What is RAG evaluation? Measuring retrieval quality and answer groundedness
Retrieval-Augmented Generation (RAG) systems pull relevant documents from a knowledge base and pass them to a language model, which uses that context to generate an answer. The goal of RAG is to keep LLM responses grounded in your data, but RAG pipelines break down in ways that are hard to spot. Retrieval may return documents unrelated to the user's question, and the model may rely on its training data rather than the provided context. When that happens, the system can produce hallucinated facts even though RAG was designed to reduce them.
RAG breakdowns often stay hidden until users report incorrect answers or stop trusting the product. RAG evaluation measures quality at each stage of the pipeline so teams can catch problems early, identify where they start, and fix them systematically rather than waiting for user complaints.
This guide covers what RAG evaluation involves, the two dimensions every team needs to measure, practical methods for running evaluations at each stage of development, and a step-by-step workflow for implementing RAG evaluation with Braintrust.
What RAG evaluation is and why it matters
RAG evaluation is the practice of measuring how well a retrieval-augmented generation pipeline performs across its two main stages.
- The retrieval stage fetches relevant documents from a knowledge base.
- The generation stage uses those documents to produce an answer.
RAG evaluation measures both stages independently to understand how failures in one stage affect the other.
Standard LLM evaluation focuses solely on output quality, assessing whether the generated text is accurate, relevant, and well-structured. RAG evaluation goes further because a RAG pipeline has multiple points of failure that compound each other. Retrieval can surface the wrong documents, the model can ignore perfectly good context, or generation can blend retrieved facts with invented ones to produce answers that are partially grounded and partially hallucinated.
Each RAG failure mode requires different metrics and fixes. If you only measure end-to-end answer quality, a low score tells you something is wrong but gives no indication of where the breakdown actually occurred. Separating retrieval evaluation from generation evaluation turns a vague "quality is low" signal into an actionable diagnosis that points directly to the component that needs work.
The two core components of RAG evaluation
Retrieval quality
Retrieval quality measures whether the system pulled the right documents from the knowledge base to answer a given query. When the retrieval step fails, the generation model receives bad inputs, and even the best LLM cannot produce a grounded answer from an irrelevant context.
Retrieval quality is usually described through three metric groups:
Context precision measures the percentage of retrieved documents that are actually relevant to the query. A system that retrieves 10 documents but only 3 contain useful information wastes tokens on the other 7, introducing noise that makes it harder for the model to identify and use the right information.
Context recall measures whether the retrieval captured all the relevant documents available in the knowledge base. A system with high precision but low recall produces clean but incomplete context, so the generated answer may miss information needed to be fully correct.
Retrieval ranking metrics such as NDCG@K and Precision@K evaluate whether the most relevant documents appear at the top of the results. Ranking quality has a direct effect on answer quality because models tend to rely more on earlier context, so a relevant document buried at position ten may never be used.
Answer groundedness and faithfulness
Answer groundedness measures whether every claim in the generated response can be traced back to the retrieved context. A grounded answer draws only from the source documents provided, while an ungrounded answer includes fabricated details, invented statistics, or facts the model pulled from its training data rather than from the retrieved content.
Faithfulness and groundedness are often used interchangeably in RAG evaluation literature, though there is a subtle difference. Faithfulness refers to the overall truthfulness of the answer relative to its sources, while groundedness focuses on verifying individual claims against retrieved documents at a more granular level. In practice, both metrics detect the same core failure, whether the answer contains claims not supported by the retrieved context.
The key metrics in this category include:
Faithfulness score to calculate the ratio of supported claims to total claims in the answer.
Answer relevancy, which checks whether the response actually addresses the user's question rather than discussing a tangential topic.
Answer similarity compares generated responses against reference answers using semantic similarity for queries where you have known correct answers.
High answer relevancy does not guarantee high faithfulness. A model can produce a response that directly addresses the user's question while still hallucinating specific facts. The answer appears on-topic and reads well, but individual claims within it lack support in the retrieved documents, making it unreliable despite seeming relevant.
