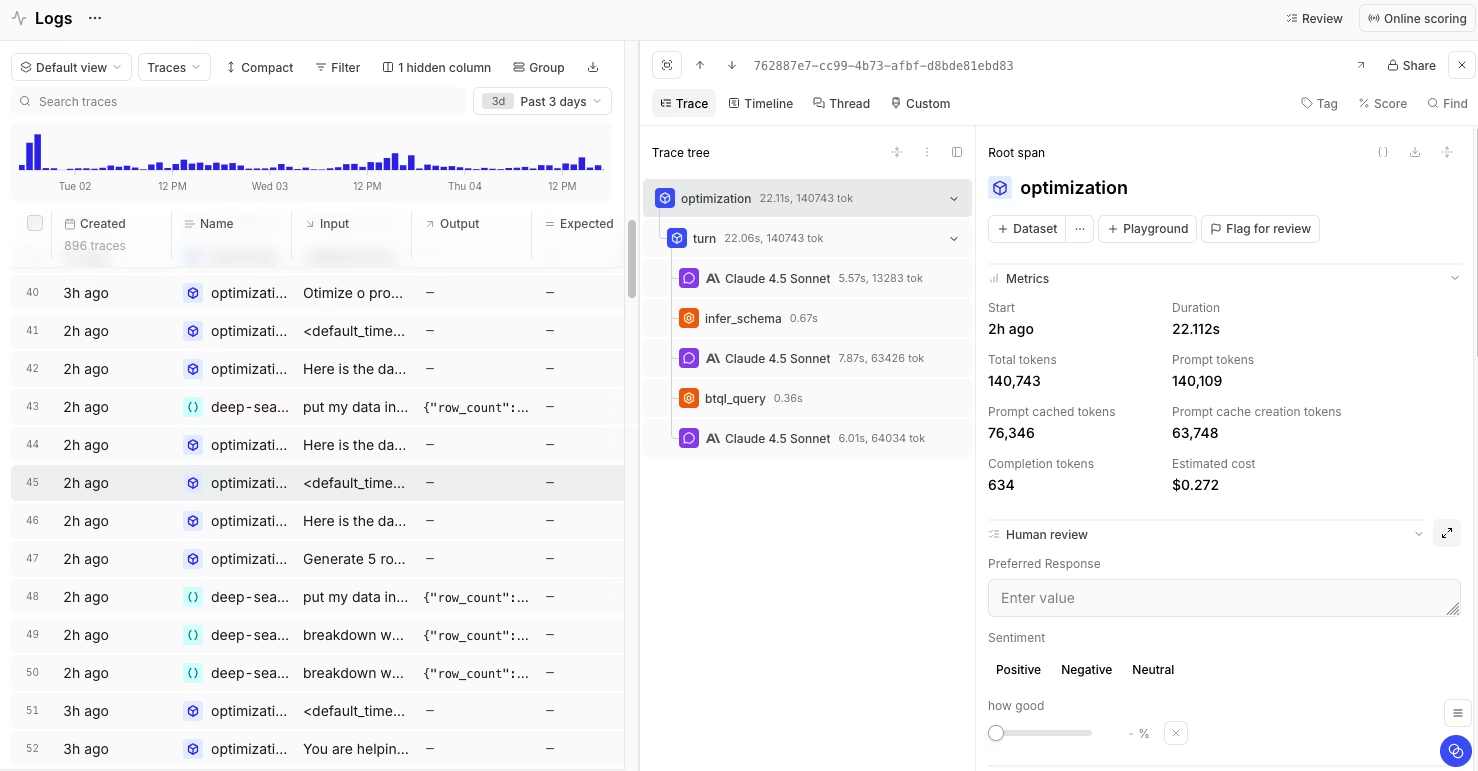
Best for teams that need AI output quality to guide release decisions alongside LLM monitoring.
Braintrust is the best Grafana alternative for teams that need evaluation, release gating, and regression testing within a single system. Braintrust includes native eval datasets, which are versioned collections of inputs and expected behaviors that teams can use to test any prompt, model, or retrieval setup. As production reveals new failure modes, teams can add them to the dataset and use it across development and production.
