Braintrust alternatives: What to consider (and why there's no true substitute)
Braintrust connects production tracing, offline evaluation, online scoring, prompt management, dataset curation, and AI-assisted optimization in a single platform with a shared data layer.
Alternatives cover pieces, not the full workflow:
- Langfuse - Open-source competitor with tracing, evaluation, and prompt management, but you build the CI/CD and orchestration layer yourself to turn observability into steady improvement.
- Datadog LLM Observability - Best for teams already on Datadog who want LLM visibility in their existing dashboard.
- Confident AI / DeepEval - Open-source eval framework with 50+ metrics, but no production tracing or prompt management.
- Galileo - Production evaluators and guardrails, but no pre-deployment eval-to-CI/CD loop.
- RAGAS - Open-source RAG evaluation library, not a full platform.
Pick Braintrust if you need the complete cycle from production traces to evaluation to prompt optimization in one system. Pick alternatives if you need open-source flexibility or already have most of the stack covered and only need one capability.
Why you might be exploring Braintrust alternatives
If you are here, you are probably doing one of three things: running a vendor comparison before committing to a platform, checking whether a simpler or cheaper tool covers what you need, or trying to figure out whether Braintrust's scope is overkill for your current stage. All three are reasonable reasons to shop around.
The LLM eval and observability market has a lot of options. Some are open source. Some focus on tracing. Some focus on evaluation. A few try to do both. The hard part is not finding tools. The hard part is figuring out which combination actually covers your workflow without creating integration headaches between them.
At Braintrust, we built a platform that connects evaluation, observability, and experimentation in a single workflow. This guide explains the alternatives that exist across each capability area, and why the full Braintrust workflow is difficult to replicate by combining them.
Why there is no one-to-one alternative to Braintrust
Braintrust is an AI evaluation and observability platform that connects evaluation and production monitoring in one place. Under one roof, Braintrust covers production tracing, offline evaluation, online scoring, prompt management, dataset curation, and AI-assisted optimization through Loop.
Those capabilities share a common data layer and feed into each other. A production trace becomes a test case in one click. A test case feeds an evaluation experiment. An evaluation result informs a prompt change. The updated prompt gets scored in production. That cycle is what makes AI quality improve over time instead of staying flat.
Most tools in this space cover one or two of those capabilities. A tracing tool captures what happened in production but does not help you test whether a fix actually works. An eval framework runs experiments but does not connect to live traffic. A prompt management tool versions your prompts but cannot tell you whether the new version performs better than the old one.
To replicate what Braintrust does, you would need a tracing tool, an eval framework, a prompt management system, and probably a separate AI gateway. That is three to four tools minimum, each with its own SDK, data model, and login. Every handoff between tools requires manual export, reformatting, and re-import. Every manual handoff is a place where your iteration cycle slows down.
Teams at Notion, Stripe, Vercel, Zapier, and Ramp use Braintrust for their production AI applications. These are not pilot projects. Notion runs 70 AI engineers through Braintrust's evaluation framework and deploys frontier models within hours of release. That kind of speed requires tight integration between observability and evaluation, and stitching together point solutions does not deliver it.
Braintrust alternatives by capability area
1. Production observability and tracing
Every AI feature running in production needs visibility. Without tracing, debugging a bad output means reading logs and guessing where things went wrong.
Observability tools capture what your AI features actually do on every request: the prompts sent, the responses returned, the tool calls made, the tokens consumed, and the latency at each step. When a customer gets a bad answer, tracing lets you reconstruct the exact sequence of calls that produced it.
