autoevals library.
In this cookbook, we’ll walk through using a few Ragas metrics to evaluate a simple RAG pipeline that does Q&A on Coda’s help desk. We’ll reuse many of the components we built in a previous cookbook on RAG, which
you can check out to learn some of the basics around evaluating RAG systems.
Let’s dive in and start by installing dependencies:
Setting up the RAG application
We’ll quickly set up a full end-to-end RAG application, based on our earlier cookbook. We use the Coda Q&A dataset, LanceDB for our vector database, and OpenAI’s embedding model.Retrieving documents
To perform retrieval, we’ll use the same embedding model as we did for the document sections to embed theinput query, and then search for the
TOP_K (2) most relevant documents.
You’ll notice that here and elsewhere we’ve decorated functions with @braintrust.traced. For now, it’s a no-op, but we’ll see shortly how @braintrust.traced
helps us trace python functions and debug them in Braintrust.
Generating the final answer
To generate the final answer, we can simply pass in the retrieved documents and the original question to a simple prompt defined below. Feel free to tweak this prompt as you experiment!Combining retrieval and generation
We’ll define a convenience function to combine these two steps, and return both the final answer and the retrieved documents so we can observe if we picked useful documents! (Later, returning documents will come in useful for evaluations)Baseline Ragas metrics with autoevals
To get a large enough sample size for evaluations, we’re going to use the synthetic test questions we generated in our earlier cookbook. Feel free to check out that cookbook for details on how the synthetic data generation process works.ContextRecallcompares