A native GitHub Action runs evals on every pull request, posts scores to the PR thread, and blocks the merge when scores fall below a configured threshold. A prompt change that would otherwise degrade answer quality is caught during review rather than surfacing later as user complaints.
Shared playgrounds let engineers and product reviewers test a sample prompt against the current dataset, compare it with the production version, and inspect scorer-level differences before release. Loop, the AI agent built into Braintrust, speeds up that work by generating datasets, scorers, and prompt variants from a plain-language description of what the team wants to improve.
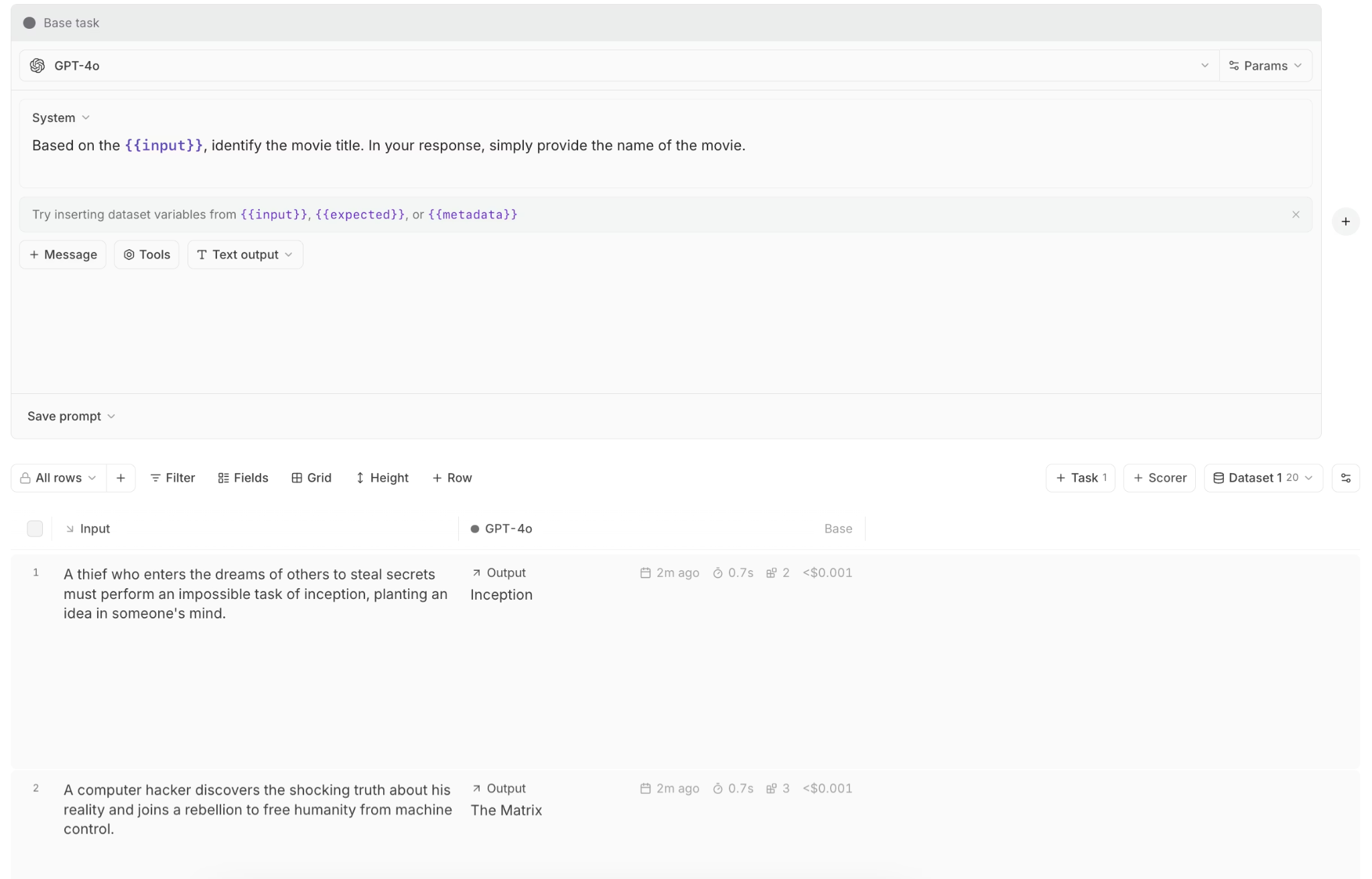
Configurable review interfaces route traces to reviewers based on team-defined criteria. Reviewer feedback feeds into the same eval results used in CI, so human judgment and automated scoring operate within the same framework. In domains where quality cannot be reduced to deterministic checks or LLM judges, such as medical summarization or legal drafting, human review becomes essential.