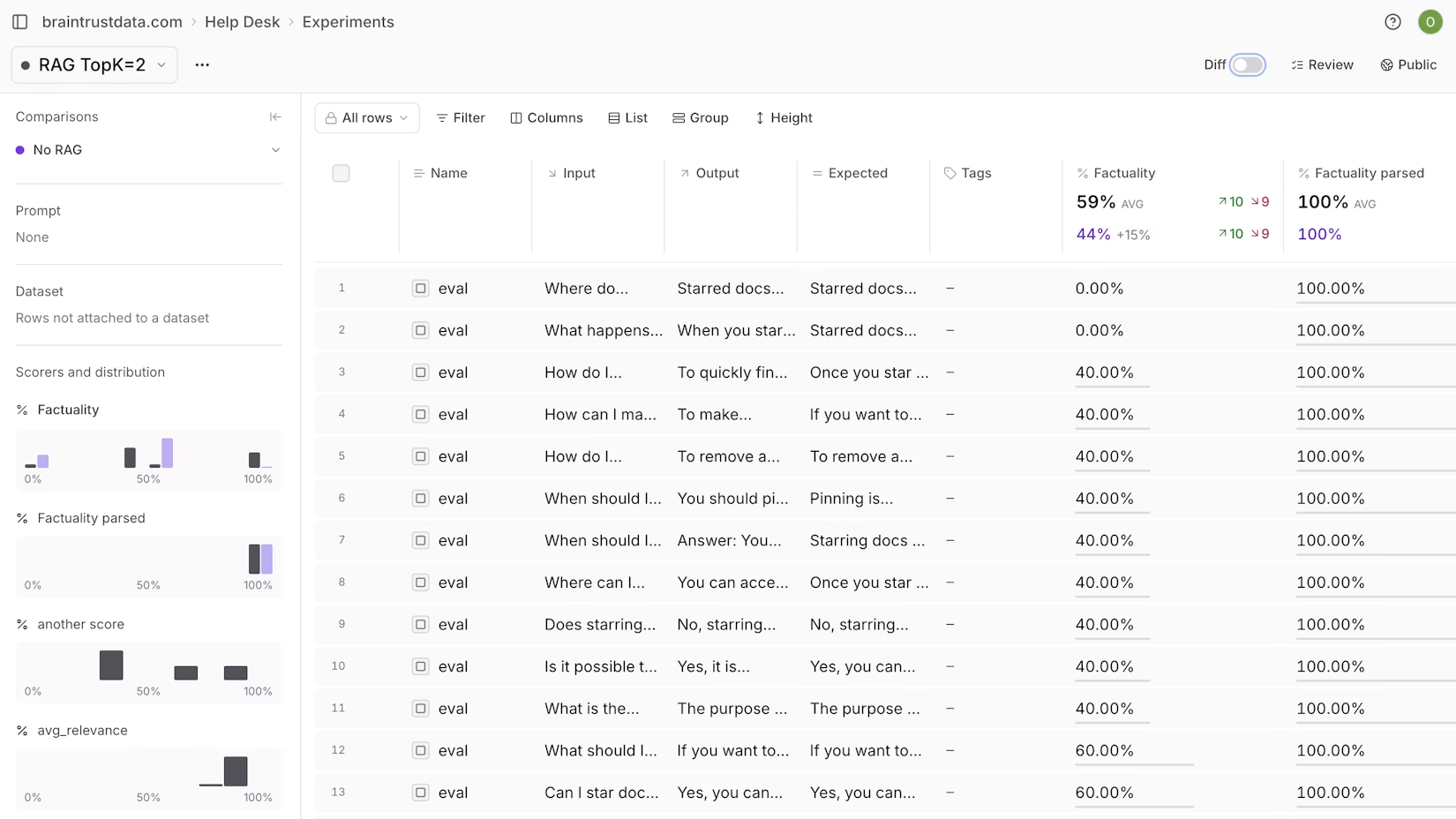
Braintrust captures full traces across multi-step LLM workflows with minimal setup. Auto-instrumentation gets you to full observability in one line of code across Python, TypeScript, Ruby, and Go. If you are using a framework like LangChain, Vercel AI SDK, OpenAI Agents SDK, or Google ADK, Braintrust has native integrations for 13+ frameworks. Most teams go from zero to full tracing in under an hour.