How to evaluate RAG in practice
Offline evaluation with golden datasets
Offline evaluation runs your RAG pipeline against a curated test set where you know the correct answers and the relevant documents. The curated test set, referred to as golden datasets, serves as regression tests that catch quality drops before they reach production.
A useful starting golden dataset contains 30-50 real or realistic queries that reflect your main use cases. Include factual questions with clear answers, multi-document questions that require synthesis, ambiguous queries with more than one valid interpretation, and cases where the correct answer is that the information is not available. With references, you can compare generated answers to known-good responses. Without references, you can still score outputs by using LLM judges to evaluate dimensions such as relevancy and faithfulness without relying on ground truth.
Online evaluation and how production differs from local
Test sets, no matter how carefully constructed, cannot fully represent what real users ask. Production queries use different phrasing, surface edge cases nobody anticipated during development, and shift in distribution over time as user needs change. A RAG pipeline that scores well on a golden dataset can still struggle with real-world query variations, since the dataset captures only a snapshot of expected usage.
Online evaluation reflects real usage by scoring a sample of production queries with the same scorers, so you see how the system performs on live phrasing, edge cases, and shifting query patterns. Offline evaluation validates changes before deployment, while online evaluation detects problems that only emerge at scale, and both are necessary for a reliable RAG evaluation framework.
Automated metrics and their limits
LLM-as-a-judge scoring is the most common automated approach to RAG evaluation. A judge model reviews the generated answer alongside the retrieved context and the original query, then assigns scores for relevance, faithfulness, and context quality using a rubric you define. Semantic similarity metrics offer a lighter-weight alternative for answer comparison, measuring how closely a generated response matches a reference answer in embedding space without requiring a separate LLM call.
Automated metrics do have limitations that teams should plan around. Judge models can hallucinate their own assessments, especially on edge cases where the rubric is ambiguous. Inconsistent rubric interpretation leads to score variance across similar inputs. Running judge models at scale also adds cost and latency to the evaluation pipeline, which is why most teams score a representative sample of requests rather than every single one.
Human review for high-stakes evaluation
Automated metrics handle the bulk of evaluation volume, but human review remains necessary to calibrate those automated scores and to evaluate cases where automated judges produce low-confidence or conflicting results. Human reviewers should label the same dimensions that automated scorers measure, specifically relevancy, faithfulness, and completeness, so that their judgments can directly validate and improve automated scoring accuracy.
Consistency across reviewers requires clear annotation guidelines that define each score level with concrete examples. Inter-rater agreement metrics help identify where guidelines are ambiguous and need refinement. Over time, human labels improve automated scorer accuracy enough that human review can focus on genuinely difficult cases rather than routine quality checks.
Production monitoring for drift and regressions
RAG pipelines degrade in ways that are difficult to predict. When the underlying document corpus is updated, retrieval behavior changes because embeddings for new or modified documents may no longer match the same queries they did before. Model updates shift generation behavior in subtle ways, and user query patterns evolve as products change and new use cases emerge.
Continuous monitoring tracks faithfulness scores, relevancy scores, retrieval latency, and user feedback signals like thumbs-up and thumbs-down ratings on live traffic. Setting threshold-based alerts lets teams catch regressions quickly, so a sudden drop in average faithfulness scores triggers an investigation into whether document changes or model updates caused the faithfulness drop. Feeding low-scoring production queries back into offline golden datasets closes the improvement loop and prevents the same failure category from recurring.
How to evaluate your RAG pipeline with Braintrust
To evaluate a RAG system properly, you need visibility into what was retrieved, how the model used that context, how each stage was scored, and how those signals evolve in production. Braintrust connects tracing, scoring, experimentation, and monitoring into a single workflow so retrieval and generation quality are measured against the same data and traces from development through deployment.
The workflow below shows how to use Braintrust to evaluate a RAG pipeline end to end.