Brainstore, the observability database that powers Braintrust, is built for AI observability workloads. LLM traces are larger, more nested, and more mutable than infrastructure telemetry because scorers and reviewers continue adding scores and annotations after ingestion. Grafana's Loki and Tempo were built for infrastructure telemetry, which is why querying AI workloads through those systems can become slow and expensive at scale. Brainstore supports arbitrary queries across millions of traces, fast span-level retrieval, and late-arriving annotations without breaking trace history. Enterprise customers can also run Brainstore inside their own VPC to meet stricter data residency requirements.
Grafana shows you what is happening only once you build the dashboard or write the query. Braintrust works the other way around: a daily Topics pipeline classifies every production trace by intent, sentiment, and the issues it ran into, plus any custom facet the team defines, then writes those labels back to the logs. You can rank which failure modes recur across all traffic instead of only the runs a single scorer happened to flag, without setting up a dashboard first. The Loop agent runs the same analysis on the side, so the failures that repeat surface on their own instead of waiting behind a query you have to write.
Pros
- Versioned eval datasets managed natively
- GitHub Action that runs evals on every PR, posts scores to the thread, and blocks merges on regression
- One-click conversion of production traces into reusable test cases
- Shared playgrounds for side-by-side prompt, model, and retrieval comparison tied to scorer results
- LLM-as-a-judge, code-based, and human-review scorers in one framework
- Loop automates dataset creation, scorer generation, and prompt iteration from plain-language instructions
- Topics classifies every production trace daily by intent, sentiment, and issues so recurring failure modes surface without building dashboards or writing queries
- Brainstore supports AI-scale trace data with fast span queries and late-arriving annotations
- Unlimited users on every plan, including the free tier
- SOC 2 Type II, HIPAA, SSO, RBAC, and hybrid deployment on Enterprise
Cons
- Teams that only need basic LLM monitoring may not need the full evaluation workflow
- Self-hosting Brainstore, custom data retention, and BAA coverage require the Enterprise plan
Pricing
Usage-based with no per-seat charges. The Starter plan is free and covers 1 GB of processed data, 10K scores, and unlimited users. Paid plans begin at $249/month, with custom enterprise pricing available.
Compare Braintrust and Grafana directly in our head-to-head guide.
2. Langfuse
Best for teams that want open-source LLM tracing with self-hosting.
Langfuse is an open-source LLM observability platform for teams that want tracing, prompt management, and evaluation with deployment control. Langfuse supports multi-turn traces, prompt versioning, user feedback, custom metrics, and LLM-as-a-judge scoring. Python and JavaScript SDKs cover common implementation paths, OpenTelemetry support connects Langfuse to existing telemetry systems, and integrations include frameworks such as LangChain and LlamaIndex.
Pros
- Open-source with self-hosting
- Multi-turn tracing, prompt versioning, and evaluation support
- OpenTelemetry support and broad framework coverage
Cons
- Release gating and regression workflows require more manual setup
- Production-to-eval workflows are less developed than in eval-first platforms
Pricing
Free self-hosting and a free cloud plan with 50K units per month. Paid plan starts at $29 per month.
Compare Braintrust and Langfuse directly in our head-to-head guide.
