- Best overall (no-code, evaluation-driven iteration with production deployment): Braintrust
- Best for Git-style versioning and team collaboration: PromptHub
- Best for agent-first engineering with runtime protection: Galileo
- Best for visual agent workflows and orchestration: Vellum
- Best for CLI-driven testing and security scanning: Promptfoo
Organizations building production AI applications often face the same issue, where prompts that perform well during development fail in production. A single prompt change can cause a chatbot to hallucinate product details, an agent to select the wrong tool, or a system to fabricate citations. These failures usually occur because prompt updates are deployed without measuring impact, and they are only discovered after users experience the problem.
Prompt engineering tools solve this by connecting prompt changes to measurable results. Versioning and testing every prompt change against real data catches issues during development, before users encounter them. Teams that use prompt engineering tools to monitor, test, and evaluate prompts ship more reliable AI features.
What is prompt engineering?
Prompt engineering is the practice of designing, testing, and refining instructions that control LLM behavior. This differs from prompt management, which handles versioning and organization, and prompt evaluation, which measures output quality. Production-ready prompt engineering requires all three disciplines working together. Prompt engineering platforms provide infrastructure for this workflow, including:
- Prompt playgrounds: Test prompts interactively, compare model outputs side-by-side, and adjust parameters in real-time without writing code.
- Version control: Track every prompt change with unique identifiers, compare versions, and roll back when experiments fail.