Step 1. Trace the entire pipeline
Braintrust's @traced decorator instruments each stage of your RAG pipeline as a separate span, capturing inputs, outputs, and timing data at every step. When evaluation scores drop, these traces let you investigate the exact span where the pipeline broke down, whether that was retrieval returning irrelevant documents or generation misusing the correct context.
from braintrust import traced
@traced
def retrieve_documents(query: str, top_k: int = 5):
# Your retrieval logic
documents = search_index(query, top_k=top_k)
return documents
@traced
def generate_answer(query: str, documents: list[str]):
# Your generation logic
context = "\n".join(documents)
answer = llm.generate(query=query, context=context)
return answer
@traced
def rag_pipeline(query: str):
documents = retrieve_documents(query)
answer = generate_answer(query, documents)
return {"query": query, "documents": documents, "answer": answer}
Because retrieval and generation are separated into different spans, debugging becomes targeted. A low faithfulness score on a specific query leads directly to the trace, where you can see what documents were retrieved, what context was sent to the model, and what the model generated, all in a single view.
Brainstore, Braintrust's AI observability database, enables fast trace inspection at production scale. Brainstore delivers query times under one second across millions of traces and terabytes of data, so teams can search through logs, filter by complex conditions, and investigate individual spans without waiting for slow database queries to return results.
Step 2. Build evaluation datasets from production
The most reliable RAG evaluation data comes from real user queries because production reveals question patterns that developers never anticipate during development. Braintrust traces production requests automatically, which allows teams to review and tag outcomes such as successful answers, failures, ambiguous queries, and edge cases. Over time, this tagged collection grows into a representative golden dataset that reflects actual usage rather than synthetic assumptions. Teams can filter traces by score range to surface the lowest-performing queries and promote them into regression tests, preventing previously fixed failures from returning after retrieval or prompt changes.
Loop, Braintrust's built-in AI assistant, speeds up this dataset curation process by letting teams query production logs using natural language.
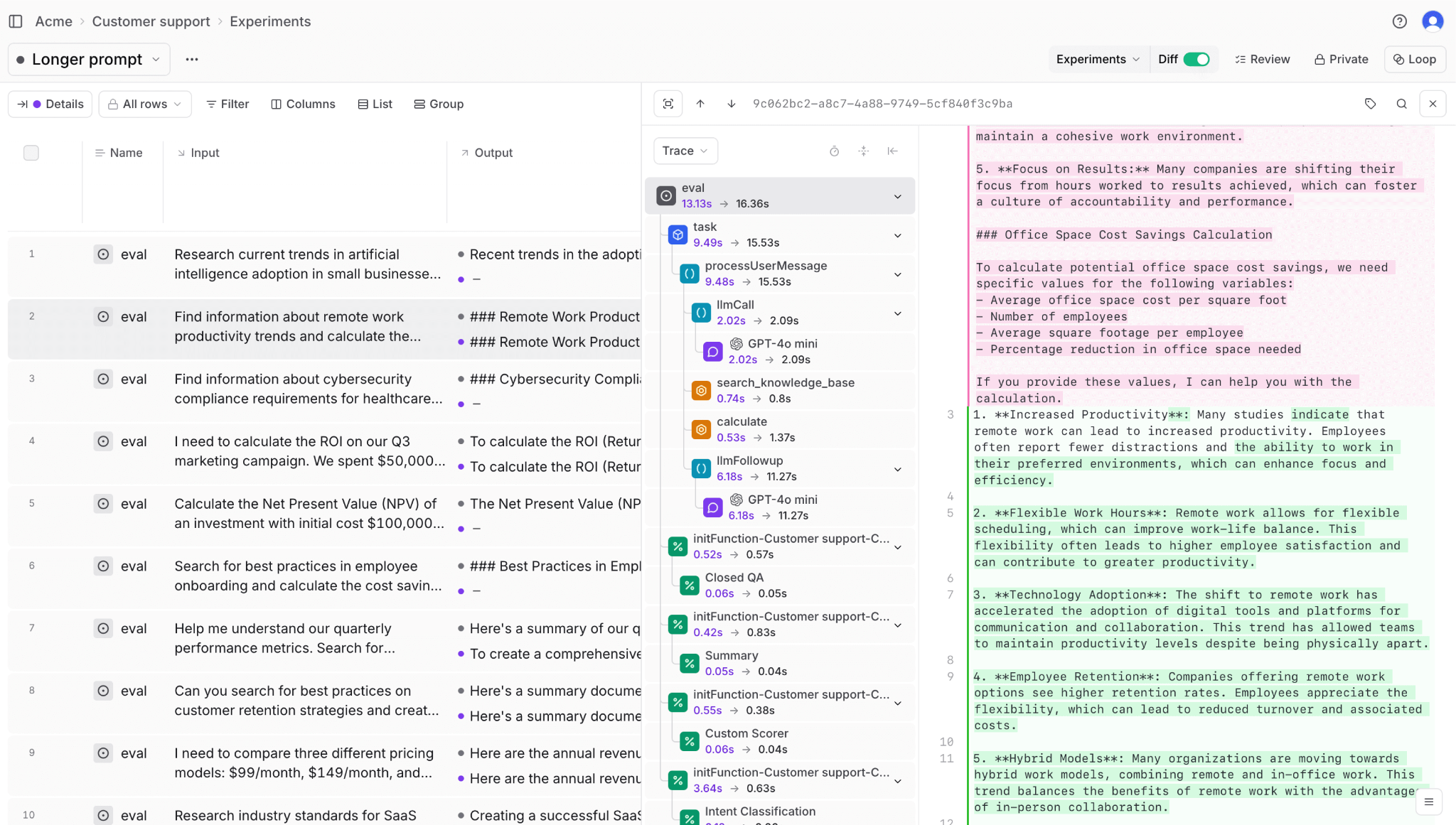
Instead of writing complex filters manually, you can ask Loop to find queries where faithfulness scores dropped below a threshold or where retrieval returned zero relevant documents, and it will surface matching traces in seconds. Loop can also generate synthetic test cases to fill gaps in your golden dataset, such as edge cases or query types that rarely appear in production but still need coverage.
