Contributed by Ornella Altunyan on 2025-08-05
In this cookbook, we’ll implement the canonical agent architecture: a while loop with tools. This pattern, described on our blog, provides a clean, debuggable foundation for building production-ready AI agents.
By the end of this guide, you’ll learn how to:
- Implement the canonical while loop agent pattern
- Build purpose-designed tools that reduce cognitive load
- Add comprehensive tracing with Braintrust
- Run evaluations to measure agent performance
- Compare different architectural approaches
The canonical agent architecture
The core pattern we’ll follow is straightforward:
Getting started
To get started, you’ll need Braintrust and OpenAI accounts, along with their corresponding API keys. Plug your OpenAI API key into your Braintrust account’s AI providers configuration. You can also add an API key for any other AI provider you’d like, but be sure to change the code to use that model. Lastly, set up your.env.local file:
package.json file with all the required dependencies and helpful scripts.
Install dependencies by running:
Building the agent
Let’s start by implementing the core agent class. The complete implementation is available inagent.ts, but let’s focus on the key parts.
First, we define our tool interface and agent options:
- The LLM responds without tool calls (indicating it’s done)
- We hit the maximum iteration limit
Designing purpose-built tools
One of the most critical aspects of building reliable agents is tool design. Rather than creating generic API wrappers, we design tools specifically for the agent’s mental model. Here’s what not to do - a generic email API wrapper:Building customer service tools
Our customer service agent needs four purpose-built tools, each designed for the agent’s specific workflow rather than as generic API wrappers. The complete implementation is available intools.ts.
notify_customer- Send targeted notifications (not generic email API)search_users- Find users with business-relevant filtersget_user_details- Get comprehensive user informationupdate_subscription- Handle subscription changes
Running the agent
Now let’s put it all together and create a customer service agent:Tracing and evaluation
Writing agents this way makes it straightforward to trace every iteration, tool call, and decision. In Braintrust, you’ll be able to see the full conversation history, tool execution details, performance metrics, and error tracking. The complete evaluation setup is available inagent.eval.ts.
Additionally, if you run npm run eval:tools, you can clearly see the difference between using generic and specific tools:
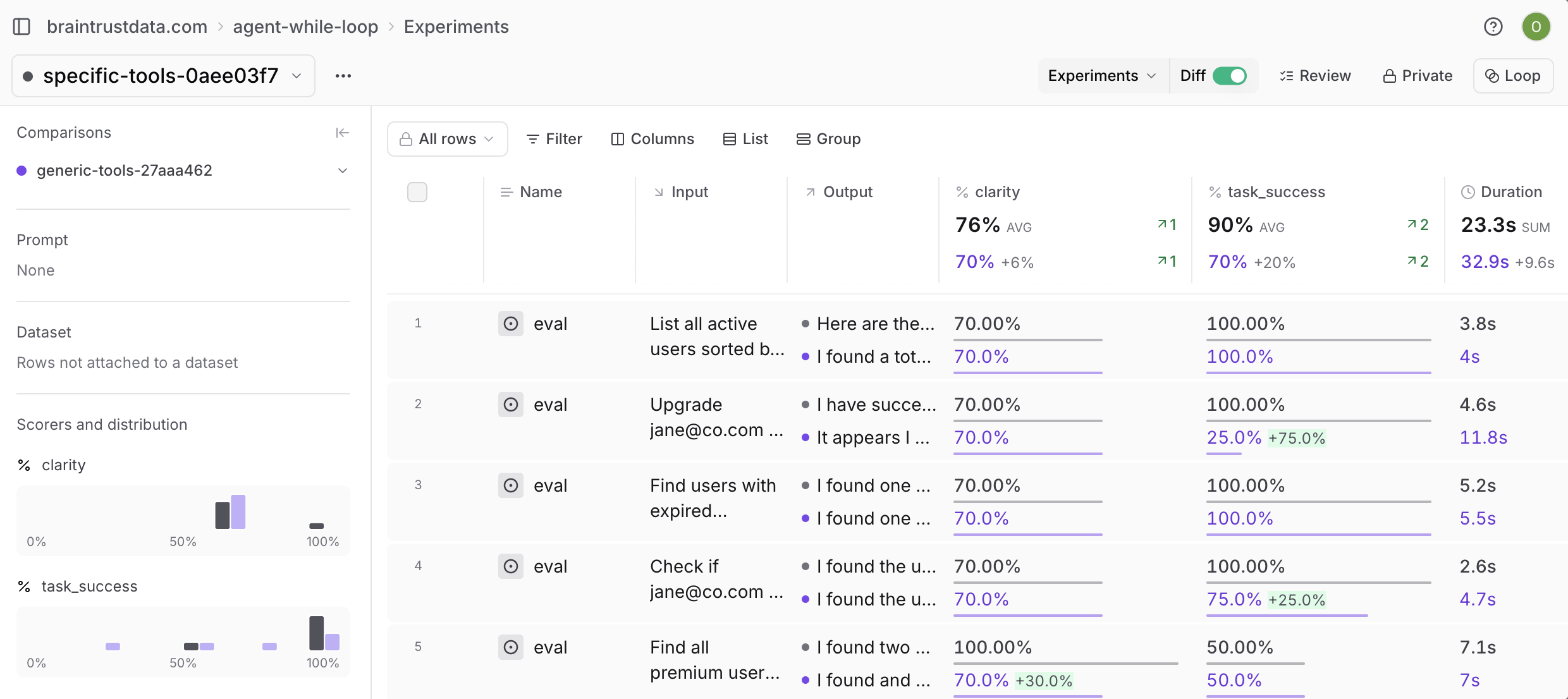
Next steps
Start building your own while loop agent by picking a specific use case and 2-3 tools, then gradually add complexity.- Log all interactions and build evaluation datasets from real usage patterns
- Use Loop to improve prompts, scorers, and datasets
- Explore more agent patterns in the cookbook