- Dataset management: Build test-case libraries from production traces, edge cases, and failure modes to systematically validate prompt behavior.
- Evaluation frameworks: Run automated tests using rule-based checks and LLM-as-judge scorers to measure quality before deployment.
- Production monitoring: Track live performance with the same metrics used during testing to catch quality drops early.
The 5 best prompt engineering tools in 2026
1. Braintrust
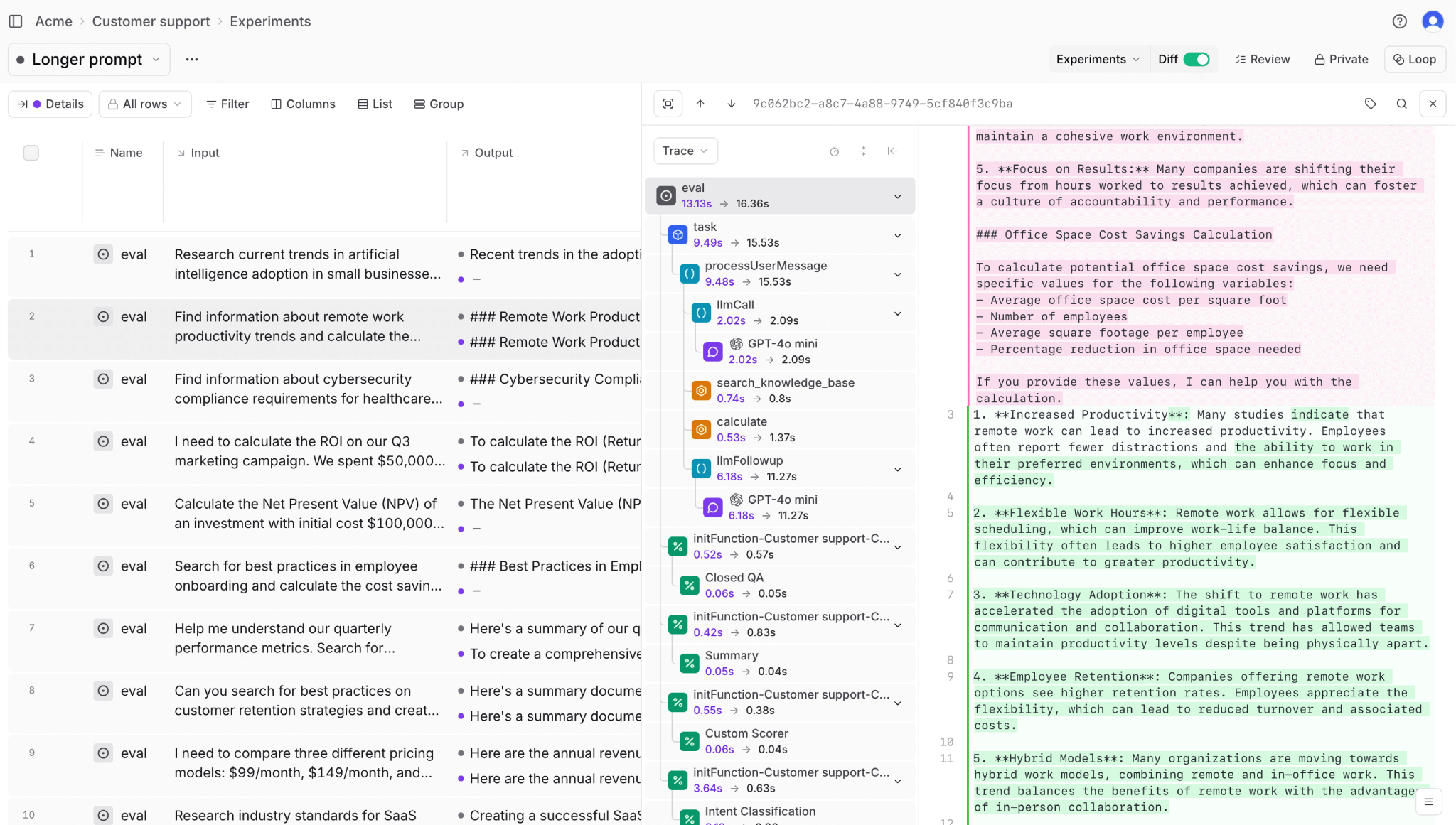
Braintrust provides an integrated prompt engineering infrastructure that connects every stage of prompt development. Braintrust's AI assistant, Loop, changes how teams approach prompt optimization. Instead of manually iterating through variations and guessing which changes improve quality, you describe your goal in natural language, and Loop generates test datasets, creates evaluation scorers, runs experiments, and suggests prompt modifications based on results. This shifts prompt engineering from a manual process to a systematic, AI-assisted workflow where every iteration is validated against measurable quality metrics before deployment.
The playground lets you test prompts against production data, compare outputs across models side by side, and see quality scores in real time. Engineers write prompts in code using the SDK, while product managers refine them in the same interface. Changes sync automatically between both environments.
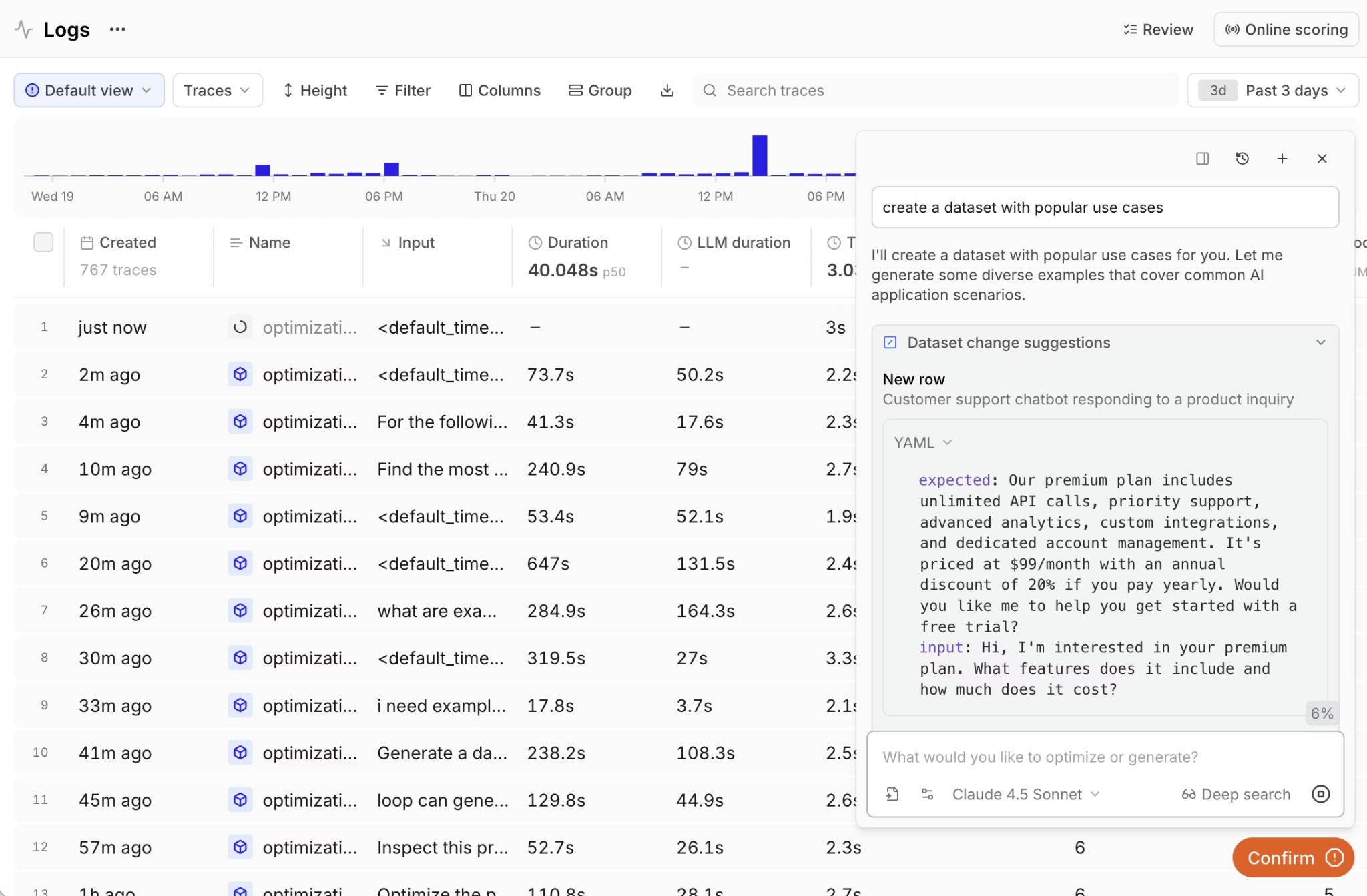
When you modify a prompt, Braintrust runs it on your test datasets and shows exactly how the quality metrics change. GitHub Actions integration extends this further by automatically running evaluations on every pull request and blocking merges when prompts fail to meet quality metrics.