3. Galileo AI

Best for teams that need real-time guardrails on production traffic.
Galileo focuses on runtime protection for production AI systems. The Luna-2 model family scores responses on quality, safety, and security metrics in live traffic, enabling continuous evaluation of production outputs. Coverage includes hallucination, prompt injection, PII leakage, toxicity, and context adherence. Galileo can also turn validated pre-production scorers into guardrails for live traffic.
Pros
- Real-time guardrails on production traffic
- Built-in metrics for common quality and safety risks
- Policy controls for multi-agent systems
- VPC and on-premises deployment options
Cons
- Release-time iteration is less central than runtime protection
- Enterprise pricing requires a sales process
Pricing
Free tier with 5,000 traces/month. Paid plan starts at $100/month. Custom enterprise pricing.
Compare Braintrust and Galileo AI directly in our head-to-head guide.
4. Maxim AI
Best for teams where technical and non-technical members collaborate on shaping output quality.
Maxim AI combines prompt experimentation, agent simulation, offline evaluation, and production observability on a single platform. Product managers can configure evaluations through a no-code interface, making Maxim easier to use for both technical and non-technical teams. The simulation engine tests agents across different user personas and multi-turn scenarios before release, and the evaluation layer supports deterministic checks, statistical scoring, LLM-as-a-judge methods, and human annotation queues.
Pros
- Deterministic, statistical, LLM-as-a-judge, and human evaluators in one system
- Agent simulation for pre-release testing
- No-code evaluation setup for product teams
- SDKs for Python, TypeScript, Java, and Go
Cons
- Setup takes longer
- Online evaluation and longer retention require paid plans
Pricing
Free plan with 10K logs per month, paid plan starts at $29/seat/month. Custom enterprise pricing.
5. RAGAS

Best open-source framework for RAG evaluation metrics.
RAGAS is a metrics framework for RAG evaluation. It provides the core metrics widely used in retrieval pipelines, including faithfulness, context precision, context recall, answer relevance, and context relevance. RAGAS can also generate synthetic evaluation datasets using knowledge-graph-based methods, thereby reducing manual dataset creation. Integrations include LangChain, LlamaIndex, and observability platforms such as Braintrust and Langfuse.
