Contributed by Ornella Altunyan on 2024-08-28
We’re going to learn what it means to work with pre-built AI models, also known as foundation models, developed by companies like OpenAI and Anthropic, and how to effectively use Braintrust to evaluate and improve your outputs. We’ll be using a simple example throughout this guide, but the concepts you learn here can be applied to any AI product.
By the end of this guide, you’ll understand:
- Basic AI concepts
- How to prototype and evaluate a model’s output
- How to build AI-powered products that scale effectively
Understanding AI
Artificial intelligence (AI) is when a computer uses data to make decisions or predictions. Foundation models are pre-built AI systems that have already been trained on vast amounts of data. These models function like ready-made tools you seamlessly integrate into your projects, allowing them to understand text, recognize images, or generate content without requiring you to train the model yourself. There are several types of foundation models, including those that operate on language, audio, and images. In this guide, we’ll focus on large language models (LLMs), which understand and generate human language. They can answer questions, complete sentences, translate text, and create written content. They’re used for things like:- Product descriptions for e-commerce
- Support chatbots and virtual assistants
- Code generation and help with debugging
- Real-time meeting summaries
Getting started
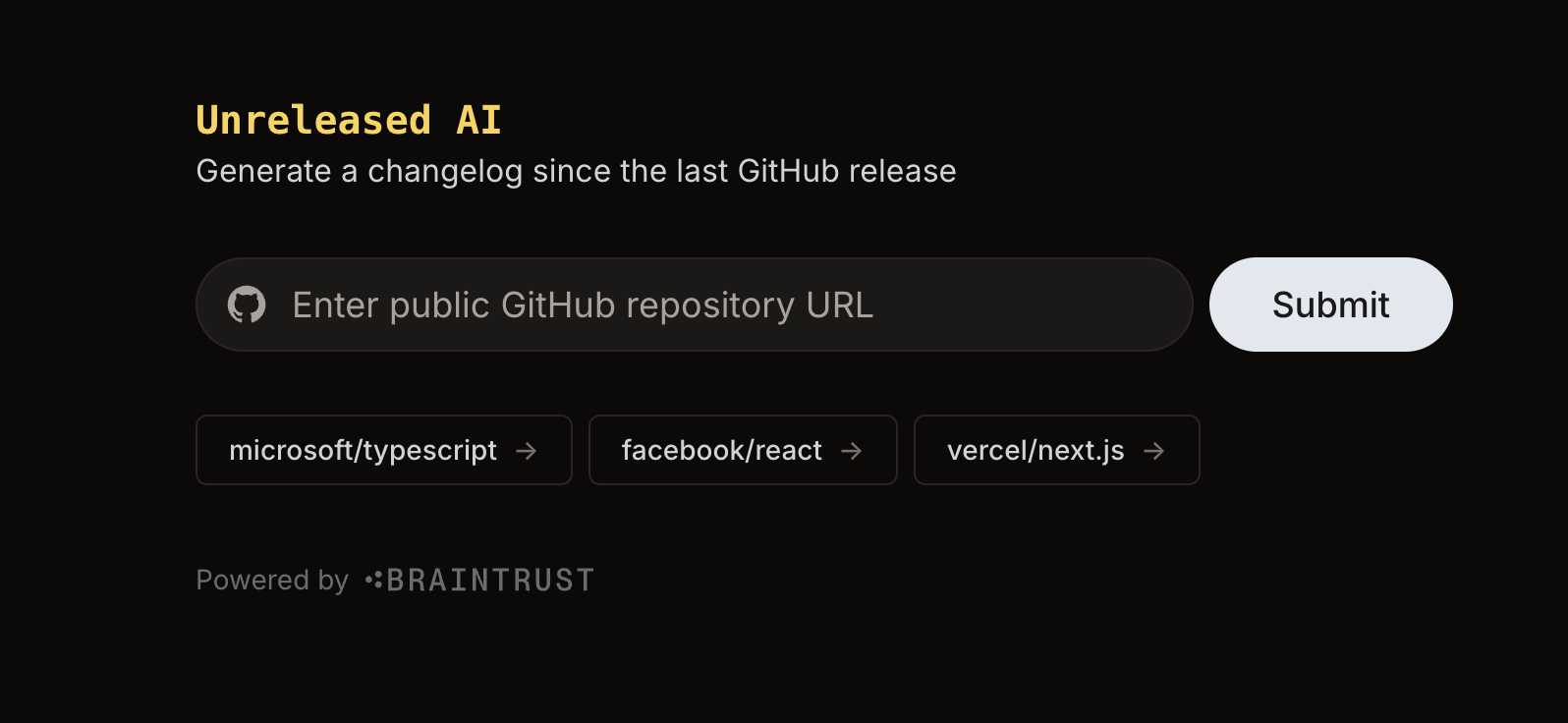
First, ensure you have Node, pnpm (or the package manager of your choice), and TypeScript installed on your computer. This guide uses a pre-built sample project, Unreleased AI, to focus on learning the concepts behind LLMs. Unreleased AI is a simple web application that allows you to inspect commits from your favorite open-source repositories that have not been released yet, and generate a changelog that summarizes what’s coming. It takes input from the user, the URL of a public GitHub repository, and uses AI to generate a changelog and