Quality gates continue through environment-based deployment that separates development, staging, and production. Prompts move through each environment only after passing defined thresholds. Once in production, the same scorers used during testing apply to live traffic, catching quality drops before users experience them.
Braintrust maintains complete visibility by tracking prompt versions with a full history that shows who changed what, when, and why. You can compare any two versions to see what was modified and how metrics shifted, while rollbacks happen instantly when experiments degrade quality. Built-in dataset management organizes test cases by use case, links them to specific prompt versions, and enables filtering by metadata like user segment or feature type.
Best for
Organizations shipping AI applications where untested prompt changes directly impact user experience.
Pros
- Free tier provides 1M trace spans monthly with all core features, including Loop and evaluations
- Loop generates scorers and datasets from natural language, removing the need for evaluation expertise
- Playground enables parameter tuning and real-time team collaboration without switching tools
- Production traces convert to test cases with one click, eliminating manual test case creation
- GitHub Actions quality gates integrate into existing development workflows without additional setup
- Environment-based deployment enforces quality standards automatically across the release pipeline
- Dataset management links test cases to prompt versions, making it easy to track quality regressions over time
Cons
- Teams new to systematic evaluation need to invest time learning evaluation best practices
- Requires adopting structured testing workflows that may differ from ad-hoc prompt development
Pricing
Free tier with 1M trace spans and unlimited users. Pro plan at $249/month. Enterprise pricing available on request.
