Why aspirational evals are critical when new AI models launch
Today, Anthropic announced Claude Sonnet 4.5, achieving 77.2% on SWE-bench Verified, running autonomously for 30 hours, and setting new benchmarks across coding and reasoning tasks. While the AI community reacts to new models with benchmarks and hot takes on X, we focus on a grounded, data-driven approach.
The first thing we do when a new model comes out is run our aspirational eval suite to understand what new capabilities just became possible.
What are aspirational evals?
Aspirational evals are tests designed for capabilities that don't exist yet, where current models score around 10% but represent functionality you'd build immediately if the technology could support it. We started maintaining a set of aspirational evals around the time GPT-4o came out -- we had an idea for an AI assistant we wanted to build into Braintrust, but no model was scoring well enough on these evals to actually build the feature. Every time a new model came out, we swapped it in via the Braintrust Proxy, and reran the suite. When Claude Sonnet 4 crossed the success threshold in May, we built Loop in two weeks.
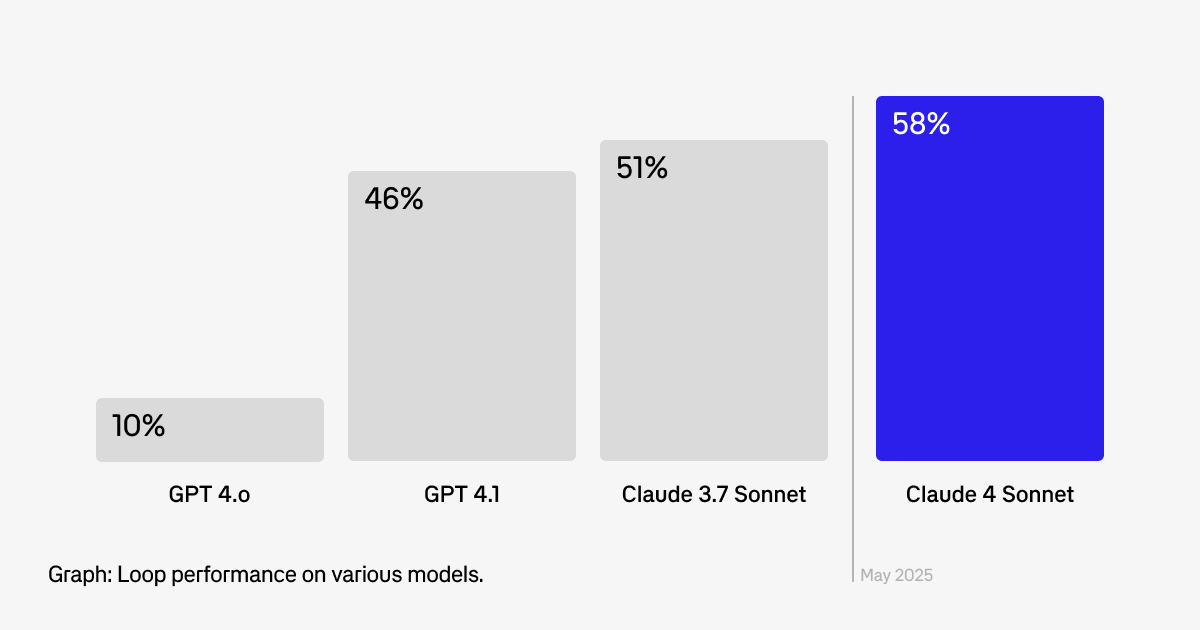
Unlike standard benchmarks that measure general performance, aspirational evals focus on your specific use cases: product features waiting for better reasoning, automation blocked by reliability issues, creative workflows limited by model constraints, and integration scenarios dependent on precision. We write these tests for our product roadmap and run them against every new model.
The capability cliff
AI capabilities typically improve in large leaps, where a model that completely fails at a complex reasoning task might excel at it in the next release. This is the "capability cliff," the moment when impossible becomes possible overnight. Consider the jump from Claude Sonnet 4 to 4.5: SWE-bench Verified jumped from ~40% to 77.2%, autonomous operation extended from 7 hours to 30+ hours, and OSWorld computer tasks improved from 42.2% to 61.4%. These can potentially represent new categories of viable applications rather than incremental improvements.
When new models launch, most teams follow a predictable cycle: engineering teams manually test obvious use cases in week one, product discussions about potential applications happen in month one, development begins on promising features in quarter one, and new functionality ships to market in quarter two. By then, early movers have typically captured the advantage.
Testing Claude Sonnet 4.5: our Loop evaluation
As we write this post, we ran our Loop eval suite against Claude Sonnet 4.5. One of the features of Loop is prompt optimization -- it can help you make your prompts better by analyzing the full context of your [evals](/docs/evaluate.
We ran unsupervised improvement experiments where Loop analyzes evaluation results and automatically improves prompts without human intervention. The evaluation measures Loop's ability to improve performance on various AI tasks by analyzing baseline results, suggesting optimizations, and re-running experiments. We tested both models across several experiments and averaged the results:
| Metric | Claude Sonnet 4 (avg) | Claude Sonnet 4.5 (avg) | Improvement |
|---|---|---|---|
avg_improvement_per_edit | 7.6% | 9.8% | +2.2% |
score_improvement | 14.3% | 21.9% | +7.6% |
| LLM duration | 6.5s | 5.3s | 1.2x faster |
Claude Sonnet 4.5's best run achieved 12.6% avg_improvement_per_edit and 29.6% score_improvement (5.2s LLM time), while Claude Sonnet 4's best run achieved 11.1% avg_improvement_per_edit and 21.6% score_improvement (6.2s LLM time). Overall, Claude Sonnet 4.5 delivers better optimization results with faster LLM inference times.
Building your own aspirational eval strategy
1. Infrastructure enables instant testing
The Braintrust Proxy makes model swapping trivial, so when Claude Sonnet 4.5 launched this morning, we updated a single configuration parameter and ran evals against the new model.
model: claude-sonnet-4-5
2. Start with high-impact scenarios
Identify the top 3-5 use cases where AI improvements would most dramatically impact your business and turn them into your core aspirational evals. Our evals focus on high-impact scenarios that directly translate to customer needs and requirements, with specific success thresholds and real datasets instead of synthetic benchmarks.
3. Design for specificity
Generic benchmarks tell you little about your specific opportunities, so build evals that mirror your exact use cases with your real data formats and constraints, your actual business logic and requirements, and integration with your existing systems and workflows.
4. Automate the testing pipeline
Manual evaluation is too slow for capability discovery, so set up automated pipelines that run immediately when new models become available, generate detailed reports on performance changes, and alert teams when success thresholds are crossed.
5. A culture that moves fast
When a new model comes out, drop everything and ship if it makes sense. While most teams spend months figuring out what new AI capabilities mean for their products, teams with aspirational evals are already shipping features that capitalize on new model announcements instead of reacting to them.
Braintrust provides the infrastructure to test new models instantly, run automated evaluations, and ship features faster. Book a demo to learn more.
Trace everything
Create an account or use agent setup to start building today.