output the commits since the last release. If there are no releases, it summarizes the 20 most recent commits. This application is useful if you’re a developer advocate or marketer, and want to communicate recent updates to users. Typically, you would access LLMs through a model provider like OpenAI, Anthropic, or Google by making a request to their API. This request usually includes some prompt, or direction for the model to follow. To do so, you’d need to decide which provider’s model you’d like to use, obtain an API key, and then figure out how to call it from your code. But how do you decide which one is correct? With Braintrust, you can test your code with multiple providers, and evaluate the responses so that you’re sure to choose the best model for your use case.Using AI models
Setting up the project
Let’s dig into the sample project and walk through the workflow. Before we start, make sure you have a Braintrust account and API key. You’ll also need to configure the individual API keys for each provider you want to test in your Braintrust settings. You can start with just one, like OpenAI, and add more later on. After you complete this initial setup, you’ll be able to access the world’s leading AI models in a unified way, through a single API.- Clone the Unreleased AI repo onto your machine. Create a
.env.localfile in the root directory. Add your Braintrust API key (BRAINTRUST_API_KEY=...). Now you can use your Braintrust API key to access all of the models from the providers you configured in your settings. - Run
pnpm installto install the necessary dependencies and setup the project in Braintrust. - To run the app, run
pnpm devand navigate tolocalhost:3000. Type the URL of a public GitHub repository, and take note of the output.
Working with Prompts in Braintrust
Navigate to Braintrust in your browser, and select the project named Unreleased that you just created. Go to the Prompts section and select the Generate changelog prompt. This will show you the model choice and the prompt used in the application: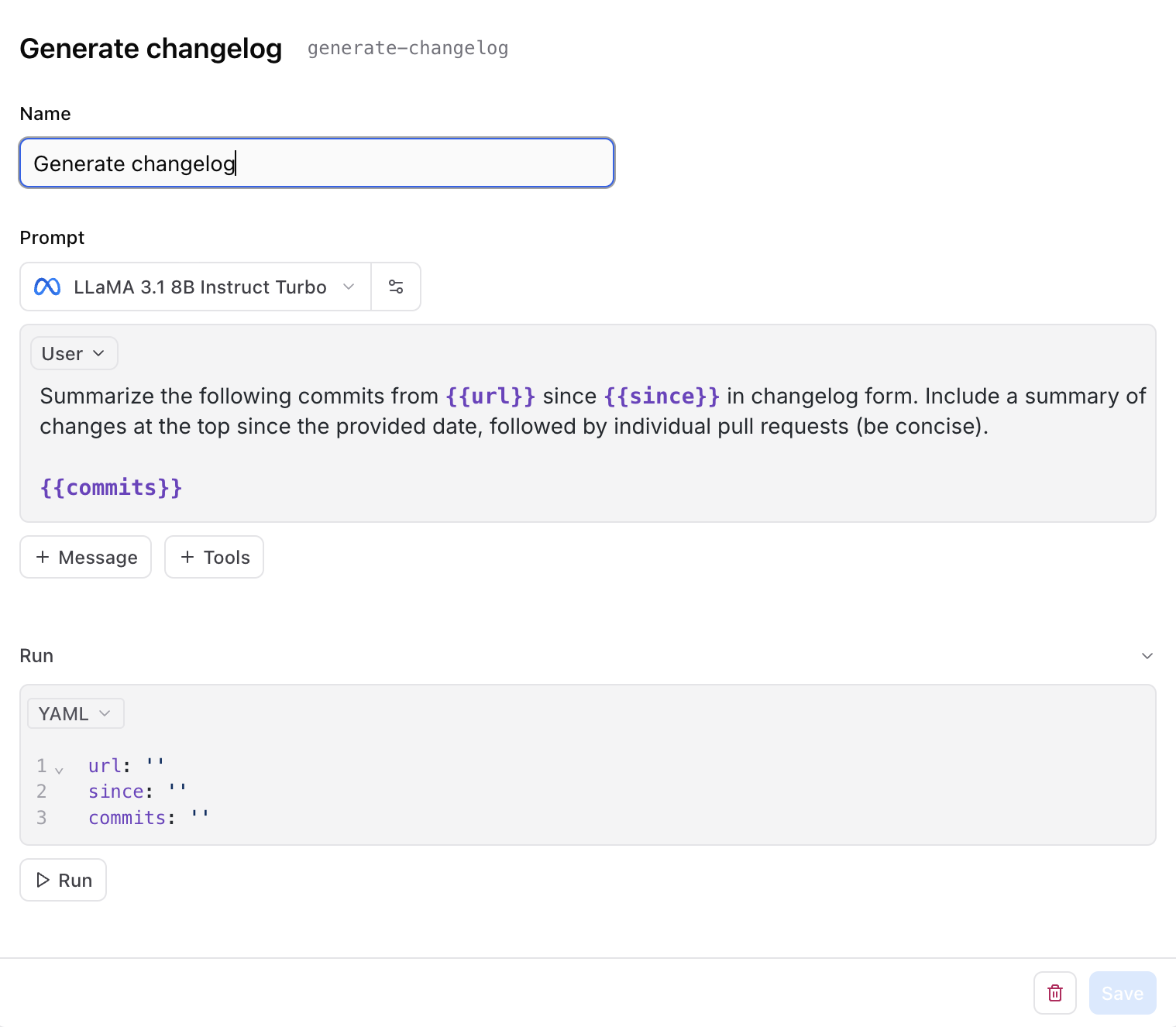
