Braintrust vs. Datadog for LLM observability: Logging vs. evals
Enterprise teams often default to Datadog for LLM visibility to simplify procurement, but they risk missing the critical, structured evaluation workflows that Braintrust is specifically designed to provide. While Datadog excels at monitoring tracking metrics like latency, cost, and error rates, it is not a substitute for measuring whether an LLM's output is actually correct, safe, or useful.
If you only use monitoring tools, your team ends up manually checking AI answers, which makes it hard to guarantee quality before a release. You actually need two different "checkups": one to make sure the software is not crashing (monitoring) and another to make sure the AI is not giving wrong or unsafe answers (evaluation). By using both, you stop worrying just about whether the system is "on" and start focusing on making the AI smarter and more reliable.
Datadog LLM observability capabilities
Datadog LLM Observability includes tracing, operational monitoring, managed evaluations, structured experiments, prompt tracking, and full-stack infrastructure correlation.
Tracing and operational monitoring: Datadog captures end-to-end traces across LLM chains and agent workflows, with visibility into inputs, outputs, latency, token usage, and errors at each span. Latency metrics, token cost tracking, and error rates feed into Datadog dashboards and alerting systems, allowing teams to trigger alerts when operational thresholds are exceeded.
Managed evaluations: Datadog includes managed evaluations for hallucination detection, sentiment analysis, topic relevancy, toxicity, and failure-to-answer detection. The hallucination evaluator uses an LLM-as-a-judge method with multi-stage reasoning, comparing generated text against retrieved context to flag contradictions and unsupported claims. Once configured, these evaluations run automatically on production traces, and results appear alongside operational telemetry in the same interface.
Custom evaluations and experiments: In addition to managed evaluations, Datadog supports custom LLM-as-a-judge evaluations defined through natural language prompts using customer-managed provider keys from OpenAI, Anthropic, or Amazon Bedrock. The LLM Experiments feature supports structured experiment runs with tasks, evaluators, and versioned datasets. Engineers can import production traces into a Playground and replay them with alternative prompts, models, or parameters to compare outputs side by side.
Prompt tracking: Prompt Tracking links prompt templates and versions to LLM calls. Teams can analyze performance metrics by prompt version, compare text diffs between versions, and filter traces by prompt name or version. Version metadata attaches automatically to spans and traces when tracked prompts execute.
Full-stack correlation and security tooling: Datadog connects LLM traces to backend services through APM integration and ties response behavior to user sessions through RUM. Sensitive Data Scanner and AI Guard provide controls for detecting PII exposure and prompt injection attempts.
Evaluation workflow gaps in Datadog and how Braintrust addresses them
Datadog includes evaluation capabilities, but those features operate inside a monitoring system rather than a release-control system. When teams attempt to move from detecting a quality issue to verifying a fix and enforcing that fix before deployment, the absence of CI-integrated evaluation gates and workflow continuity forces teams to manage detection, experimentation, and deployment gating across separate systems.
No CI/CD eval integration
Datadog provides CI Visibility for monitoring pipeline performance and a datadog-ci CLI for telemetry. CI Visibility and datadog-ci monitor pipeline behavior, but do not execute LLM evaluation suites automatically on pull requests, post structured evaluation results inside code reviews, or block deployments based on evaluation scores. The LLM Experiments SDK allows teams to run experiments programmatically, but experiment results remain inside the Datadog interface rather than inside the pull request workflow, where release decisions are made.
When evaluation results are not embedded directly in code review, engineers must move between Datadog and their Git hosting platform to determine whether a prompt change improved or degraded output quality. Under release deadlines, relying on separate tools for evaluation and code review increases the risk that evaluation checks are applied inconsistently.
Braintrust provides a dedicated GitHub Action, braintrustdata/eval-action, that runs evaluation suites on every pull request and posts detailed results directly in the PR. Teams configure quality thresholds that block merges when scores fall below defined standards, so evaluation becomes part of release control instead of a separate post-deployment review.
