Contributed by John Huang on 2024-05-22
This tutorial will teach you how to use Braintrust to compare the same prompts across different AI models and parameters to help decide on choosing a model to run your AI apps.
Before starting, please make sure that you have a Braintrust account. If you do not, please sign up. After this tutorial, feel free to dig deeper by visiting the docs.
Installing dependencies
To see a list of dependencies, you can view the accompanying package.json file. Feel free to copy/paste snippets of this code to run in your environment, or use tslab to run the tutorial in a Jupyter notebook.Setting up the data
For this example, we will use a small subset of data taken from the google/boolq dataset. If you’d like, you can try datasets and prompts from any of the other cookbooks at Braintrust.Running comparison evals across multiple models
Let’s set up some code to compare these prompts and inputs across 3 different models and different temperature values. For this cookbook we will be using Braintrust’s LLM proxy to access the API for different models. All we need to do is provide abaseURL to the proxy with the relevant API key that we want to access, and the use the wrapOpenAI function from braintrust which will help us capture helpful debugging information about each model’s performance while keeping the same SDK interface across all models.
- A simple exact match scorer that will compare the output from the LLM exactly with the expected value
- A Levenshtein scorer which will calculate the Levenshtein distance between the LLM output and our expected value
Visualizing
Now we have successfully run our evals! Let’s log onto braintrust.dev and take a look at the results. Click into the newly generated project calledModel comparison, and check it out! You should notice a few things:
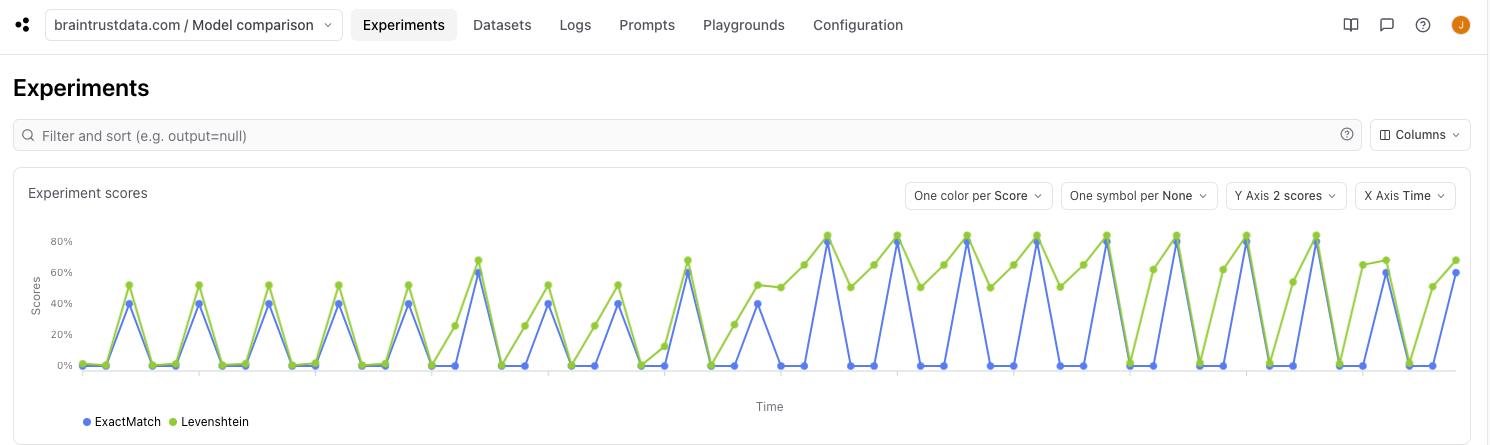
- Each line represents a score over time, and each data point represents an experiment that was run.
- From the code, we ran 60 experiments (5 temperature values x 4 models x 3 prompts) so one line should consist of 60 dots, each with a different combination of temperature, model, and prompt.
- Metadata fields are automatically populated as viable X axis values.
- Metadata fields with numeric values are automatically populated as viable Y axis values.
