The canonical agent architecture: A while loop with tools
From personal assistants to complex automated systems, agents are revolutionizing how we interact with technology. For many developers, building a good agent feels like navigating a maze of frameworks, layers of optimization, and tools, each adding its own overhead.
Surprisingly, many of the most popular and successful agents, including Claude Code and the OpenAI Agents SDK for example, share a common, straightforward architecture: a while loop that makes tool calls.
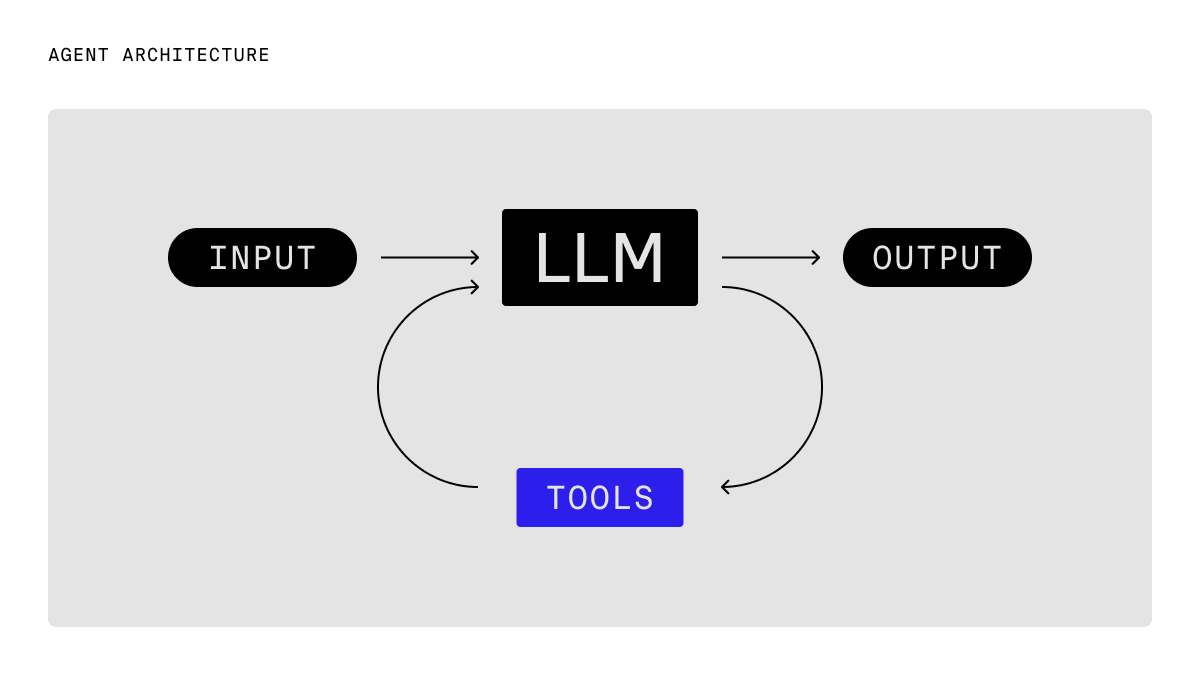
Here's the basic structure:
while (!done) {
const response = await callLLM();
messages.push(response);
if (response.toolCalls) {
messages.push(
...(await Promise.all(response.toolCalls.map((tc) => tool(tc.args)))),
);
} else {
messages.push(getUserMessage());
}
}
That's it. Each iteration passes the current state into a language model, receives back a decision (usually a tool invocation or text response), and moves forward. The agent is just a system prompt and a handful of well-crafted tools.
This pattern wins for the same reason as UNIX pipes and React components: it's simple, composable, and flexible enough to handle complexity without becoming complex itself. It naturally extends to more advanced concepts like sub-agents (a tool call that invokes an independent agent loop) and multi-agents (independent agent loops that perform message passing with tool calls). It also allows you to focus on the problems that matter most: tool design, context engineering, and evaluation.
Tool design sets up the LLM for success
When you expose every API argument to a language model, it can become overloaded with irrelevant details and make mistakes. Instead, define each tool with only the essential parameters and provide a clear description tailored to the agent’s task. Only include inputs that are directly relevant to the agent’s objective.
A common trap is exposing a REST API as a single tool and letting the agent figure it out. This shifts cognitive burden to the agent when that complexity can be absorbed into your tool design. Instead, you can break complex APIs into simple, well-scoped functions tailored to how the agent thinks about the problem.