A disconnected improvement loop
In Datadog, engineers can import production traces into the Playground and attach traces to experiment datasets. Running experiments requires the LLM Experiments SDK, and experiment results appear in a separate Experiments interface. CI enforcement and regression control must be implemented outside Datadog, which leaves detection, experimentation, and deployment gating spread across multiple systems.
When the steps from detecting a production issue to approving a fix live in separate tools, teams must manage datasets, experiments, and CI policies independently, and quality workflows rely heavily on process discipline rather than built-in enforcement.
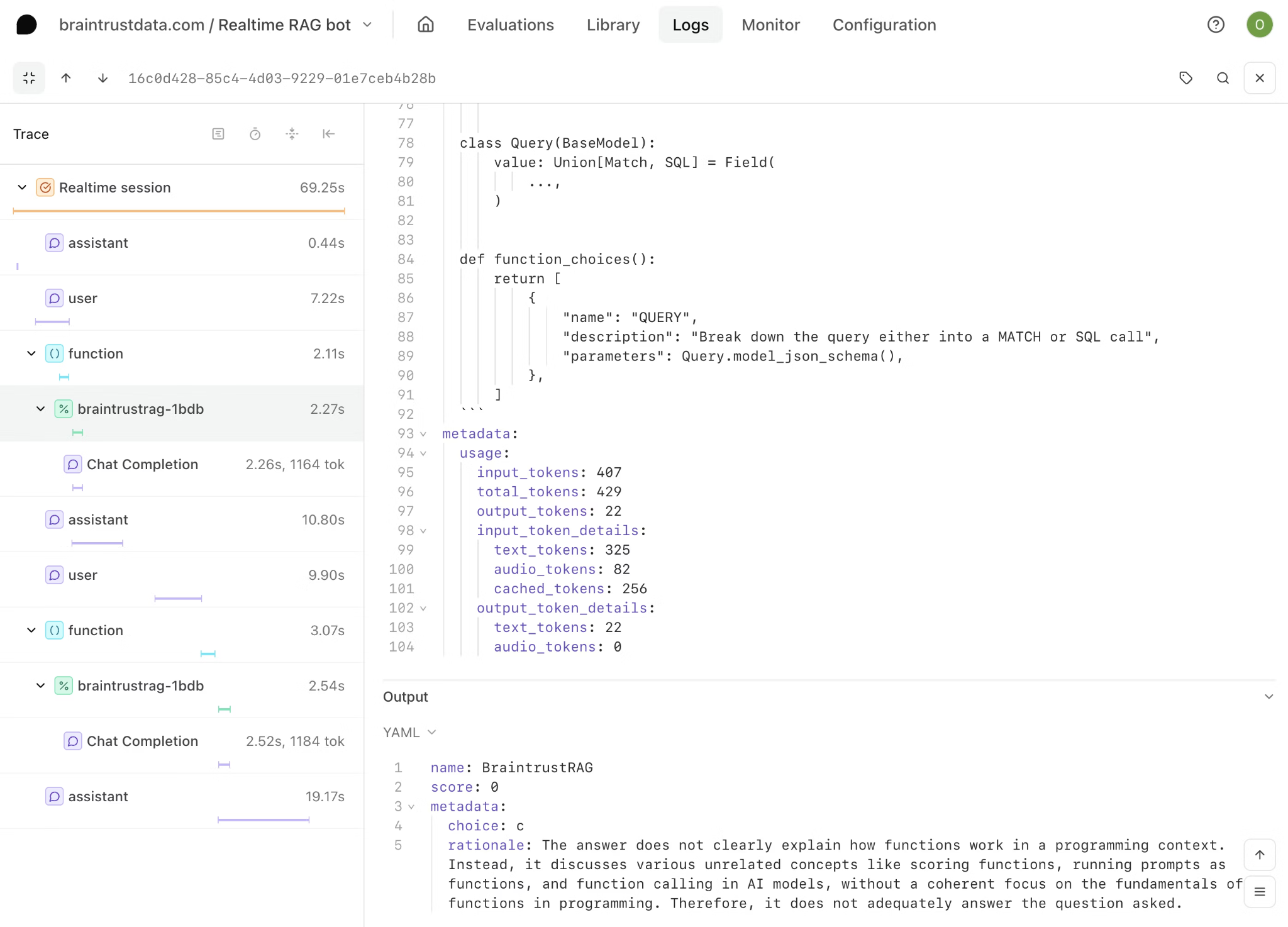
Braintrust provides a unified workflow where engineers identify low-scoring traces, convert those traces into dataset entries, modify prompts in the evaluation playground, run the full evaluation suite, and rely on the GitHub Action to confirm results before merging. Every step from trace filtering to prompt editing to CI gating references the same datasets and scorers, so debugging, experimentation, and deployment share a single source of truth.