url: the URL of the public GitHub repository provided by the usersince: the date of the last release of this repository, fetched by the GitHub API in app/generate/route.tscommits: the list of commits that have been published after the latest release, also fetched by the GitHub API in app/generate/route.ts
Summarize the following commits fromSave the prompt, and it will be automatically updated in your your app – try it out! If you’re curious, you can also change the model here. The ability to iterate on and test your prompt is great, but writing a prompt in Braintrust is more powerful than that. Every prompt you create in Braintrust is also an AI function that you can invoke inside of your application.{{url}}since{{since}}in changelog form. Include a summary of changes at the top since the provided date, followed by individual pull requests (be concise). At the end of the changelog, include a friendly message to the user.{{commits}}
Running a prompt as a function
Running a prompt as an AI function is a faster and simpler way to iterate on your prompts and decide which model is right for your use case, and it comes out-of-the-box in Braintrust. Normally, you would need to choose a model upfront, hardcode the prompt text, and manage boilerplate code from various SDKs and observability tools. Once you create a prompt in Braintrust, you can invoke it with the arguments you created. In app/generate/route.ts, the prompt is invoked with three arguments:url, since, and commits.
stream to true. The result of the function call is then shown to the user in the frontend of the application.
Running a prompt as an AI function is also a powerful way to automatically set up other Braintrust capabilities. Behind the scenes, Braintrust automatically caches and optimizes the prompt through the AI proxy and logs it to your project, so you can dig into the responses and understand if you need to make any changes. This also makes it easy to change the model in the Braintrust UI, and automatically deploy it to any environment which invokes it.