Here's a classic example of a tool with too many arguments:
// Bad: Generic communication API that exposes everything
const sendMessageTool = {
name: "send_message",
description: "Send a message through any communication channel",
parameters: z.object({
channel: z
.enum(["email", "sms", "push", "in-app", "webhook"])
.describe("Communication channel"),
recipient: z
.string()
.describe("Recipient identifier (email, phone, user ID, etc.)"),
content: z.string().describe("Message content"),
subject: z.string().optional().describe("Message subject (for email)"),
template: z.string().optional().describe("Template ID to use"),
variables: z.record(z.string()).optional().describe("Template variables"),
priority: z.enum(["low", "normal", "high", "urgent"]).optional(),
scheduling: z
.object({
sendAt: z.string().optional(),
timezone: z.string().optional(),
})
.optional(),
tracking: z
.object({
opens: z.boolean().optional(),
clicks: z.boolean().optional(),
conversions: z.boolean().optional(),
})
.optional(),
metadata: z.record(z.string()).optional().describe("Additional metadata"),
}),
};
For a specific use case, you can likely get away with something much simpler:
// Good: Purpose-built tool for the agent's actual job
const notifyCustomerTool = {
name: "notify_customer",
description: "Send a notification email to a customer about their order or account",
parameters: z.object({
customerEmail: z.string().describe("Customer's email address"),
message: z.string().describe("The update message to send to the customer"),
}),
// The tool handles all the complexity internally
execute: async ({ customerEmail, message }) => sendMessageTool({ recipient: customerEmail, content: message, ... }),
};
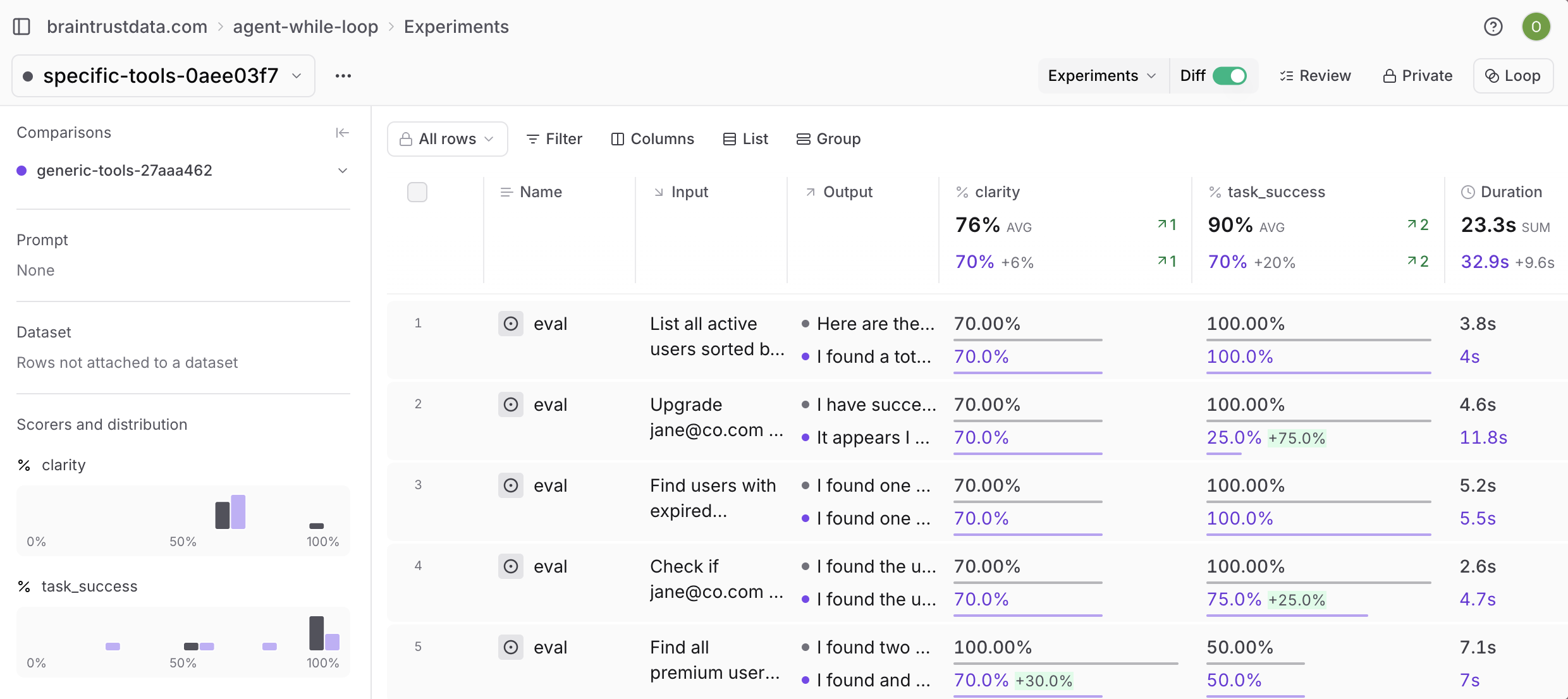
When you evaluate the two sets of tools, it's clear that the specific approach scores better:
Context engineering matters
Everyone talks about prompt engineering, but most of the agent's context comes from tool inputs and outputs. In a typical agent conversation, tool responses make up 67.6% of the total tokens, while the system prompt accounts for just 3.4%. Tool definitions add another 10.7%, meaning tools comprise nearly 80% of what the agent actually sees.