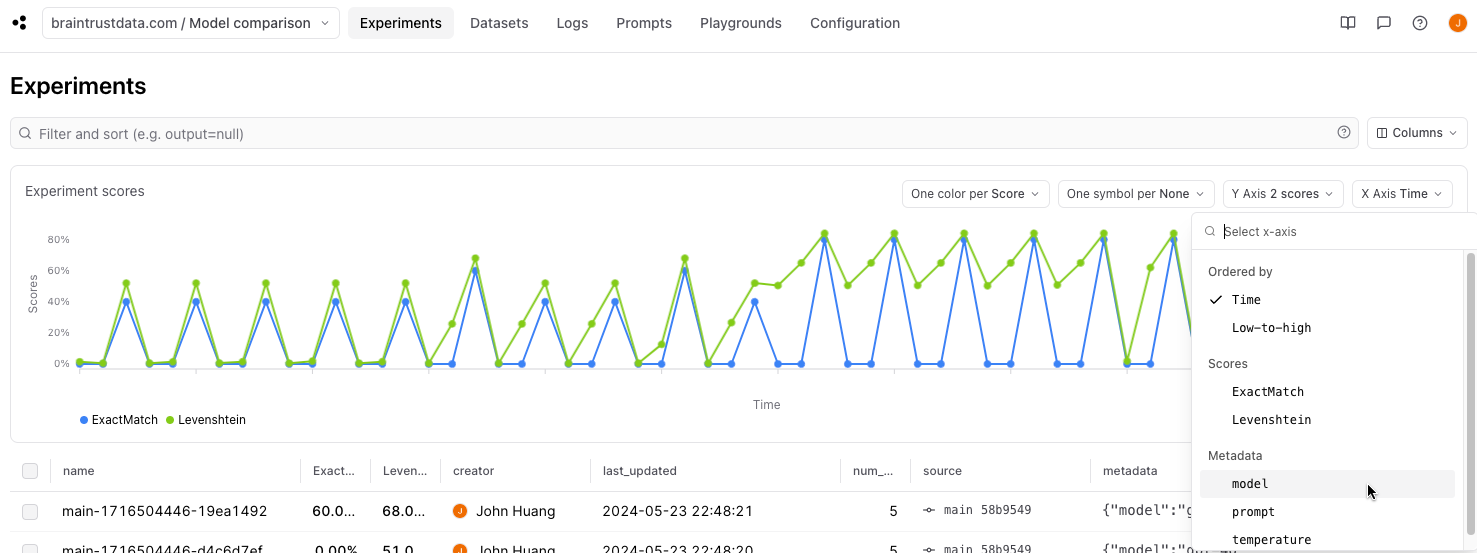
Diving in
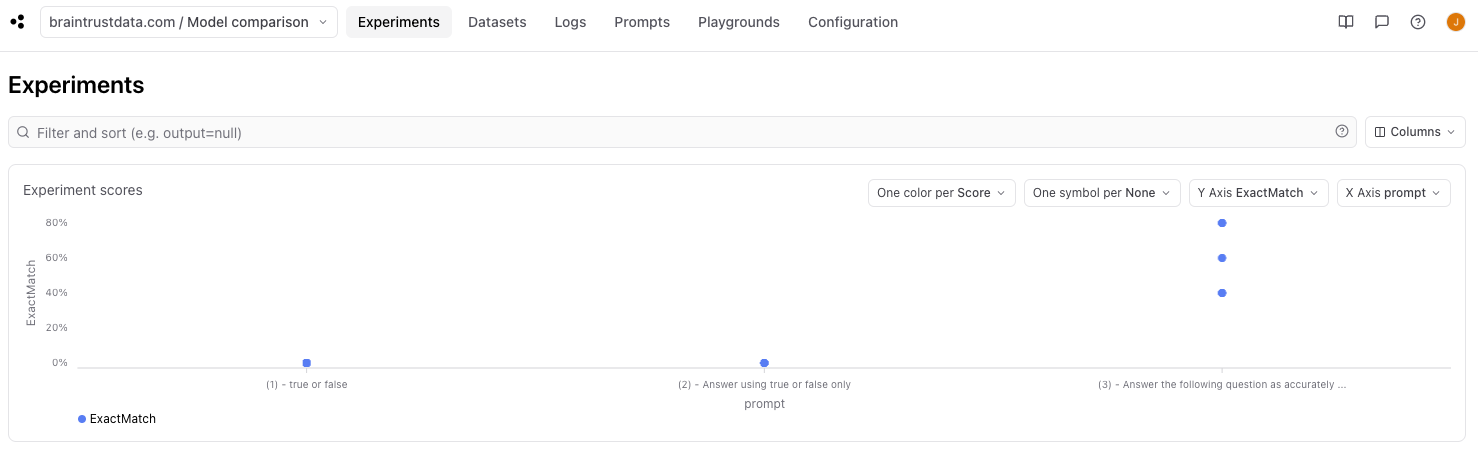
This chart allows us to also group data to allow us to compare experiment runs by model, prompt, and temperature. By selectingX Axis prompt, we can see pretty clearly that the longer prompt performed better than the shorter ones.
one color per model and X Axis model, we can also visualize performance between different models. From this view we can see that the OpenAI models outperformed the Anthropic models.