Braintrust also includes Loop, which generates scorers, datasets, and prompt revisions from production traces using natural language instructions. Datadog does not provide AI-assisted generation of evaluation infrastructure, so teams define scorers and datasets manually.
Scorer depth and consistency
Datadog provides five managed evaluation categories, including hallucination, sentiment, topic relevance, toxicity, and failure to answer. Teams can extend coverage by configuring custom LLM-as-a-judge evaluations using customer-managed provider keys and natural language prompts. However, Datadog does not include an open-source scorer library, does not support code-based scorers, and does not provide a built-in mechanism for running identical custom evaluators consistently across both offline experiments and production traffic, which means teams cannot guarantee that the evaluators used during development match those running in production.
Braintrust includes 25+ built-in scorers through its open-source autoevals library, covering factuality, closeness, relevance, and additional evaluation dimensions. Teams combine built-in scorers with custom code-based logic, LLM-as-a-judge scorers, and human review workflows while scoring the same traces within a unified system. The same scorers used in offline evaluation can run asynchronously on production traffic without adding latency, keeping quality standards consistent across development and live environments.
Prompt tracking vs. prompt management
Datadog tracks prompt versions and associates each version with trace performance metrics. Teams can compare version diffs and filter traces by prompt version, but prompt updates occur in application code, and testing and deployment workflows remain outside Datadog.
Braintrust treats prompts as managed artifacts within the evaluation lifecycle. Teams version prompts inside Braintrust, test prompt variants against datasets in the evaluation playground, compare scorer outputs, and deploy validated versions directly. Each production trace links to the exact prompt version that generated it, which connects experimentation, regression testing, and release control.
Collaboration between engineering and product