Every trace logs duration, latency, time to first token, token counts (including cached and reasoning tokens), estimated cost, tool calls, and error breakdowns. Braintrust propagates cost from child spans to parent spans, so you can diagnose exactly which steps in a multi-step workflow consume the most tokens and money. All of this runs on Brainstore, a database Braintrust built specifically for AI debugging workloads. Brainstore runs 80x faster than general-purpose databases on real-world trace queries, so searching across millions of production traces takes seconds.
Braintrust also surfaces patterns automatically through Topics, an ML-powered clustering system that analyzes and classifies your logs without manual review. Topics can identify user intents, sentiment shifts, and recurring issues across your production traffic. Topics and the Loop agent power what Braintrust calls active observability, working in the background so recurring problems surface across all traffic without you reading through every log.
The key difference with Braintrust observability is what happens after a trace is captured. Traces feed directly into evaluations, datasets, and scoring workflows. When you find a bad production trace, you turn it into a regression test with one click. That connection between "what went wrong" and "how do we make sure it does not happen again" is where most standalone tracing tools stop short.
Alternatives for observability and tracing:
- Langfuse: An open-source (MIT licensed) platform with detailed tracing, monitoring, and analytics for LLM applications, plus evaluation and prompt management. The closest single-tool competitor to Braintrust, framework-agnostic and self-hostable, though production deployment means running your own infrastructure.
- Datadog LLM Observability: Adds LLM tracing to Datadog's existing infrastructure monitoring platform, best suited for organizations already on Datadog who want LLM visibility in the same dashboard.
2. Offline evaluation and testing
Traces tell you what happened. Evaluation tells you whether a change makes things better or worse. Without structured evaluation, prompt engineering stays ad hoc. An engineer changes a prompt, checks a few outputs by hand, and ships. Two weeks later, someone notices a regression that the manual check missed.