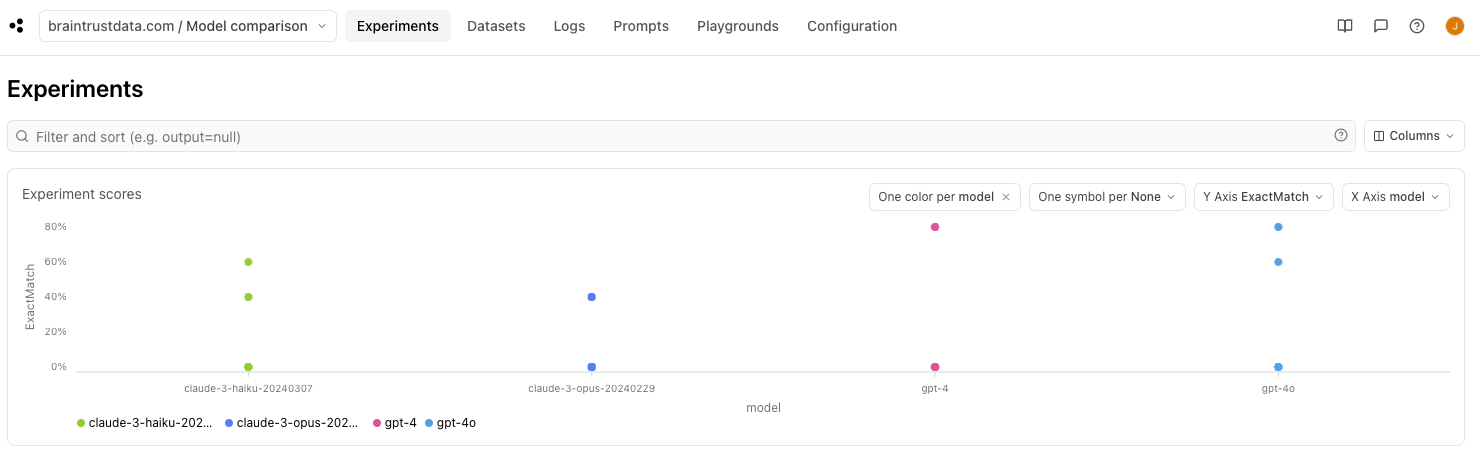
one color per model, one symbol per prompt, and X Axis temperature.
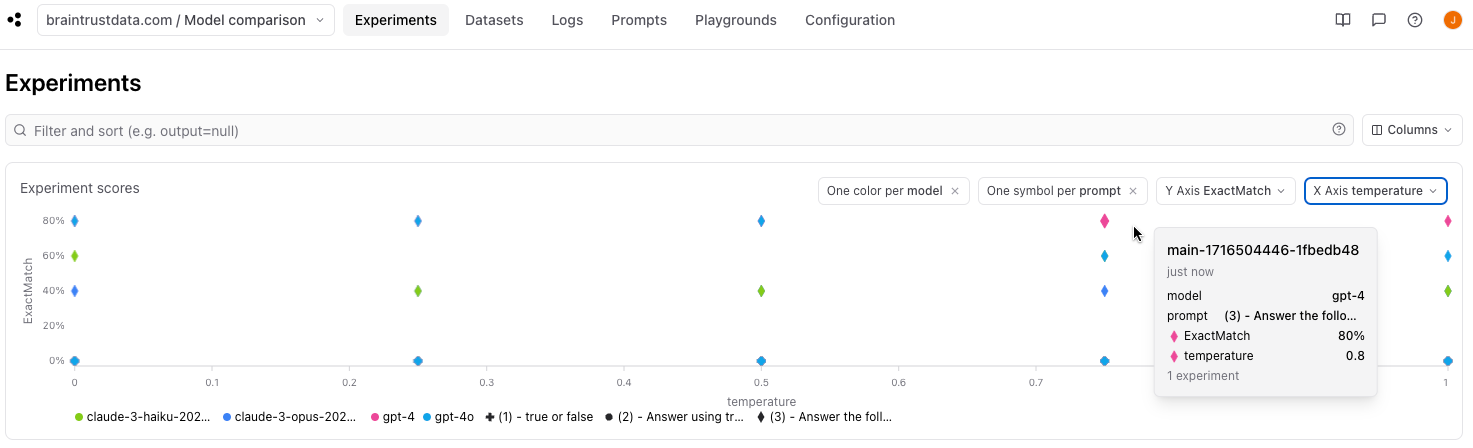
gpt-4 performed better than gpt-4o at higher temperatures!