Pros
- Core RAG metrics with minimal setup
- Synthetic test dataset generation
- Integrations with major frameworks and evaluation platforms
Cons
- No built-in observability, experiment tracking, or CI integration
- Judge-model errors can produce NaN scores without a graceful fallback
Pricing
Free and open-source.
6. Datadog
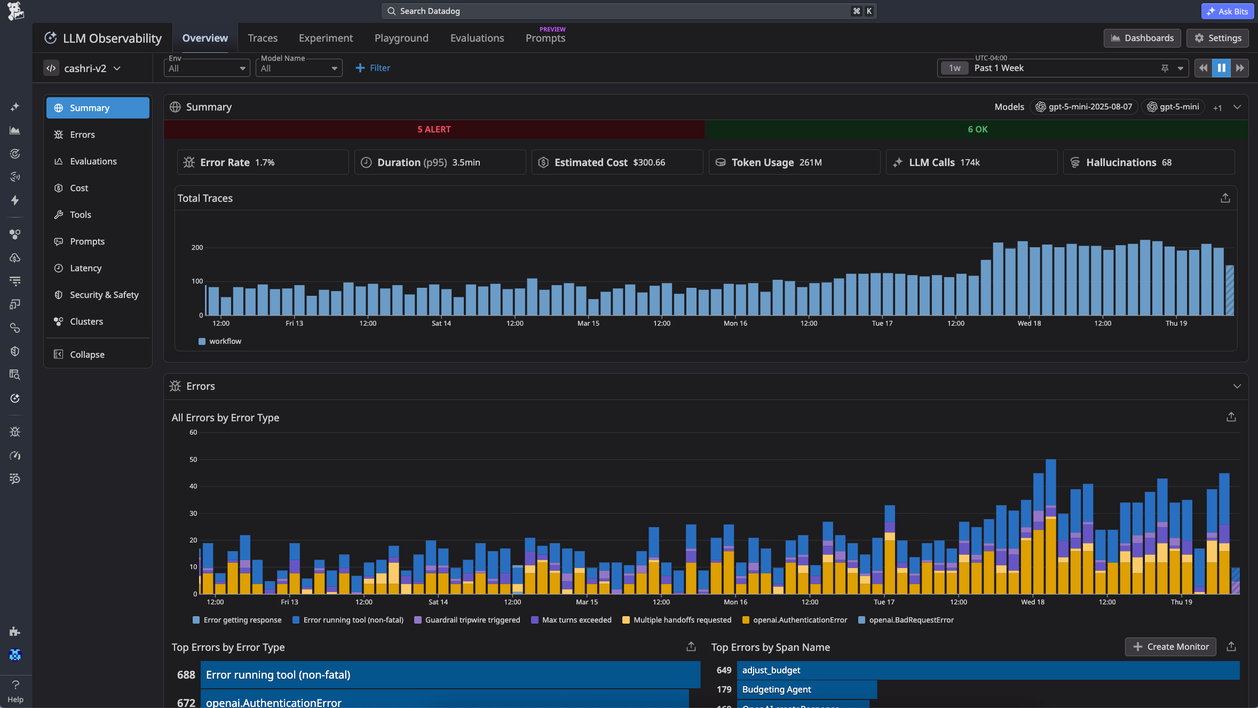
Best for teams already running Datadog for infrastructure and APM.
Datadog's LLM Observability product brings the metrics and dashboards Datadog already uses for infrastructure and APM to AI systems. You instrument the application, send traces into Datadog, and the dashboards track latency, error rates, and token costs next to the rest of your stack. Datadog's LLM Experiments can create datasets from production traces and run evaluations, but that work sits next to the monitoring rather than driving releases.
Pros
- Unified monitoring for infrastructure, APM, and LLMs in one platform
- Integrates with existing Datadog deployments
- Mature alerting and anomaly detection
- Dashboards connect LLM latency and token cost to the broader stack
Cons
- Evaluation capabilities stay adjacent to the monitoring workflow
- Expensive compared with specialized LLM evaluation tools
- No native release gating or production-to-eval feedback loop
Pricing
LLM Observability is priced separately from Datadog's infrastructure and APM tiers. The free tier covers 40K LLM spans per month with 15-day retention, and paid LLM Observability starts at $160/month for 100K spans, with overages around $3.50 per 10K spans. Custom enterprise pricing available.
Compare Braintrust and Datadog directly in our head-to-head guide.
7. ZenML
Best for ML teams that need pipeline orchestration across the MLOps lifecycle.
ZenML is a pipeline orchestration tool for reproducible ML and LLM workflows. It supports Kubernetes, Airflow, Kubeflow, and local execution, and it automatically versions code, dependencies, and artifacts. Integrations with major cloud orchestrators make it a reasonable fit for teams running both classical ML and LLM workloads.
Pros
- Infrastructure-agnostic orchestration across ML and LLM pipelines
- Automatic versioning of code, dependencies, and artifacts
- Integrations with major cloud orchestrators
Cons
- No LLM-specific tracing, eval playgrounds, or human review
- Teams still need a separate AI quality platform
Pricing
Free open-source self-hosting. Managed SaaS starts at $399/month. Custom enterprise pricing.