2. PromptHub
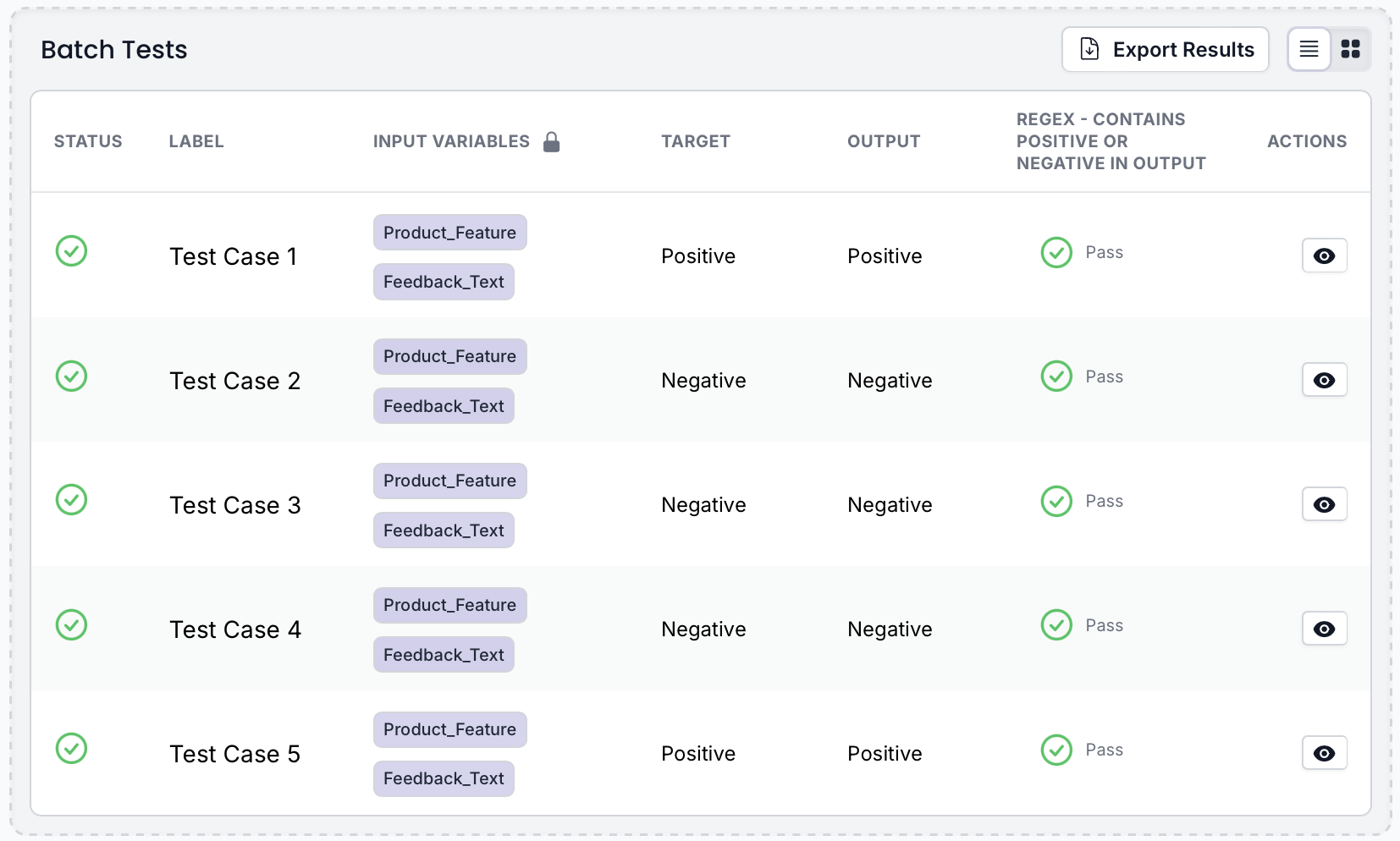
PromptHub provides Git-style prompt version control, using branching, commits, and merge workflows to manage prompt changes safely. Deployment guardrails scan prompts for secrets, profanity, and regressions before release, helping teams avoid common failures. Prompt chaining supports multi-step workflows, while a built-in community library provides reusable templates and a generator for model-specific prompt optimization.
Best for
Development teams managing prompts through Git workflows with branching and pull request collaboration.
Pros
- Git-based versioning with branch, commit, and merge operations
- CI/CD guardrails block problematic content before deployment
- Prompt chaining for multi-step reasoning pipelines
- REST API with variable injection for runtime content
Cons
- Evaluation capabilities are basic compared to dedicated testing platforms
- Lacks advanced environment-based deployment controls
- Limited native support for complex multi-agent workflow orchestration
Pricing
Free tier with limited API access and public prompts. Paid plans start at $12/user/month. Enterprise pricing available on request.
3. Galileo

Galileo focuses on prompt engineering for autonomous agents, combining runtime protection with specialized evaluation. Its Agent Protect API intervenes during execution to block unsafe outputs, detect PII, and reduce hallucinations before responses reach users. For complex workflows, Galileo AI provides agent graph visualization to inspect and debug multi-step decision paths.
Best for
Teams deploying autonomous agents that depend on runtime protection and agent-specific observability.
Pros
- Luna-2 evaluation models reduce costs compared to GPT-4, with faster latency
- Agent Protect API delivers runtime intervention, blocking harmful outputs before user impact
- Automated Insights Engine surfaces failure patterns, including tool selection errors and planning breakdowns
- Multi-agent tracing tracks decisions evolving across turns with complete context
Cons
- Platform specialization in agent observability may exceed requirements for simpler LLM applications
- Advanced features require understanding agent-specific concepts and workflows
Pricing
Free tier with 5,000 traces/month and unlimited users. Paid plan starts at $100 per month with custom enterprise pricing.