Step 3. Define scorers for each RAG metric
Braintrust supports both built-in and custom scorers that cover different quality dimensions of RAG evaluation. Built-in scorers handle common measurements, such as semantic similarity for answer-question alignment and factual consistency for faithfulness checking, so teams can start evaluating immediately without writing scoring logic from scratch. For domain-specific requirements, custom scorers let you define evaluation criteria tailored to your use case.
The example below shows a custom faithfulness scorer that extracts claims from the generated answer and verifies each one against the retrieved documents.
from braintrust import Scorer
faithfulness_scorer = Scorer(
name="Answer Faithfulness",
scoring_function=check_faithfulness,
metadata={"description": "Checks if answer claims are supported by context"},
)
def check_faithfulness(output, context):
"""Verify answer statements appear in retrieved context"""
answer = output.get("answer")
documents = context.get("documents", [])
# Use LLM to verify each claim in answer against documents
verification = llm.verify_claims(answer=answer, documents=documents)
return {
"score": verification.faithfulness_score,
"metadata": {
"unsupported_claims": verification.unsupported_claims,
"total_claims": verification.total_claims,
},
}
This scorer returns a value between 0 and 1 representing the percentage of claims supported by context, along with metadata identifying exactly which claims lack document support. When faithfulness scores drop on a particular set of queries, the metadata points directly to the unsupported claims so the team knows exactly what to fix.
Step 4. Run experiments to compare pipeline variations
RAG pipelines involve many design choices, including embedding models, chunk sizes, retrieval top-K values, and generation prompts, and each choice affects retrieval precision, faithfulness, and relevancy in ways that are difficult to predict without measurement. Braintrust experiments let you change one variable at a time and compare results against the same evaluation dataset, removing guesswork from pipeline optimization.
from braintrust import Eval
# Baseline with 5 documents
baseline_results = Eval(
name="RAG Baseline - 5 docs",
data=evaluation_dataset,
task=lambda query: rag_pipeline(query, top_k=5),
scores=[relevancy_scorer, faithfulness_scorer, context_precision_scorer],
)
# Experiment with 10 documents
experiment_results = Eval(
name="RAG Experiment - 10 docs",
data=evaluation_dataset,
task=lambda query: rag_pipeline(query, top_k=10),
scores=[relevancy_scorer, faithfulness_scorer, context_precision_scorer],
)
Results are displayed side by side, making it clear whether increasing retrieval depth improved recall, degraded precision, or shifted faithfulness. Teams can see the specific queries that changed behavior before deciding to ship.
