Eval playgrounds for faster, focused iteration
Evaluations, or evals, are the secret ingredient for exceptional AI products. Crafting great prompts and choosing powerful models is important, but evals are what shape the reliability, usability, and ultimately, the success of AI systems. An eval is made up of clearly defined tasks (the scenarios your AI model needs to perform), scorers (success criteria), and datasets (the curated inputs that test your task’s capability).
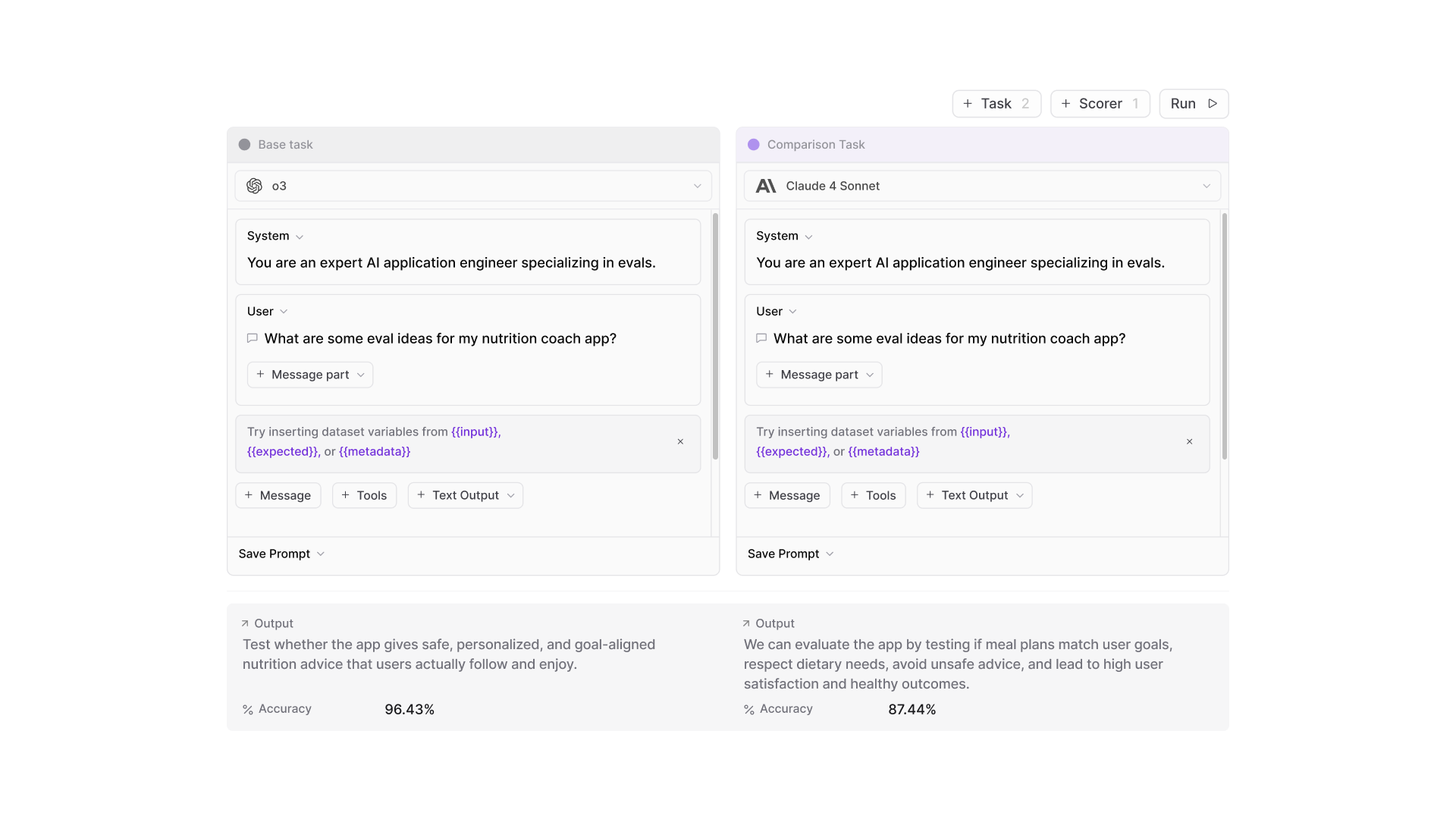
If you think of experiments in Braintrust like making a pull request to your repository, eval playgrounds are like editing and refining code in your IDE. We built eval playgrounds to complement experiments and provide an environment that significantly accelerates the iteration loop by letting you run full evaluations directly in a powerful editor UI.
A UX-first approach to evals
Playgrounds embed tasks, scorers, and datasets directly into a single intuitive UI. You can:
- Define and refine tasks to explore model and prompt performance
- Adjust scoring functions on the fly to immediately gauge the impact of changes
- Curate and expand datasets to explore more edge cases
Playgrounds maintain state and allow you to run the same underlying Eval capabilities as formal experiments. You can quickly iterate, refine, and optimize parameters before committing to a formal snapshot. This approach means you can experiment more freely, collaborate more effectively, and achieve higher productivity across your AI teams.
Why UX matters
Customers using eval playgrounds in production consider it to be a critical part of their eval workflow. To support their expanding needs, the Clinical AI team at Ambience Healthcare transitioned from earlier methods involving manual data handling and separate prompt repositories to a more cohesive and advanced toolkit with Braintrust. With playgrounds, they've:
- Reduced evaluation time by 50% with instant custom scorer editing.
- Tripled their dataset size capabilities, uncovering deeper insights.
- Leveraged collaborative real-time prompts, latency tracking, and trace comparisons, for clearer, faster, and more confident decision making.
Playgrounds fundamentally changed how we iterate—we move twice as quickly without sacrificing precision.
Differentiated by design
Evaluating an AI system has multiple parts: assessing nuanced decision-making, responsiveness to changing conditions, and safe outcomes, even in unpredictable environments. Eval playgrounds let you do all of this in one place by combining quick iteration, side-by-side trace comparisons, and scalable large dataset runs. This design enables AI teams to:
- Handle larger datasets
- Replace subjective assessments with objective, measurable metrics
- Integrate evaluation results into organizational workflows and decisions
Eval playgrounds provide the design-driven approach and rapid iteration necessary to turn good ideas into great business outcomes. Try playgrounds today to rapidly iterate towards better AI products.