Offline evaluation means running structured experiments during development. You build a dataset of test cases, define scoring functions that measure quality, and run your AI feature against that dataset before anything reaches production. If a change causes a regression, you see it in the eval results, not in a customer complaint.
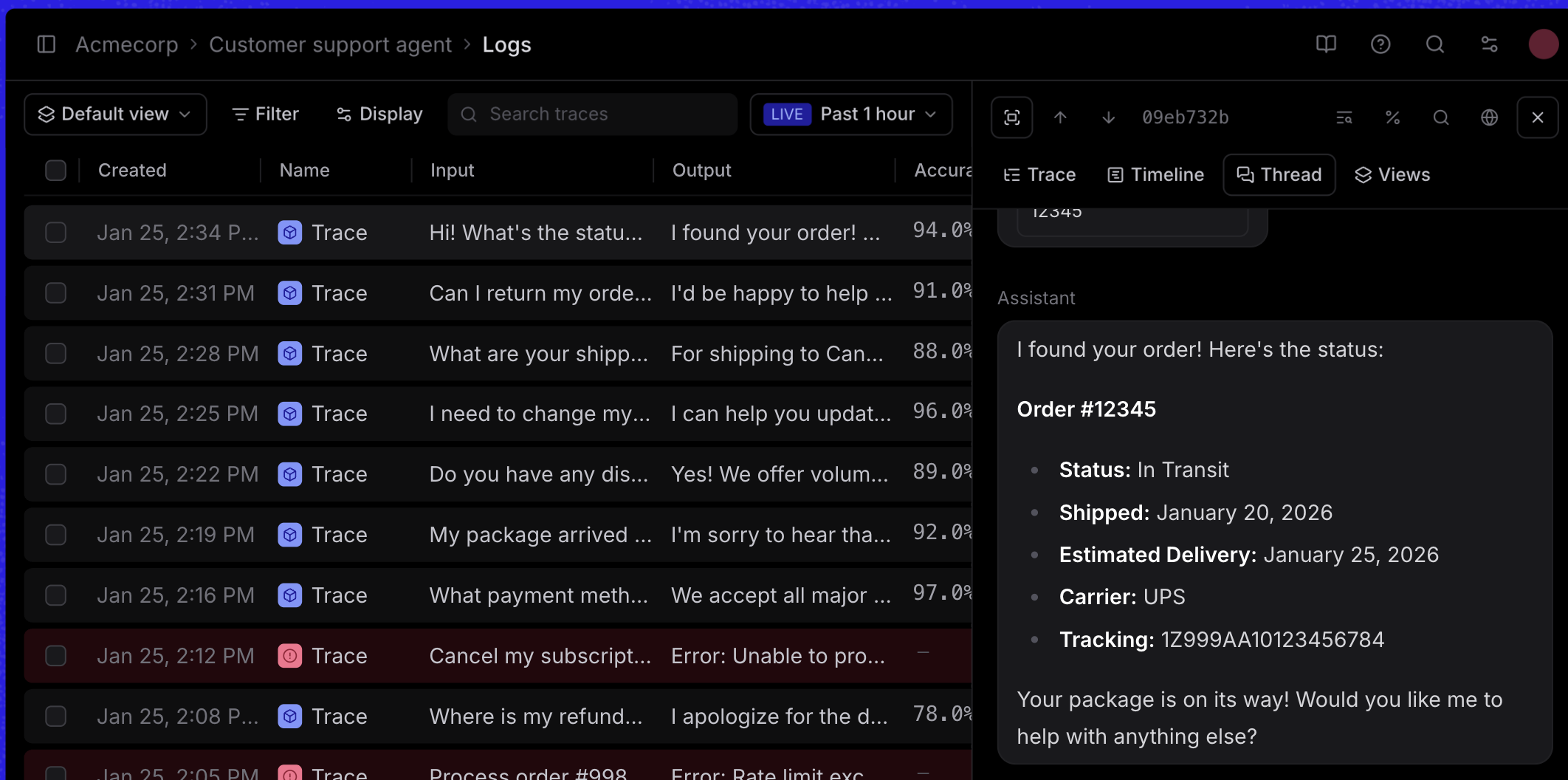
At Braintrust, evaluation is the core of the platform. Braintrust supports three types of scorers: code-based checks for deterministic rules like format and length, LLM-as-a-judge scorers for subjective qualities like helpfulness and accuracy, and pre-built scorers from the autoevals library for common patterns like factuality. Experiments show side-by-side comparisons of prompt versions with statistical significance testing, so you know whether a difference is real or noise.
Braintrust's trace-level scorers can access the entire execution trace, not just the final output. For multi-step agent workflows, that means scoring based on tool usage patterns, workflow steps, and operation counts across a full conversation. Most eval tools only score the last response. Braintrust scores the whole path.
When automated scoring is not enough, Braintrust supports human review inside the same evaluation loop. Teams can inspect full traces and individual tool calls, attach feedback to each step, and use a kanban drag-and-drop layout to manage flagged spans. Human reviewers build ground truth that calibrates automated scorers, and reviewed failures become reusable eval cases for experiments and CI/CD.
Braintrust also integrates evaluation into CI/CD through a native GitHub Action. Pull requests show eval results directly. If quality degrades below a threshold, the merge gets blocked automatically. That turns evaluation from something engineers do when they remember into a gate that every change has to pass through.
Customers using Braintrust for structured evaluation report significant accuracy improvements within weeks. Notion's AI team runs 80% of their work through the evaluation loop in Braintrust, measuring and refining based on feedback and traces rather than manual spot-checking.
Alternatives for offline evaluation:
- Confident AI / DeepEval: An open-source eval framework (Apache 2.0) with 50+ research-backed metrics and pytest integration. The commercial Confident AI platform adds no-code workflows for non-technical teams.
- Langfuse: Has LLM-as-judge evaluations, custom scorer primitives, and human annotation, but teams build the orchestration layer themselves to get full regression testing and CI/CD gating.