the retrieved context to the information in the ground truth answer. This is a helpful way of testing how relevant the retrieved documents are with respect to the answer itself.AnswerCorrectnessevaluates the generated answer to the golden answer. Under the hood, it checks each statement in the answer and classifies it as a true positive, false positive, or false negative.
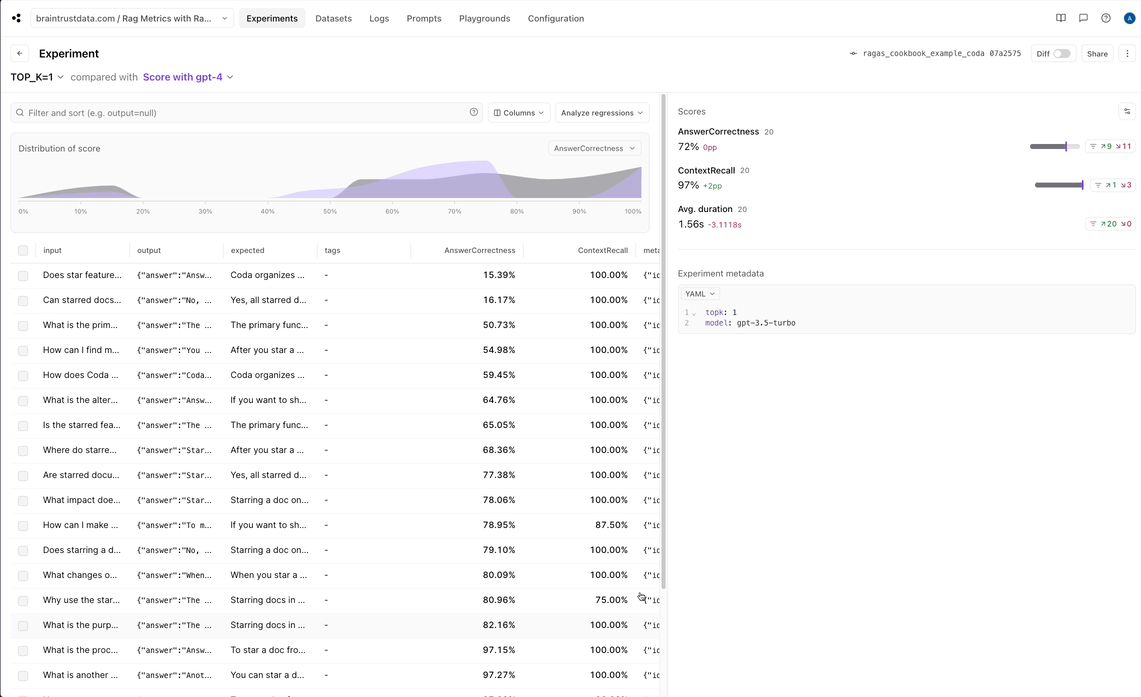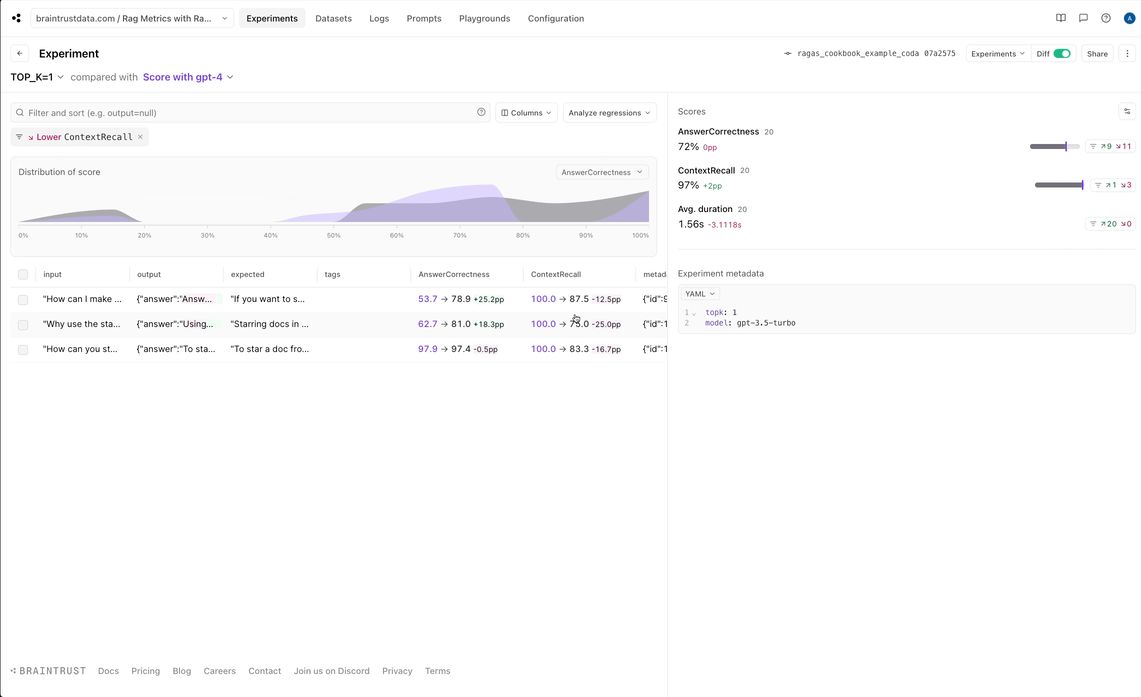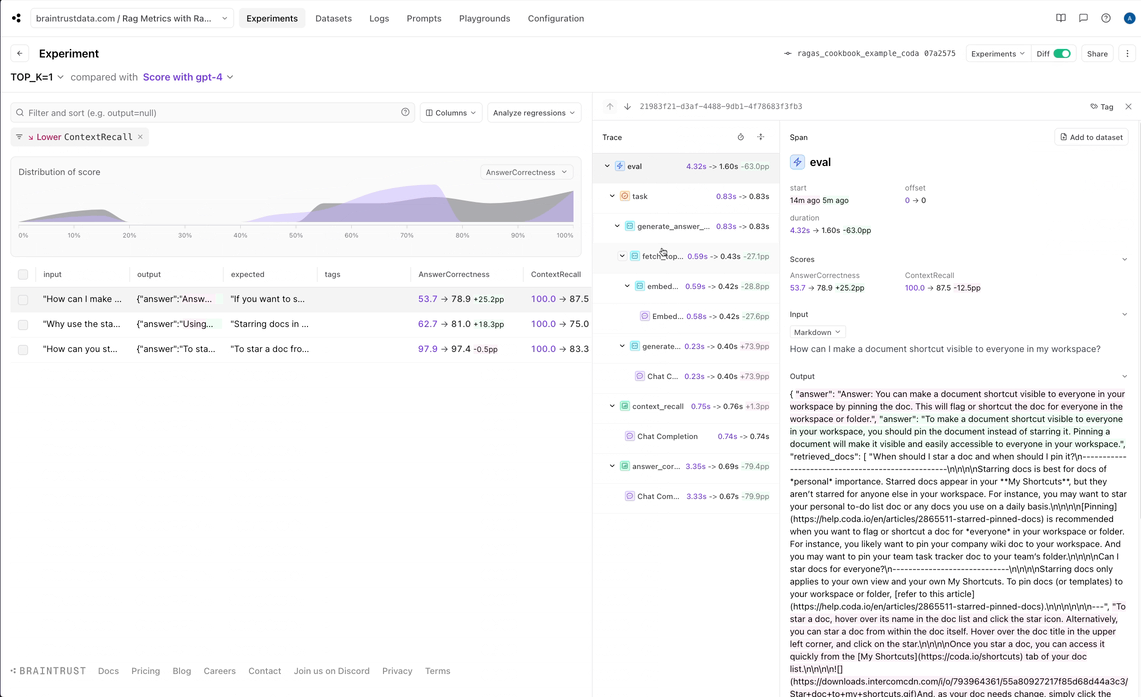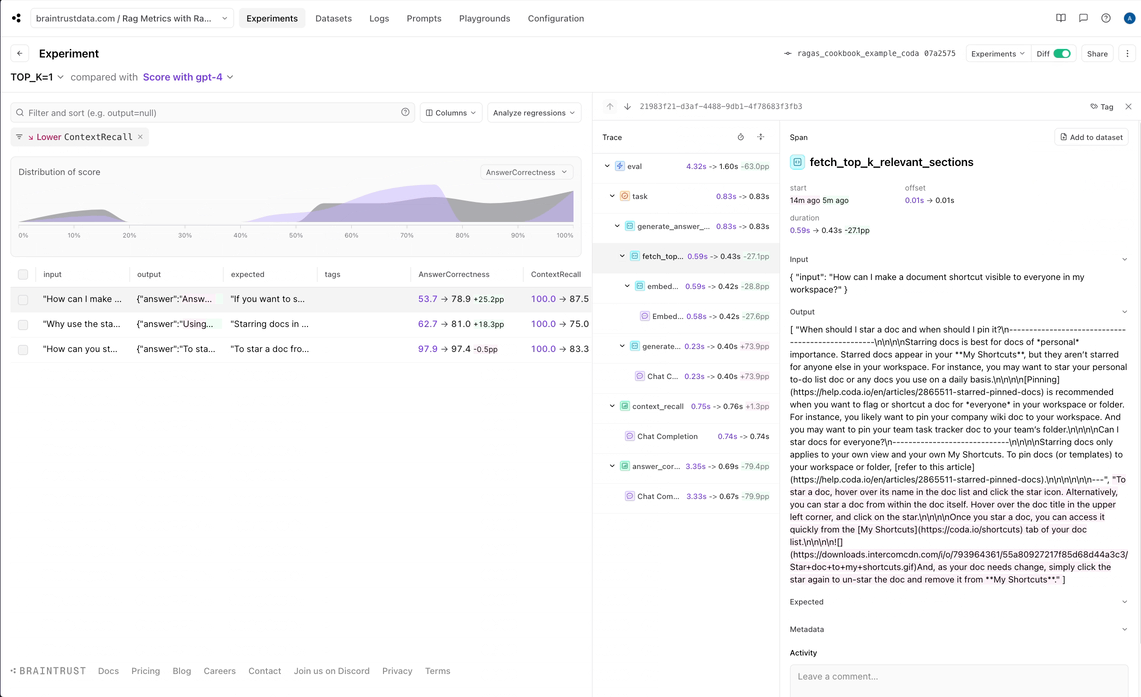