Observability
Traditional observability tools monitor performance and pipeline issues, but generative AI projects require deeper insights to ensure your application works as intended. As you continue using the application to generate changelogs for various GitHub repositories, you’ll notice every function call is logged, so you can examine the input and output of each call.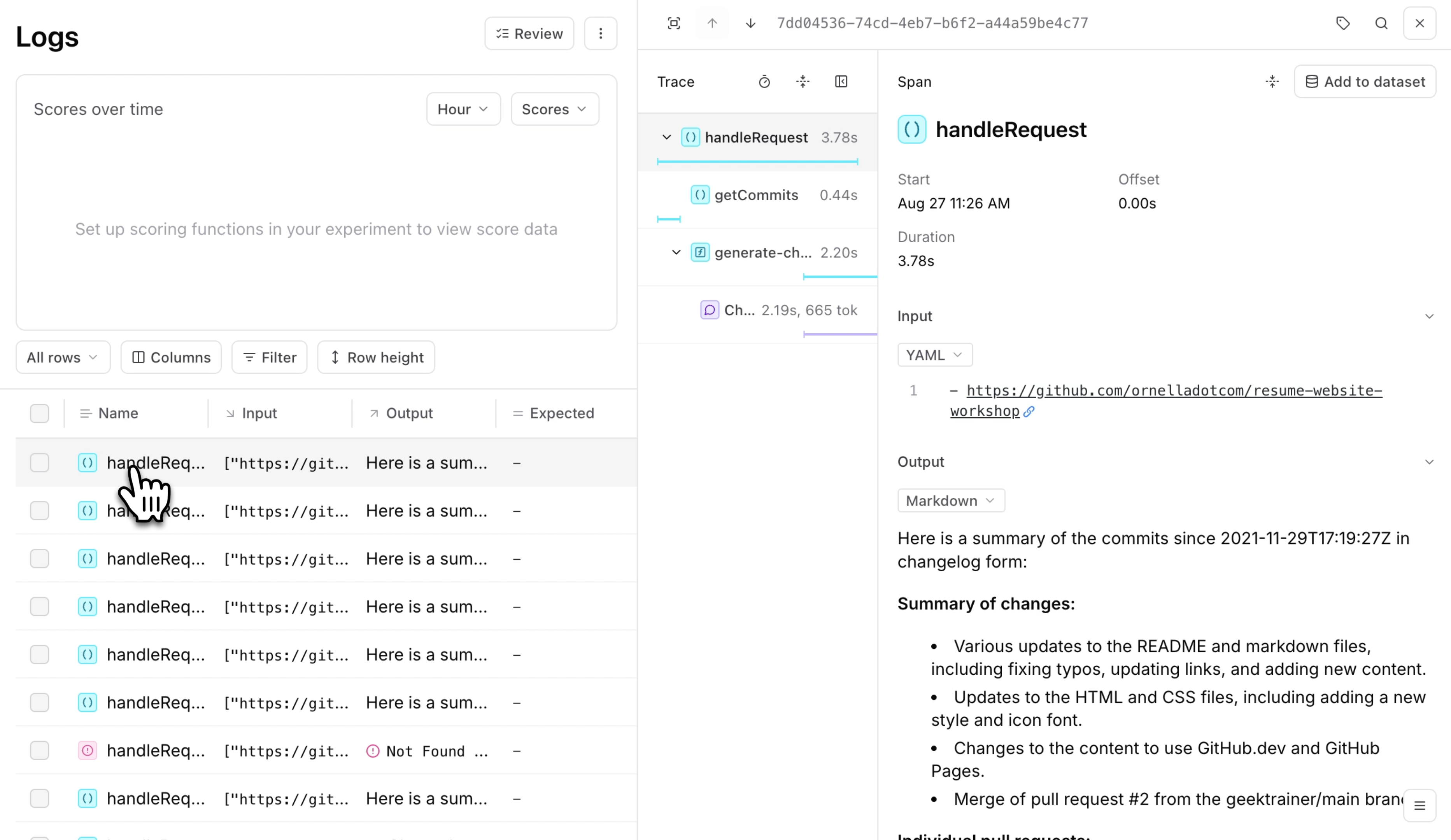
Scoring
To evaluate responses, we can create a custom scoring system. There are two main types of scoring functions: heuristics (best expressed as code) are great for well-defined criteria, while LLM-as-a-judge (best expressed as a prompt) is better for handling more complex, subjective evaluations. For this example, we’re going to define a prompt-based scorer. To create a prompt-based scorer, you define a prompt that classifies its arguments, and a scoring function that converts the classification choices into scores. In eval/comprehensiveness-scorer.ts, we defined our prompt as:Evals