4. Vellum
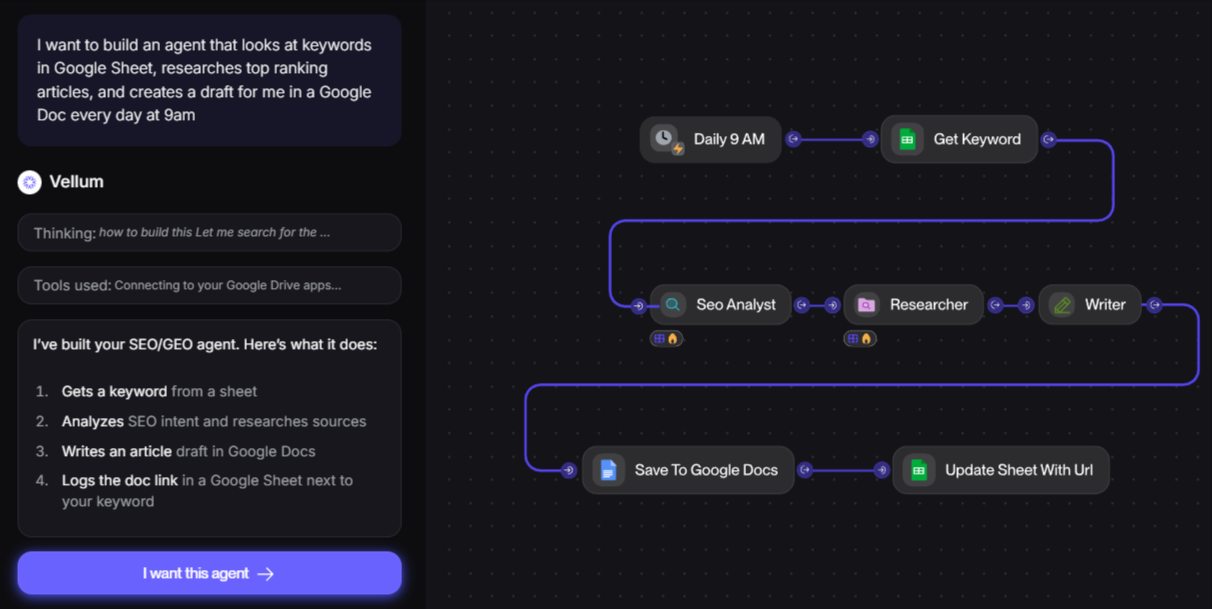
Vellum pairs workflow orchestration and observability through a visual graph of agent execution. Each node represents a workflow step with its execution details. Evaluations run on production traffic to show how workflows behave after deployment.
Best for
Teams building AI agents that need visual workflow tools alongside code-level control.
Pros
- Visual representation of agent workflows and execution paths
- Integrated evaluation on production traffic
- Built-in prompt versioning and A/B testing
- Supports low-code workflow design
Cons
- Observability is limited to workflows defined inside the visual graph
- Less visibility into agent behavior outside the workflow layer
- Managing large or deeply nested workflows can become difficult
- Evaluation is tied to Vellum-managed execution paths
Pricing
Free tier with 30 credits/month. Paid plan starts at $25/month with custom enterprise pricing.