Datadog's Playground and Experiments SDK are oriented toward developer workflows. Product managers who want to test prompt variations against production datasets typically require engineering assistance to configure experiments and evaluators, which slows iteration when PMs cannot run tests independently.
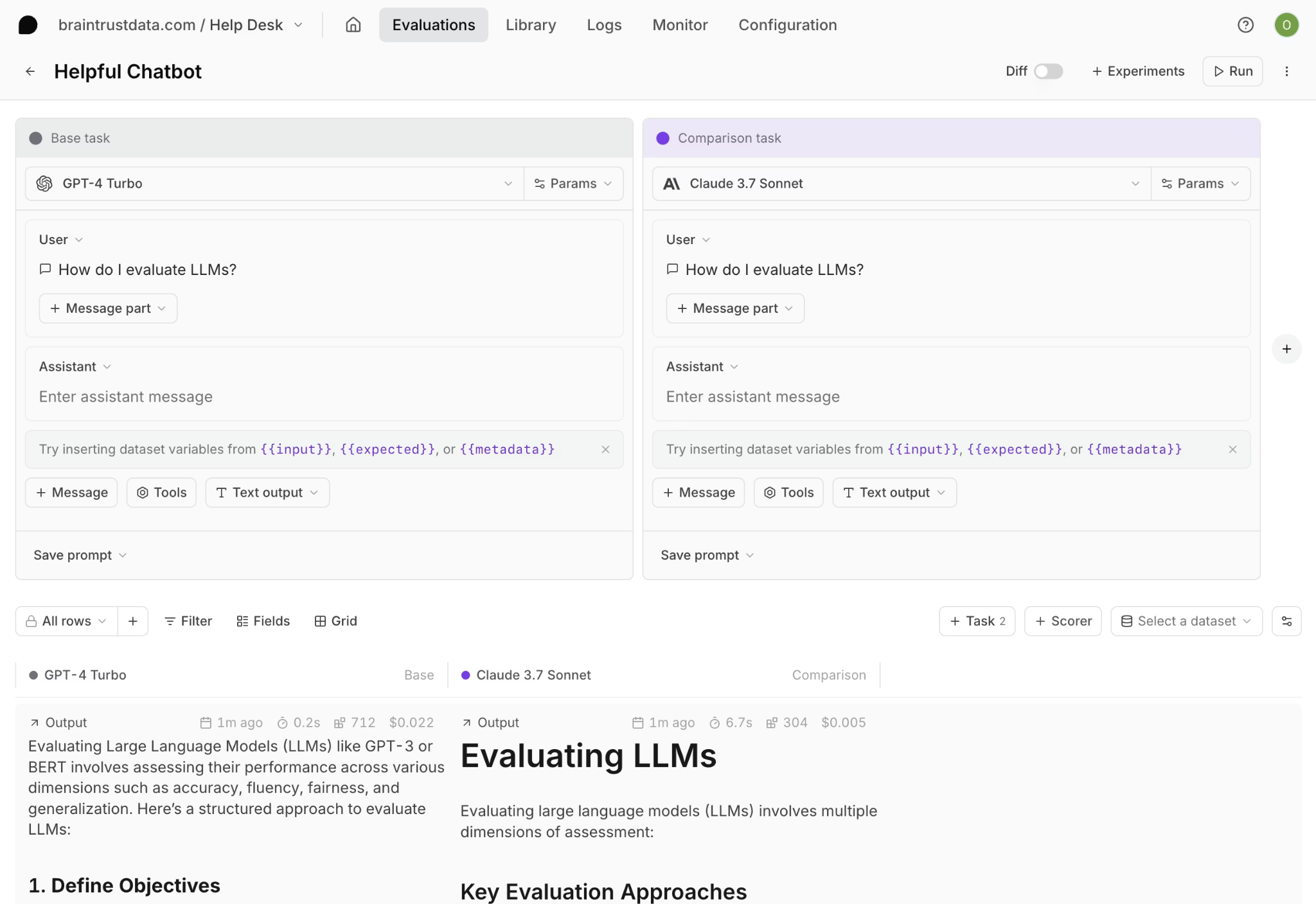
Braintrust's evaluation playground allows engineers and product managers to work against the same datasets and scorer outputs in a shared interface. Product managers iterate on prompts in the UI, engineers maintain code-based tests, and both rely on the same evaluation results when approving changes.
Resolving a production LLM failure in Datadog and Braintrust
Scenario: Incorrect return policy responses
A retrieval-augmented customer support agent begins returning incorrect answers about return policies. Support tickets increase, and customers receive outdated policy information. The engineering team must identify the source of the error, implement a correction, and ensure that similar regressions do not recur in production.
Handling the failure in Datadog
Datadog hallucination detection flags a spike in contradictions between model outputs and retrieved context, triggering an alert and prompting the on-call engineer to open LLM Observability for investigation. By filtering traces with the hallucination evaluation flag, the engineer identifies spans in which the model generates return-policy information that conflicts with the retrieved documents.
To test a potential fix, the engineer imports one of the failing traces into the Playground and modifies the system prompt to prioritize recently updated documents. Although the output improves for that individual trace, validating the change across a broader set of return-policy queries requires assembling a dataset through the LLM Experiments SDK, defining evaluators, running the experiment programmatically, and reviewing results in the Experiments interface.
Once the experiment confirms improvement, the engineer updates the prompt in the application code, opens a pull request, and deploys through the existing CI pipeline. Production hallucination metrics must then be monitored to determine whether the fix holds under live traffic.
While each component of this process functions as intended, experiment execution, code review, deployment, and production verification occur across separate systems, and no CI-integrated evaluation gate prevents deployment if regression appears in related queries.