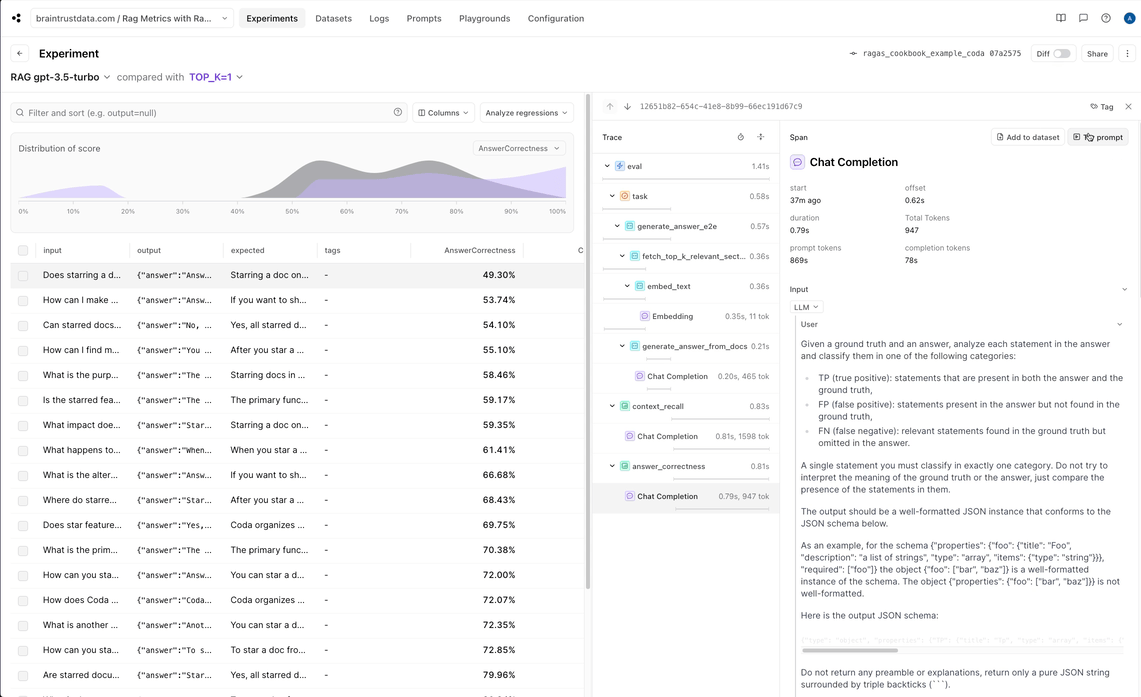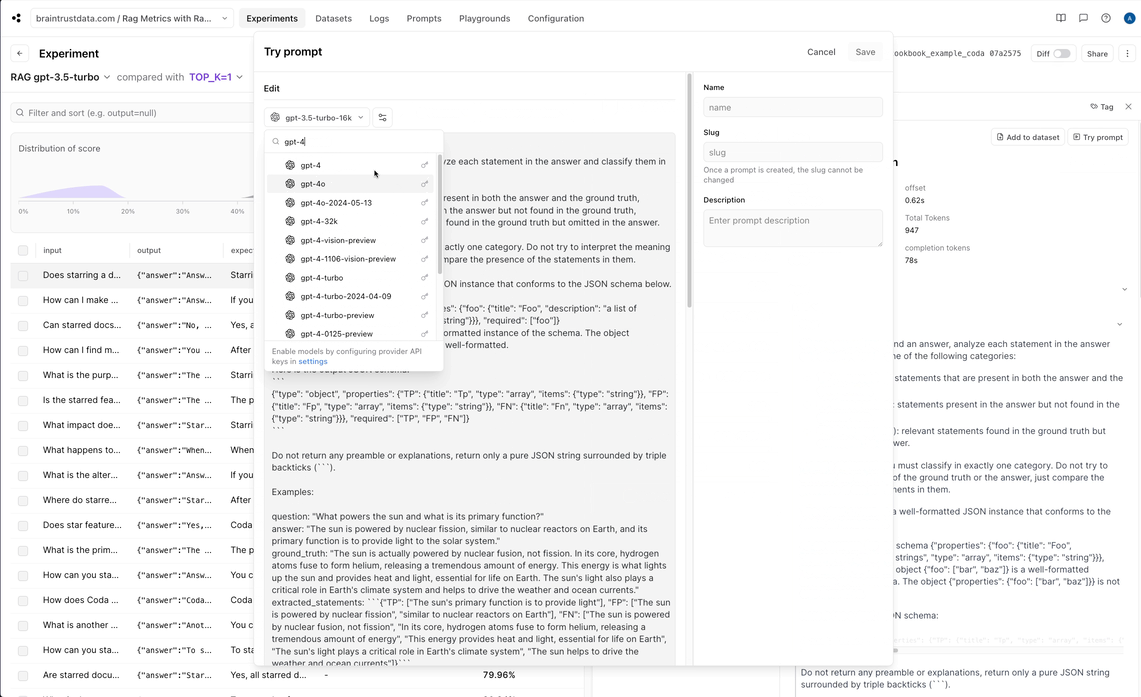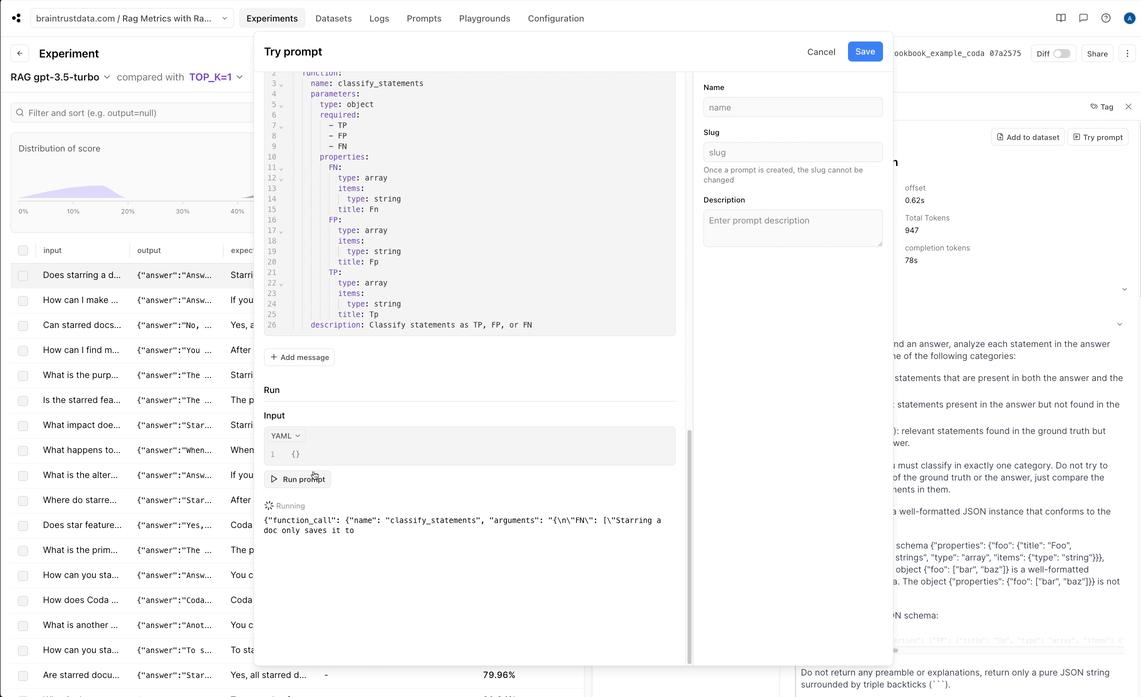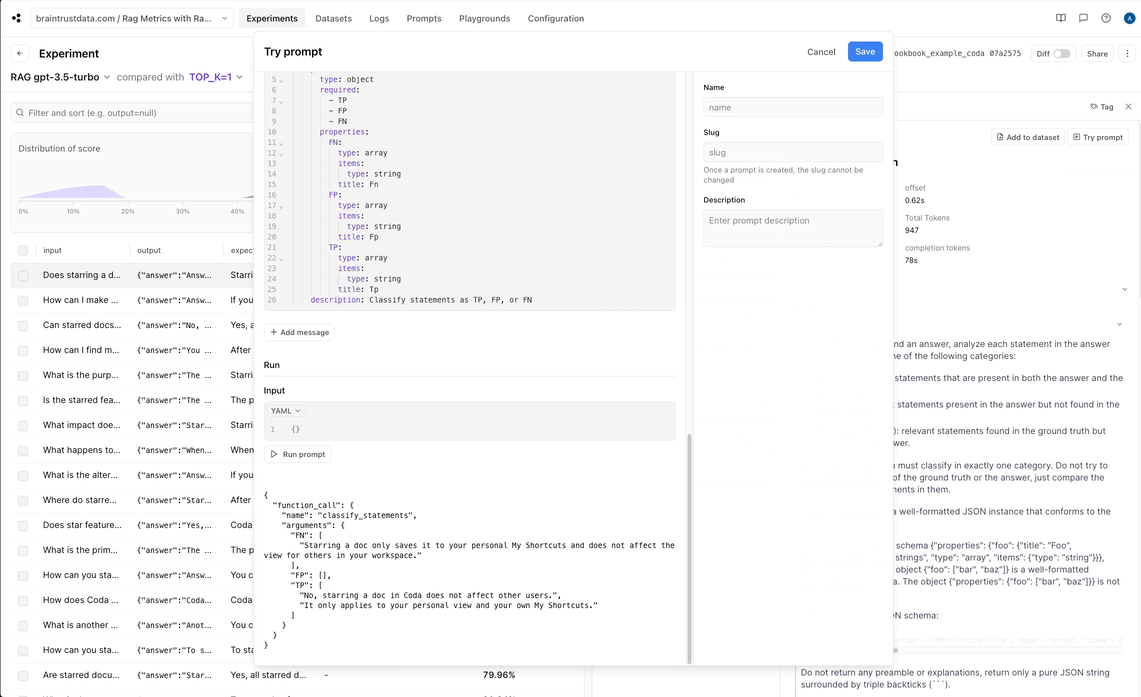
Interpreting the results in Braintrust
Although Ragas is very powerful, it can be difficult to get detailed insight into low scoring values. Braintrust makes that very simple. Sometimes an average of 67% means that 2/3 of the values had a score of 1 and 1/3 had a score of 0. However, the distribution chart makes it clear that in our case, many of the scores are partially correct:

No, starring a doc in Coda does not affect other users seems like a true, not false, positive.