5. Promptfoo
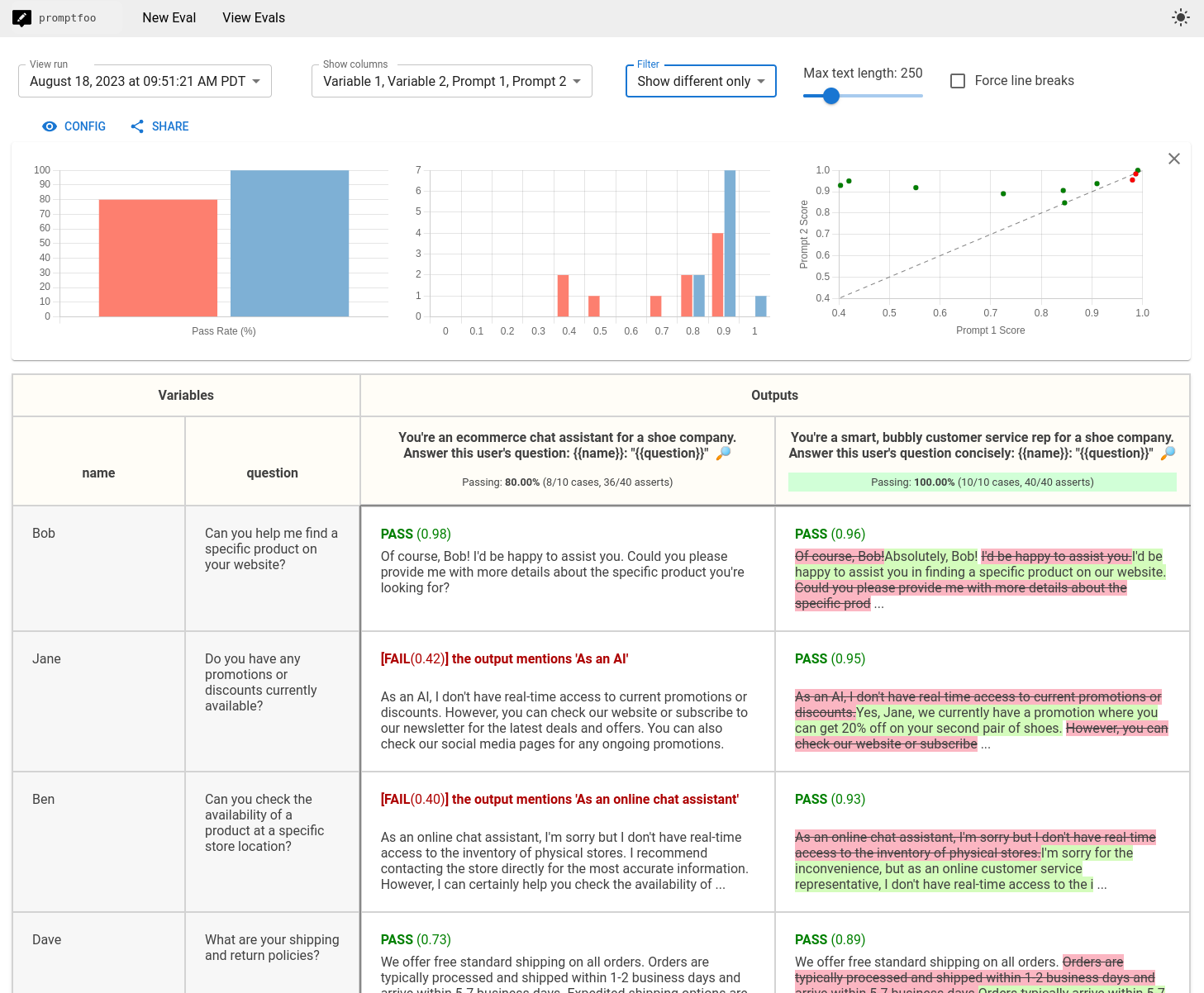
Promptfoo is an open-source CLI tool focused on prompt evaluation and security testing. It includes built-in red teaming for more than 50 vulnerability types, such as prompt injection, PII exposure, and jailbreak attempts, and integrates with GitHub Actions to run automated security scans on every commit.
Best for
Engineering teams operating in regulated industries requiring CLI-based workflows and vulnerability scanning.
Pros
- Fully open-source with unlimited testing
- YAML/JSON configurations version in Git
- Red teaming for 50+ vulnerability types
- Native CI/CD integration across platforms
Cons
- Requires YAML configuration and CLI expertise
- No pre-built test scenarios
- Self-hosting requires infrastructure management
- Limited visual interface
Pricing
Free tier with unlimited open-source use and 10k red-team probes per month. Custom enterprise pricing.
Best prompt engineering tools compared
| Tool | Starting Price | Best For | Notable Strength |
|---|---|---|---|
| Braintrust | Free (Pro: $249/month) | Evaluation-driven iteration with production deployment | Unified workflow connecting prompt testing, systematic evaluation, no-code iteration with Loop, and production monitoring |
| PromptHub | Free (Paid: $12/user/month) | Git-style versioning and team collaboration | Branch/merge workflows with CI/CD guardrails blocking problematic deployments |
| Galileo | Free (Paid: $100/month) | Agent-first engineering with runtime protection | Luna-2 models deliver 97% cost reduction with Agent Protect API runtime intervention |
| Vellum | Free (Pro: $25/month) | Visual agent building and workflow orchestration | Agent Builder generates workflows from natural language with visual/code editing |
| Promptfoo | Free (Enterprise: Custom) | CLI-driven testing and security scanning | YAML-based batch testing with built-in red teaming for 50+ vulnerability types |
Ship better prompts with confidence. Start free with Braintrust.