Handling the failure in Braintrust
Braintrust's online scoring detects the quality decline as relevancy scores drop across retrieval spans, prompting the engineer to filter traces by low scores and examine related queries. The trace data shows that a recently updated document source is returning outdated policy information that conflicts with current return guidelines.
To address the outdated document retrieval pattern, the engineer converts the failing traces into dataset entries and modifies the prompt inside the evaluation playground to prioritize recently updated documents. The full evaluation suite runs against both the newly added failure cases and the existing regression tests covering other support scenarios, which verifies that the prompt adjustment improves return-policy responses without degrading performance elsewhere.
With evaluation results confirming improvement and no regressions, the engineer opens a pull request, and the Braintrust GitHub Action automatically executes the same evaluation suite. The pull request comment displays score changes and confirms that all regression standards remain satisfied before merge. After deployment, online scoring continues to use the same evaluators on live traffic, and the converted traces remain in the dataset as permanent regression tests, preventing similar policy errors from reappearing in future releases.
In the Datadog workflow, verification occurs after deployment by observing production metrics and experiment results across separate systems. In the Braintrust workflow, verification occurs before deployment through CI-integrated evaluation gates that enforce regression standards at merge time.
Quick comparison: Braintrust vs. Datadog
| Feature | Braintrust | Datadog LLM Observability | Winner |
|---|---|---|---|
| End-to-end LLM tracing | Full agent trace trees with per-span inputs, outputs, and scores. Brainstore engine supports fast querying across large trace volumes. | Traces across LLM chains and agent workflows with execution flow charts. Integrates with Datadog APM for full-stack correlation. | Tie |
| Built-in scorers | Open-source autoevals library with 25+ built-in scorers covering factuality, closeness, relevance, and more. Supports code-based and LLM-as-a-judge scorers. | Managed evaluations for hallucination, sentiment, topic relevancy, toxicity, and failure to answer. Custom LLM-as-a-judge evaluators require BYOK provider keys. | Braintrust |
| CI/CD eval integration | Dedicated GitHub Action runs evaluation suites on every pull request, posts score breakdowns in PR comments, and allows merges to be blocked when regression thresholds fail. | CI Visibility and datadog-ci provide pipeline telemetry, but LLM experiment results are not embedded directly in pull requests or enforced as a native CI evaluation gate. | Braintrust |
| Eval playground | Supports tasks, scorers, datasets, side-by-side comparisons, shared views for PMs and engineers, and deployment of validated prompt variants from the same workspace. | Playground supports replaying individual traces with alternative prompts or models and comparing outputs side by side on single cases. | Braintrust |
| Prompt management | End-to-end prompt lifecycle including versioning, editing, testing against datasets, comparing variants by score, and deploying directly. | Prompt Tracking links versions to traces with metrics and diffs, but editing and deployment occur in application code outside Datadog. | Braintrust |
| Production-to-dataset loop | One-click trace-to-dataset conversion. Loop assists with generating scorers, datasets, and prompt revisions from production data. | Traces can be imported into experiment datasets via UI or SDK. Scoring and dataset creation are manual. | Braintrust |
| Online scoring | The same scorers used in offline evaluation can run asynchronously on production traffic without adding latency, keeping development and production standards aligned. | Managed evaluations run on production traces once configured. Custom evaluations require a separate BYOK setup. | Braintrust |
| Infrastructure correlation | Focused on the LLM application layer, with OpenTelemetry support for integration into broader infrastructure stacks. | Native APM, RUM, and infrastructure metric correlation within the Datadog platform. | Datadog |
| Security and compliance | SOC 2 Type II, GDPR, HIPAA support, SSO, RBAC, audit logging, and hybrid deployment options. | Sensitive Data Scanner and AI Guard for PII detection and prompt injection risk reduction, plus SOC 2, HIPAA, and FedRAMP across the broader platform. | Datadog |
| SDK and framework support | SDKs across multiple languages with integrations for major model providers and frameworks, plus OpenTelemetry support. | SDKs for Python, Node.js, and Java with auto-instrumentation for major model providers and OpenTelemetry GenAI support. | Tie |
| PM and engineer collaboration | Shared evaluation playground where PMs iterate on prompts and datasets while engineers maintain code-based tests against the same evaluation results. | The Playground and Experiments SDKs are developer-oriented; PM-led experimentation typically requires an engineering setup. | Braintrust |
The enterprise buying decision
Enterprise teams evaluating LLM tooling must decide whether LLM quality control can live within an infrastructure monitoring platform or requires a system built specifically for evaluation and release enforcement.