It's important to design tool outputs just like you would a prompt. That means using concise language, filtering out irrelevant bits of data, and formatting them in an easy-to-read way. If you wouldn't want to read a giant blob of JSON, don't dump that into the tool output either.
The transcript, or what the agent sees from previous actions, is where a lot of reasoning actually happens. And it's entirely in your control. The goal is to make the agent's job as easy as possible by engineering the context it receives from each tool interaction.
// Bad tool output (when includeMetadata is true in generic tool)
{
"query_metadata": {
"execution_time_ms": 23,
"source": "users",
"operation": "find",
"filters_applied": ["subscription_status"],
"cache_hit": false
},
"result_count": 2,
"results": [
{
"id": 1,
"name": "John Smith",
"email": "john@company.com",
"subscription": {
"plan": "premium",
"status": "expired",
"expires": "2024-06-15T00:00:00.000Z"
}
},
{
"id": 2,
"name": "Jane Doe",
"email": "jane@startup.io",
"subscription": {
"plan": "basic",
"status": "expired",
"expires": "2024-05-20T00:00:00.000Z"
}
}
]
}
A good tool output (from the specific search_users tool) might look like this:
Found 2 users:
1. John Smith (john@company.com)
- Premium subscriber (expired)
- Last seen: 2 days ago
2. Jane Doe (jane@startup.io)
- Basic subscriber (expired)
- Last seen: yesterday at 3:15 PM
Need more details? Use 'get_user_details' with the user's email.
Evaluation as a foundation
When you build an agent, you're really building an evaluatable system. This means that in addition to the agent (or task function) itself, you also need to create a representative dataset and a library of scorers. Together, those three components form the foundation you can measure, benchmark, and continuously improve.
Here are the steps you can take:
- Create an end-to-end eval that verifies that the agent can complete ambitious tasks driven by a single user input
- Build a dataset from individual turns where the agent struggles, like when it picks the wrong tool or gives a poor response, and run more evals on those specific failure patterns
- Use remote evals to test the agent ad-hoc on a number of inputs at once in a playground
Models will change, prompts will evolve, and tools will get updated, so your eval needs to be durable. This consistency lets you measure progress and catch regressions as you iterate on the agent.
The path through complexity
The Bitter Lesson appears to apply to agent design as well. At its core, an agent is an LLM, a system prompt, and tools. Keeping your system design to just those components means your work will stand the test of time as new and more powerful models come out.
This pattern also absorbs complexity at the edges (in tool design and context engineering) while keeping the core architecture understandable enough for anyone to modify.
Many teams discover this pattern through experience. They might start with sophisticated frameworks or experiment with graph-based structures and multi-phase planners, but often find that simpler approaches prove more reliable in production. The agents that work consistently tend to converge on similar architectures under the hood.
Frameworks can be valuable for specific use cases, but the core components remain consistent: a good prompt that defines the agent's role and capabilities, a small set of clean tools designed for the agent's mental model, a transcript window that maintains conversation state, and a while loop that orchestrates everything.
The AI ecosystem is evolving fast, with new models, better tools, and novel abstractions. The agents that adapt well to this change are the ones that embrace simplicity and reliability. To see this pattern in action and run the code shown in this blog post, check out our cookbook for building reliable AI agents.