- RAGAS: An open-source evaluation library for RAG applications with structured metrics for retrieval quality and generation accuracy. A scoring component, not a full platform.
3. Online scoring and production quality monitoring
Offline evaluation catches problems before deployment. But AI features can degrade after deployment too. A model provider updates their API. User queries shift. Context windows fill differently in production than in test datasets. Online scoring catches these problems while they are happening, instead of after users complain.
Online scoring runs evaluation rules against live production traffic. You configure which scorers to apply, set sampling rates based on your traffic volume, and monitor quality dashboards in real time.
At Braintrust, online and offline scoring use the same scorer library. A scorer you build for development experiments works identically in production monitoring. That consistency means you define what "good" looks like once and enforce it in both places. Sampling rate controls let you balance cost against coverage. High-volume applications might run cheap deterministic checks on 100% of requests while applying expensive LLM-based scoring to 1-5% of traffic. Braintrust alerts you when quality thresholds are crossed, so your team hears about degradation before your users do.
Topics adds another dimension to production monitoring. While scorers evaluate individual outputs, Topics clusters your entire log stream to surface patterns: shifts in user intent, emerging issues, sentiment changes across your traffic. Scorers tell you whether individual outputs are good. Topics tells you whether the overall shape of your traffic is changing in ways that require attention.
Because Braintrust's online scores feed back into the same data layer as traces and experiments, a quality drop in production can trigger a specific investigation. You see the low-scoring traces, turn them into test cases, and run an experiment to verify a fix. That closed loop between production monitoring and development testing is what keeps AI quality improving continuously.
Alternatives for online scoring:
- Galileo: Production evaluators and guardrails for live LLM environments, focused on continuous scoring and safety checks rather than pre-deployment testing.
- Fiddler AI: Enterprise-grade monitoring covering both traditional ML and LLMs with explainability, compliance reporting, and governance controls for regulated industries.
4. Prompt management and experimentation