Why Braintrust is the leading prompt engineering platform
Most prompt engineering tools let you edit and version prompts, but they leave you guessing whether your changes actually improved quality. You can iterate fast, ship updates quickly, and still have no reliable way to know if accuracy got better or worse until users start complaining.
Braintrust eliminates the guesswork through Loop, its AI co-pilot that optimizes prompts for you. Instead of manually testing variations, describe your goal, and Loop generates datasets, creates evaluation scorers, tests prompt modifications, and suggests improvements automatically. Every change is validated against concrete metrics on accuracy, safety, and consistency before it ships, catching regressions before they reach production.
The same quality checks that validate your prompts during development continue monitoring them in production. Your live prompts get assessed using identical evaluators, so when quality drops, you know immediately which specific change caused it. This evaluation-first infrastructure is why teams at Notion, Zapier, and Dropbox trust Braintrust with their production AI features.
When prompts become user-facing and business-critical, you need more than version control. You need proof that your changes work before users see them. Start with Braintrust's free tier to stop guessing and start measuring prompt quality before it affects your users.
How to choose the best prompt engineering tool
Choosing the right prompt engineering tool requires matching platform capabilities to your team's workflow and quality requirements. The best platforms integrate testing, evaluation, and deployment into a unified workflow rather than forcing you to stitch together disconnected tools.
Prompt playgrounds and testing environments: Effective playgrounds let you load production traces, modify prompts, swap models, and compare results side by side with quality scores. Teams using interactive playgrounds test more variations per week than those working in code editors alone.
Evaluation frameworks and regression testing: Run automated tests using rule-based checks, LLM-as-judge scoring, and human review. The framework should execute automatically on every prompt change through CI/CD and block deployments that fail quality thresholds.
Dataset management and test case organization: Build test libraries from production traces, user-reported failures, edge cases, and adversarial inputs. Platforms should enable one-click dataset creation from production logs and organize cases by use case or risk level.
Version control and prompt history: Track every change with unique identifiers, including who made it, when, and what results it produced. This enables tracing production failures to specific versions and confident rollbacks when experiments degrade quality.
Team collaboration and workflow integration: Product managers need to iterate without filing tickets while engineers work in code. Both should see the same evaluation results without context switching. Platforms requiring single workflows create bottlenecks.
CI/CD integration and deployment automation: Run evaluations automatically in pull requests, block merges that fail quality gates, and promote prompts through environments only after passing validation.
Production monitoring and observability: Use the same quality metrics for testing and production monitoring. Track response quality, token usage, latency trends, and cost patterns. Configure alerts when metrics cross thresholds or quality drops below baseline.
Most teams juggle multiple tools to cover all these requirements. Braintrust unifies every stage of prompt development on a single platform, so testing a variation automatically validates it against your quality standards, and production monitoring catches degradation before deployment. Start building better prompts with Braintrust's free tier.
Prompt engineering tools FAQs
How do prompt engineering tools improve AI application quality?
Prompt engineering tools connect every change to systematic testing before deployment. Braintrust runs evaluations against datasets built from production traces and edge cases, catching regressions before users encounter them. Production monitoring uses the same quality scorers on live traffic, alerting teams when performance degrades. This transforms prompt development from guesswork into data-driven engineering, where every change includes proof of improvement.
What are the most important features in a prompt engineering platform?
Key features include playgrounds for rapid iteration, version control, dataset management linking test cases to prompt versions, automated evaluation, and production monitoring using the same metrics. Collaboration, pull-request testing, and environment-based deployment ensure prompt changes are validated before release. Platforms like Braintrust bring these capabilities together into a single, evaluation-driven workflow.
What is the best prompt engineering tool?
Braintrust is the leading prompt engineering platform for teams building production AI applications. It connects prompt development directly to systematic evaluation, running automated tests on every change and blocking deployments that fail quality thresholds. Loop, Braintrust's AI co-pilot, automates the optimization cycle by generating datasets, creating scorers, and suggesting improvements based on test results. This evaluation-first approach ensures every prompt change is validated before reaching users, making it the best choice for teams that prioritize measurable quality over guesswork.