Datadog extends its infrastructure platform into LLM observability by adding tracing, managed evaluations, and security features on top of its existing APM and log management stack. For organizations already standardized on Datadog, this expansion provides visibility into LLM behavior alongside backend services, costs, and latency metrics within a single operational console.
Braintrust provides LLM tracing and production visibility together with evaluation governance, CI-integrated regression gates, prompt version management, and production-to-dataset workflows. Because these capabilities are part of the core system rather than add-ons, teams can run the entire LLM lifecycle on a single platform without adding additional tooling.
For organizations that want a single platform to own LLM tracing, evaluation, regression enforcement, and release control, Braintrust covers the full LLM layer end-to-end. Datadog remains the infrastructure system of record, but it does not replace a dedicated evaluation system when release decisions depend on quality thresholds. Teams that choose Braintrust as the primary LLM platform gain both visibility and enforcement without splitting responsibility across separate tools.
Ready to add the deep eval layer your AI stack is missing? Start with Braintrust for free with 1 GB of processed data and 10,000 evaluation scores per month, enough to set up and test its advanced evaluation features before committing.
Braintrust vs. Datadog FAQs
What is the difference between LLM observability and LLM evaluation?
LLM observability provides visibility into how an application behaves in production, including traces of model calls, latency, token usage, error rates, and cost. LLM evaluation measures whether those outputs meet defined quality standards by scoring responses against criteria, running tests across datasets, and tracking regressions over time. Observability explains system behavior, while evaluation determines whether that behavior meets release requirements and enforces quality improvements before deployment.
Does Datadog LLM Observability include evaluation features?
Datadog includes managed evaluations for hallucination detection, sentiment, topic relevance, toxicity, and failure to answer, as well as support for custom LLM-as-a-judge evaluators and structured experiment runs. These capabilities allow teams to score production traces and run controlled tests on prompt or model changes.
However, Datadog's evaluation features operate within a monitoring-centered architecture. Evaluation results are visible in dashboards and experiment views, but they are not deeply integrated into CI pipelines, prompt lifecycle management, or release gating workflows as a dedicated evaluation system like Braintrust provides.
Is Braintrust better than Datadog for LLM evals?
For structured evaluation and regression control, Braintrust provides deeper integration. Evaluation suites can run automatically in CI, results appear in pull requests, and regression thresholds can block merges. Datadog supports managed and custom evaluations, but those features remain part of a monitoring workflow rather than a CI-enforced release process.
Can I use Datadog and Braintrust together?
Many enterprise teams use Datadog for infrastructure monitoring, APM, log management, and security visibility across backend services and user sessions, while using Braintrust to manage evaluation workflows, control prompt changes, and enforce regression checks in CI before deployment. Datadog provides system health and performance visibility across the broader stack, and Braintrust governs LLM output quality and release decisions. Because Braintrust supports OpenTelemetry, engineering teams can send trace data to Datadog for infrastructure correlation while keeping evaluation, dataset management, and release gating inside Braintrust without duplicating instrumentation.
Which is the best AI observability and evaluation platform?
For teams that need observability alongside enforceable evaluation workflows, Braintrust provides a more comprehensive LLM layer. Braintrust captures production traces and connects them directly to datasets, experiments, prompt versioning, and CI-integrated regression checks. Organizations that treat LLM quality as a deployment requirement rather than a dashboard metric typically select Braintrust as their primary evaluation system.