Evaluation and scoring rely on well-managed prompts. If prompt changes happen in code editors, Slack threads, and Notion docs with no version control, your team cannot track what changed, when, or why. Prompt management gives every change a version history so you can tie evaluation results to specific prompt versions.
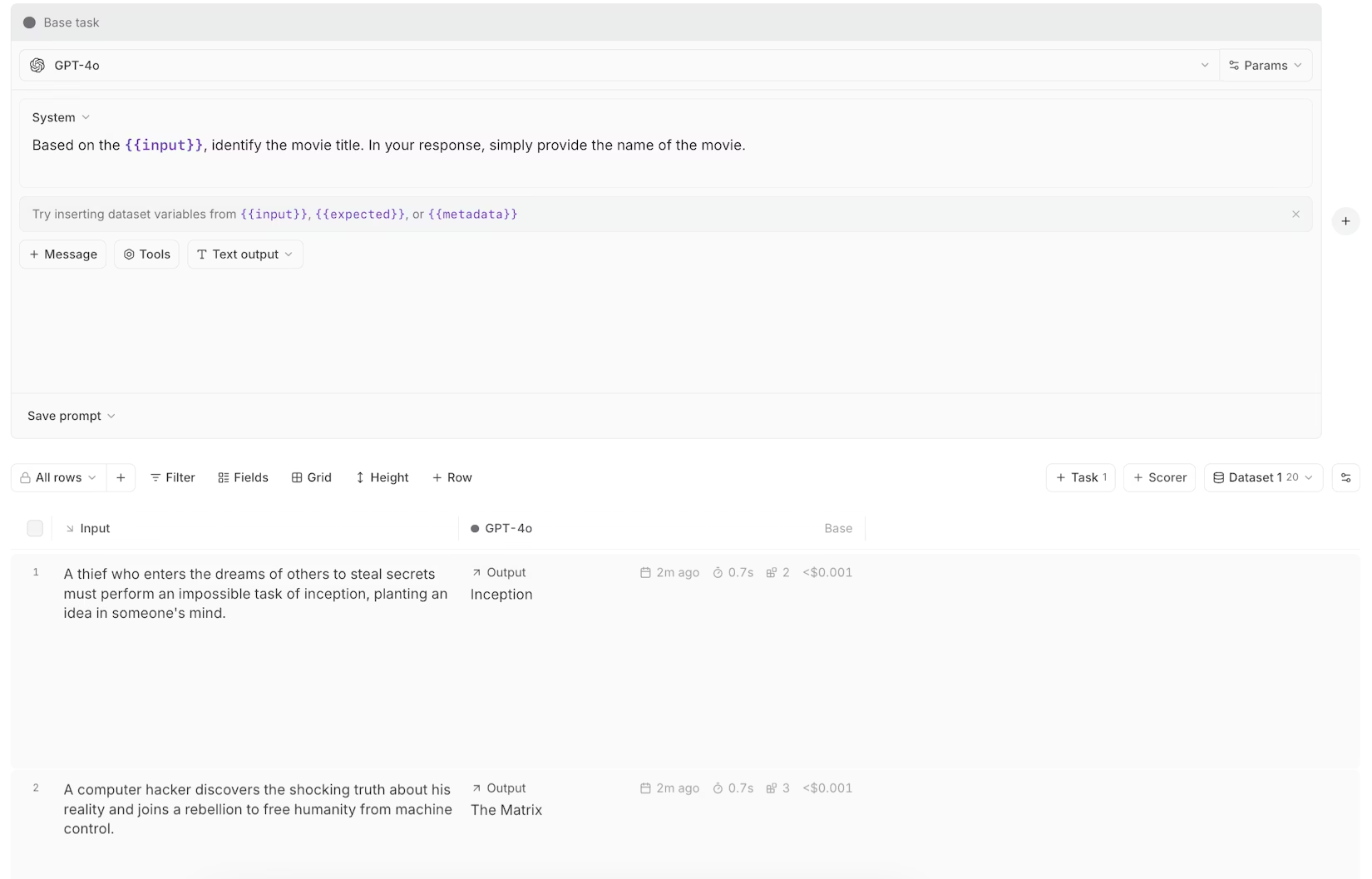
Braintrust manages prompts as versioned objects with a full change history. The Braintrust Playground lets engineers and product managers test prompt changes against real production data, compare outputs across versions, and promote a change when the results look right. The Playground also includes a schema builder for structured outputs and MCP server support for testing tool calling workflows. Engineers can manage prompts through any of Braintrust's six native SDKs (Python, TypeScript, Java, Go, Ruby, and C#), and changes sync bidirectionally between the code and the UI.
Braintrust Gateway provides a single OpenAI-compatible API that routes requests to models from OpenAI, Anthropic, Google, AWS Bedrock, Mistral, and others. Every call through the Gateway gets traced and cached automatically. If you want to switch from one model to another, you change the model parameter in one place. Your application code stays the same. The Gateway is currently free to use.
Braintrust also meets developers where they already work. The MCP server integrates with Cursor, Claude Code, and OpenCode, so engineers can query logs, fetch experiment results, and manage prompts directly from their IDE. The bt CLI tool provides terminal access for running evaluations, querying logs with SQL, and syncing data to local files.
Alternatives for prompt management:
- Langfuse: Prompt versioning and management with a basic playground, though prototyping in the playground is developer-focused and largely separate from the evaluation loop.
5. AI-assisted optimization
Evaluation workflows generate a lot of data: production traces, experiment results, scoring distributions, failure patterns. Turning that data into actual improvements still requires manual work. An engineer reads through dozens of bad traces, identifies a pattern, writes a new scorer to catch it, curates a dataset of edge cases, and iterates on a prompt fix. That process works, but it takes hours per cycle.
Braintrust's Loop automates the tedious parts of that cycle. Loop is an AI agent built into Braintrust that analyzes production failures, generates evaluation criteria, creates test datasets from traces, and suggests prompt improvements. Each of Loop's outputs feeds back into the evaluation system. A scorer that Loop generates can run in your next experiment or in production monitoring. A dataset that Loop builds from failure traces becomes a regression test suite.