Braintrust's Playground lets teams test prompt and model variations interactively before running full experiments. Engineers and PMs can load production traces directly into the Playground, swap models, adjust retrieval parameters, and compare outputs side by side with quality scores, all without writing code.
Braintrust's GitHub Action (braintrustdata/eval-action) integrates RAG evaluation directly into CI/CD pipelines. Every pull request that modifies retrieval logic, generation prompts, or pipeline configuration triggers an evaluation run, and Braintrust posts the results as a comment on the PR with a link to the full experiment. Pipeline changes that cause faithfulness or relevancy scores to drop below defined thresholds get flagged before they merge, preventing regressions from reaching production.
Step 5. Monitor RAG quality in production
After deployment, Braintrust runs evaluation on sampled live traffic and tracks quality trends over time. The monitoring dashboard aggregates faithfulness, relevancy, retrieval latency, token usage, and cost metrics so teams can observe how the system behaves under real usage. Teams can filter data by any metadata dimension, such as query type, user segment, or model version, to pinpoint exactly where quality is degrading.
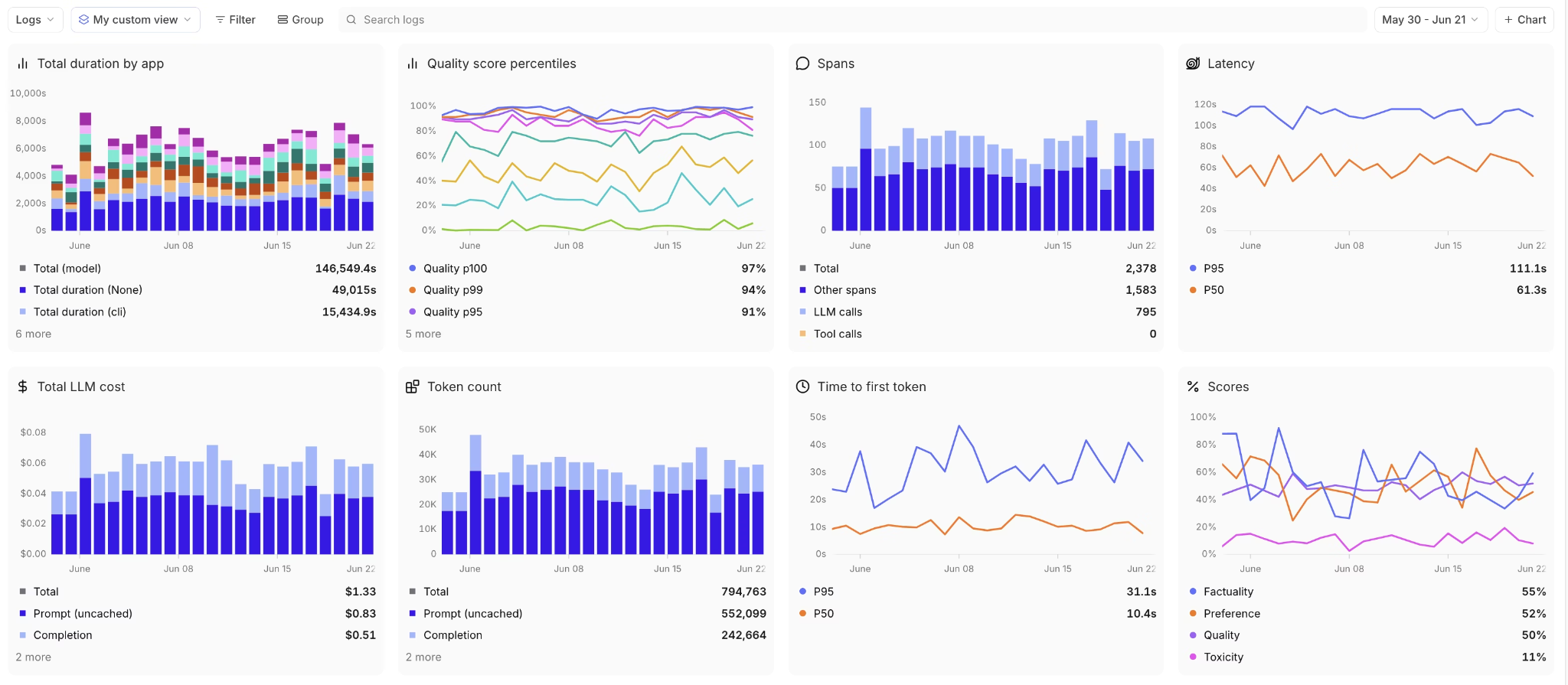
Low-scoring production queries can be added directly to offline datasets, creating a feedback loop where real failures strengthen regression coverage. As the dataset evolves, evaluation becomes more representative and the pipeline becomes more resilient to edge cases.
Notion, Stripe, Zapier, Vercel, Airtable, and Ramp rely on Braintrust's integrated workflow, from tracing and evaluation through production monitoring, to catch quality issues before users notice them and to continuously improve accuracy.
Ready to start evaluating your RAG pipeline? Start with Braintrust's free tier and run your first eval in minutes.
Conclusion
RAG evaluation keeps retrieval and generation aligned as documents change, prompts evolve, and models are updated. When retrieval quality and generation faithfulness are measured separately and tracked consistently, failures become easier to trace and fix.
Braintrust gives teams the full infrastructure to run a RAG evaluation workflow, from tracing and dataset curation through experimentation and production monitoring, in a unified platform. The integrated workflow keeps RAG quality easily measurable and manageable as the pipeline grows more complex. Get started with Braintrust to build your RAG evaluation pipeline today.