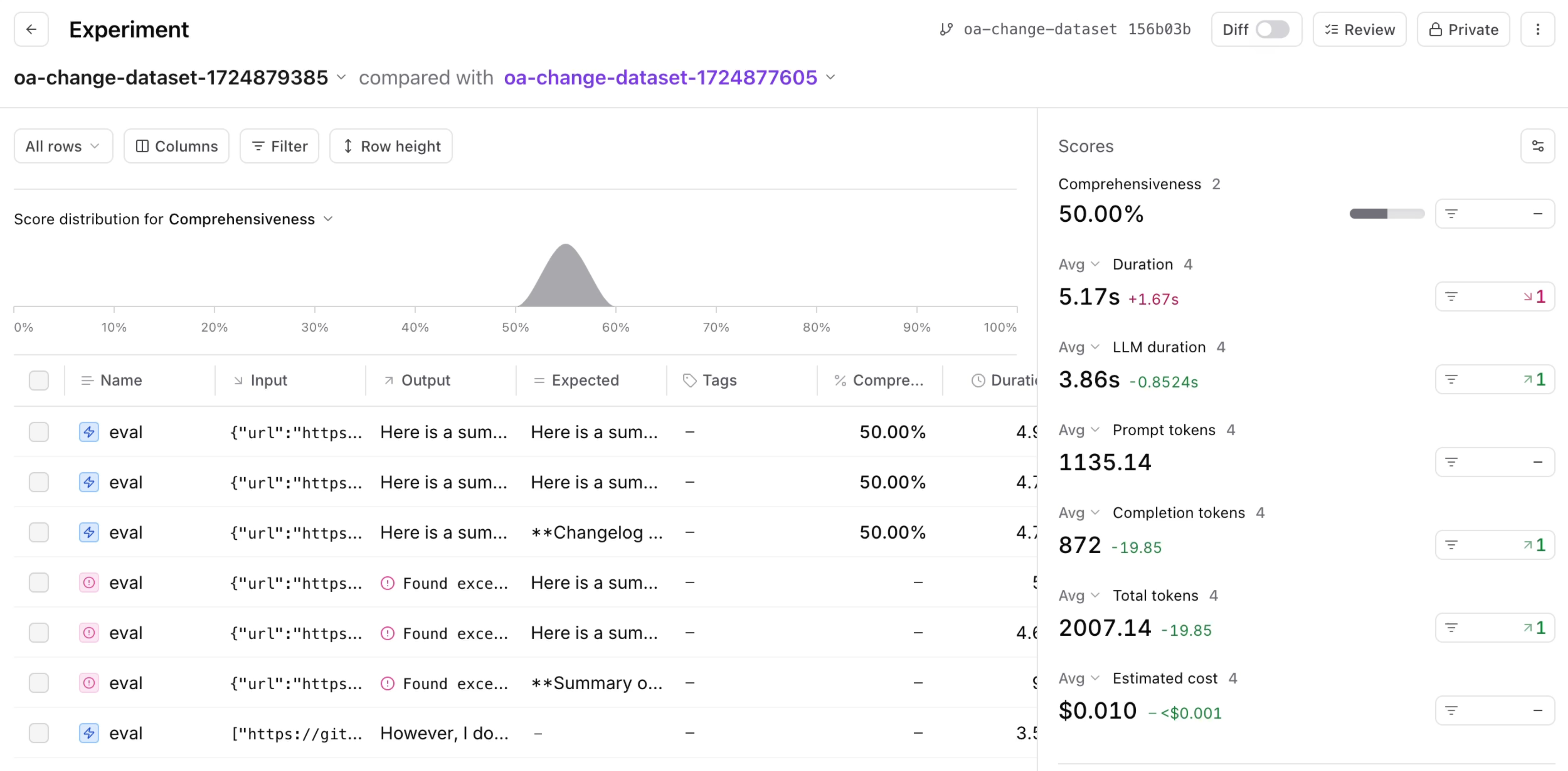
Now, let’s use the comprehensiveness scorer to create a feedback loop that allows us to iterate on our prompt and make sure we’re shipping a reliable, high quality product. In Braintrust, you can run evaluations, or Evals, if you have a Task, Scores, and Dataset. We have a task, which is theinvoke function we’re calling in our app. We have scores, the comprehensiveness function we just defined to assess the quality of our function outputs. The final piece we need to run evaluations is a dataset.
Datasets
Go to your Braintrust Logs and select one of your logs. In the expanded view on the left-hand side of your screen, select the generate-changelog span, then select Add to dataset. Create a new dataset calledeval dataset, and add a couple more logs to the same dataset. We’ll use this dataset to run an experiment that evaluates for comprehensiveness to understand where the prompt might need adjustments.
Alternatively, you can define a dataset in eval/sampleData.ts.