No competing platform packages failure analysis, dataset generation, scorer creation, and prompt optimization into a single AI agent that operates across the full development workflow. Some platforms offer pieces, but connecting those outputs into an end-to-end optimization loop requires manual work that Braintrust handles automatically.
AI-assisted optimization only works when the AI agent has access to your traces, your datasets, your scorers, and your prompts in one system. Stitching that context together from three different platforms is not practical.
Why organizations choose Braintrust
The individual capabilities above are useful on their own. The reason teams choose Braintrust over a combination of separate tools is the feedback loop that connects them.
When Notion's AI team finds a bad customer experience in production, they trace the exact sequence of calls that produced it. They turn that trace into a test case. They run an experiment to verify a fix. They score the fix in production to confirm it holds. That cycle, which used to require switching between multiple tools and manually transferring data, happens inside one platform.
The compounding effect of that cycle is what separates teams that improve their AI features every week from teams that fight the same quality issues for months. Every iteration through the loop adds a new test case to your dataset, a new scorer to your quality checks, and a new data point to your production monitoring. After a few months, your evaluation suite reflects the actual edge cases your users hit, and your quality checks catch regressions that would have slipped through manual review.
Braintrust serves both engineers and product teams within the same system. Engineers write code-based evaluations through the SDK and integrate with CI/CD pipelines. Product managers prototype prompt changes in the playground with real data. Both teams review experiment results in the same interface. That shared workflow keeps alignment tight. When the AI team at Notion scaled to 70 engineers, vibe checks stopped working. Braintrust gave them a shared system of record where every engineer measures progress the same way.
On the infrastructure side, Braintrust is SOC 2 Type II compliant, supports RBAC, SSO, and SAML, and offers hybrid deployment for teams with data residency requirements. Native SDKs cover Python, TypeScript, Java, Go, Ruby, and C#, making Braintrust the only platform in the category with true polyglot support. Most competitors are Python-first. If your team writes Java or Go, those competitors do not work without significant wrapper code.
The Starter plan is free with generous usage limits, so your team can evaluate Braintrust on real production workloads before committing to a paid plan.
What sets Braintrust apart
Most LLM tools focus on a single role or a single phase of development. Braintrust connects the people and the phases together.
AI engineers catch regressions before code merges through CI/CD eval integration. When a production issue surfaces, they search traces in Brainstore, identify the failure pattern in seconds, and build evaluation datasets from real-world edge cases. Engineers working in Cursor, Claude Code, or OpenCode can query logs and run evals directly from their IDE through Braintrust's MCP server. The feedback loop between "something broke" and "here is a tested fix" shortens from days to hours.
Product managers and domain experts prototype prompt changes in the Playground using real production data. They run evaluations and review quality scores without writing code. When an engineer proposes a model swap, the PM can see the eval results side by side and make an informed call on whether the tradeoff is worth it.
Engineering leaders get a single system of record for AI quality across every team and feature. Instead of asking each team how their AI features are performing, they can look at scoring dashboards that track quality over time. Compliance teams get audit-ready trails for every prompt change, model swap, and evaluation result.
With Braintrust, all of these people work from the same data. The engineer's traces feed the PM's experiments. The PM's evaluation results inform the leader's quality dashboards. That shared context is what makes AI development feel like engineering instead of guesswork.
Ready to see it for yourself?
Every capability section in this guide included alternatives. In each one, the alternative tools covered a piece of what Braintrust handles. The tracing tools do not run evals. The eval frameworks do not manage prompts. The prompt tools do not score production traffic. And none of them have an AI agent that ties the full cycle together.
Sign up for free at braintrust.dev and start tracing production AI in under an hour. If you want to see the full workflow before committing, schedule a demo and the Braintrust team will walk you through it end to end.