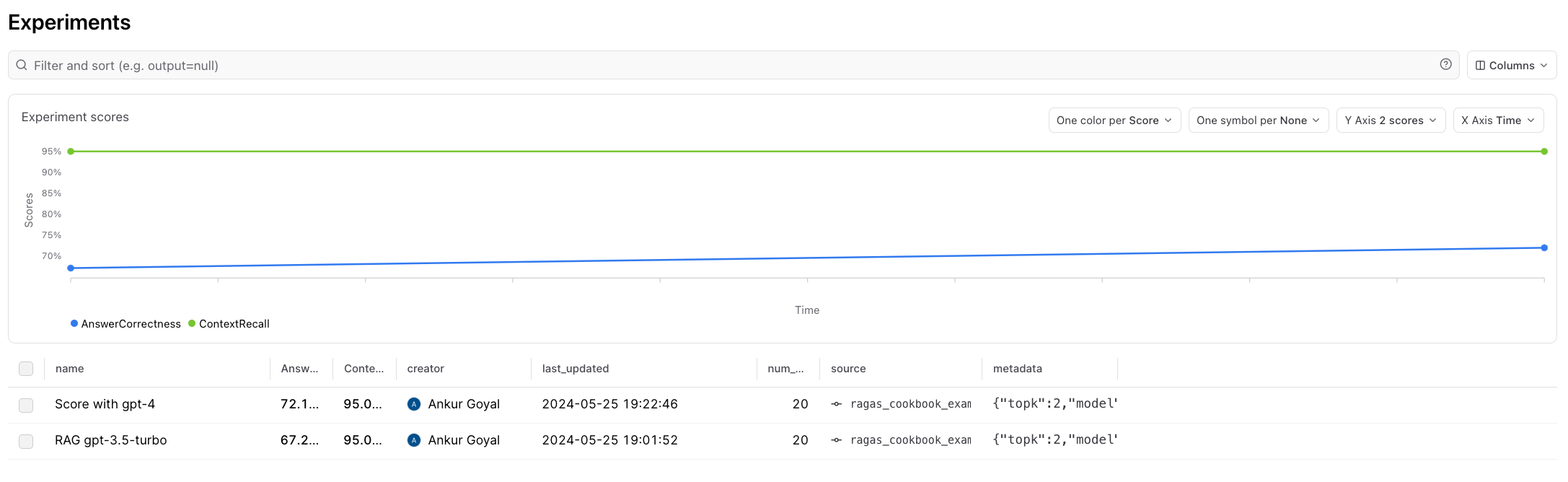
Let’s try changing the scoring model for AnswerCorrectness to be gpt-4, and see if that changes anything.
Swapping grading model
By default, Ragas is configured to usegpt-3.5-turbo-16k. As we observed, it looks like the AnswerCorrectness score may be returning bogus
results, and maybe we should try using gpt-4 instead. Braintrust lets us test the effect of this quickly, directly in the UI, before we run
a full experiment:
Optimizing document retrieval
Now, let’s see if we can further optimize our RAG pipeline without regressing scores. We’re going to try pulling just one document, rather than two.