Comparison table: Best Grafana alternatives 2026
| Tool | Best for | Core strength | Main limitation | CI/CD gates | Evals depth | Pricing model |
|---|---|---|---|---|---|---|
| Braintrust | AI teams that need output quality to shape release decisions | Connects evals, tracing, human review, and release gating in one production workflow | Some enterprise controls are reserved for the Enterprise plan | Yes, native GitHub Actions | Deep (offline, online, LLM-as-a-judge, code-based, human review) | Usage-based, no per-seat fees |
| Langfuse | Open-source tracing with self-hosting | Open-source tracing, prompt management, and self-hosting | CI gating and regression workflows require more manual setup | Limited | Good (annotation queues, scoring) | Free self-hosted; managed cloud |
| Galileo AI | Real-time guardrails on live traffic | Runtime protection on production traffic | Release-time evaluation is less central | Via CI integration | Good (prebuilt quality and safety metrics) | Usage-based |
| Maxim AI | Cross-functional eval work across PM and engineering | Evaluation workflows with simulation and collaboration | Broader setup surface | Limited | Good (deterministic, statistical, LLM, human) | Per-seat + usage |
| RAGAS | RAG-specific evaluation metrics | RAG evaluation metrics library | No built-in platform for observability or release workflows | No | Focused (faithfulness, context precision, context recall, answer relevancy, context relevancy) | Free open-source |
| Datadog | Teams already running Datadog for infrastructure and APM | Unified LLM, APM, and infrastructure monitoring with dashboards and alerting | Evaluation stays adjacent to monitoring; no native release gating | Limited | Adjacent (datasets and experiments alongside monitoring) | Per-LLM-span + usage |
| ZenML | MLOps pipeline orchestration | Reproducible pipeline orchestration across ML and LLM workflows | No LLM-specific quality workflow | No | None built-in | Free open-source; Pro managed |
Ready to replace dashboards with a full-suite AI quality workflow? Start free with Braintrust →
Why Braintrust is the best Grafana alternative for AI quality
Grafana answers what happened inside an LLM call, while Braintrust answers whether the output was good, whether a proposed change makes quality better or worse, and whether the team should ship the change at all.
Braintrust turns evaluation into part of the release process. An engineer can inspect a failing trace, add it to an eval dataset, write a scorer for the failure, and connect that scorer to a CI quality gate. The next pull request that introduces the same regression fails automatically before the change reaches production. Grafana can capture the trace, but it cannot turn it into a reusable release check within the same workflow.
Unlimited users on every plan make Braintrust easier to use across engineering, product, applied AI, and domain review teams. Everyone can work from the same traces, eval results, and playgrounds without per-seat limits, while pricing scales with data volume rather than headcount.
Notion, Stripe, Vercel, Zapier, Airtable, and Instacart use Braintrust in production. Notion reported moving from resolving 3 issues per day to 30 after turning production traces into evaluation cases that the team could reuse. Want to bring evaluation into your release workflow? Start free with Braintrust →
When Grafana is still the right choice
Grafana remains a reasonable choice for teams already standardized on the LGTM stack and looking for basic LLM visibility without adding another vendor. Teams focused on cost tracking, latency, and infrastructure metrics, as well as alerting on operational thresholds, can meet those needs with Grafana Cloud AI Observability.
Frequently asked questions
Is Grafana enough for LLM observability?
Grafana Cloud AI Observability covers the main monitoring layer through Tempo-based tracing, token and cost analytics, and OpenLIT-powered quality scores attached to traces. Grafana works for teams focused on operational visibility. Teams that need structured evaluations, CI quality gates, and a way to turn production failures into reusable test cases usually need a dedicated LLM evaluation platform like Braintrust.
What is the best Grafana alternative for AI quality?
Braintrust is the best Grafana alternative for AI quality because it puts evaluation into the release workflow rather than layering it on top of telemetry. Teams can turn production traces into eval datasets, gate pull requests through a native GitHub Action, and give engineering, product, and domain reviewers access without per-seat pricing limits.
Is Braintrust better than Grafana for LLM evaluation?
For LLM evaluation, yes. Grafana is built for monitoring latency, cost, errors, and traces. Braintrust is built to evaluate whether outputs are correct, safe, and useful, block regressions before release, and turn production failures into permanent test coverage. Teams that need to improve AI output quality over time will get more value from Braintrust than from Grafana alone.
Which Grafana alternative is best for LangChain teams?
For teams building deeply inside LangChain or LangGraph, Langfuse offers native LangChain and LlamaIndex integrations so tracing and debugging work without custom instrumentation. Teams that also need CI quality gates, broader framework coverage, and a stronger production-to-eval workflow may prefer Braintrust.