Now that we have all three inputs, we can establish an Eval() function in eval/changelog.eval.ts:
data parameter to:
() => [sampleData]
Running pnpm eval will execute the evaluations defined in changelog.eval.ts and log the results to Braintrust.
Putting it all together
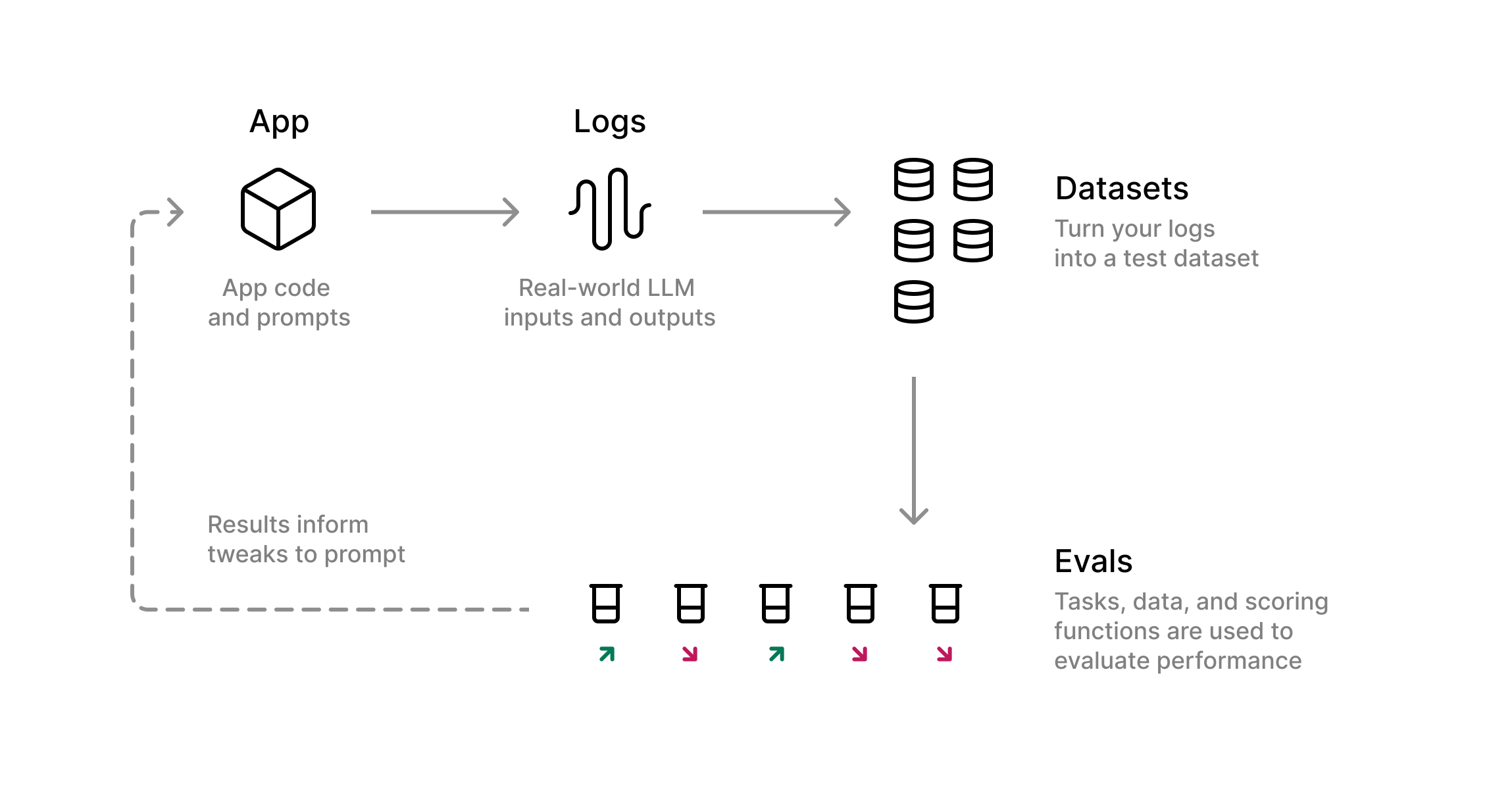
Scaling with Braintrust
As you build more complex AI products, you’ll want to customize Braintrust even more for your use case. You might consider:- Writing more specific evals or learning about different scoring functions
- Walking through other examples of best practices for building high-quality AI products in the Braintrust cookbook
- Changing how you log data, including incorporating user feedback