RAG evaluation FAQs
What is RAG evaluation?
RAG evaluation measures how well a retrieval-augmented generation pipeline retrieves relevant context and generates answers that stay grounded in that context. It evaluates retrieval and generation separately because each stage can fail independently even when the other performs correctly.
How is RAG evaluation different from standard LLM evaluation?
Standard LLM evaluation looks only at the final output and assesses qualities such as accuracy and relevance. RAG evaluation measures the full pipeline, including retrieval quality, context usage, and answer grounding. A weak answer in a RAG system may result from incorrect retrieval, poor use of correct context, or unsupported claims, and identifying the specific failure causes determines the appropriate fix.
What are the most important RAG evaluation metrics?
The four core metrics are answer relevancy (whether the response addresses the question), faithfulness or groundedness (whether the answer is supported by retrieved context), context precision (whether retrieved documents are relevant), and context recall (whether retrieval captured all available relevant information). Teams start with these four metrics and add domain-specific metrics as evaluation matures.
What tools can I use for RAG evaluation?
You can assemble a RAG evaluation stack from separate logging, experimentation, and monitoring tools, but that often leads to fragmented data and inconsistent metrics across environments.
Braintrust provides an integrated RAG evaluation workflow that combines pipeline tracing, dataset curation, automated scoring, experiment comparison, and production monitoring in one system. Because everything runs on the same traces and metrics, teams can move from diagnosing an issue to validating a fix without switching tools or rebuilding context.
How do I get started with RAG evaluation?
Start by instrumenting your RAG pipeline so retrieval inputs, retrieved documents, and model outputs are captured as traces. Then assemble a small dataset of real user queries and define clear metrics for retrieval quality and answer grounding so performance can be measured consistently. Run offline evaluations before shipping changes and score sampled production traffic to catch regressions as documents, prompts, or models evolve.
Braintrust connects tracing, scoring, experiments, and monitoring in one workflow, which makes it straightforward to move from initial setup to continuous RAG evaluation.