GLM-5.2 vs. Opus 4.8 technical report
Why this eval
Most public coding benchmarks reward broad software-engineering behavior: debugging, planning, patch generation, and open-ended reasoning across a changing workspace. Those benchmarks are valuable, but they do not isolate whether a model can read a large supplied context and retrieve exact facts from it without falling back on memorized knowledge.
That stress test matters because long-context systems are often sold as if bigger windows automatically translate into usable recall. The RULER benchmark evaluated 17 long-context LLMs and found that nearly all exhibited large performance drops as context length increased despite their claims of 32k+ token windows.1 In practice, production workloads depend on a stack of behaviors: the model needs to attend to the right part of the prompt, the serving system needs to handle long prefixes efficiently, and the evaluation system needs enough instrumentation to tell accuracy and latency apart. A model can be strong at coding and still miss exact details buried in a long context; an endpoint can be fast on a single request and still behave differently under repeated cached calls.
Sparse‑attention architectures like GLM‑5.22 use content‑dependent indexing to keep long‑context compute under control, but they still pay a noticeable cost in indexer passes at million‑token scales. Under the hood, GLM‑5.2 pushes that cost down with cross‑layer index reuse ideas such as IndexCache,3 while providers focus on kernel‑level and systems‑level work. We built this eval to stress test the production question around the model: can a serving provider make this kind of sparse‑attention stack fast, stable, and cost-effective under real long‑context workloads. As Baseten’s GLM‑5.2 engineering posts highlight,2, 4 serving this model requires implementing inference engine support for sparse attention as well as accelerating inference with techniques like KV-aware routing, speculative decoding, and PD disaggregation.
Braintrust makes that stress test measurable by collecting row-level scores, traces, cache signals, retries, TTFT, total latency, and cost in the same eval.
CPython's standard library gives us a useful testbed because it is deterministic, real, and structurally rich. The questions are generated from AST (Abstract Syntax Tree - the structured intermediate representation of source code that captures syntactic and semantic information while discarding formatting details like whitespace and comments; see Python's ast module documentation for the full grammar5) facts: return annotations, class locations, base classes, module-level function counts, decorators, and docstring first lines. That makes the ground truth machine-checkable and keeps the task anchored in retrieval rather than subjective code review.
Why CPython
CPython is the reference C implementation of the Python language specification, maintained in the CPython source repository.6 This distinction matters: Python is a language specification; CPython is one and by far the most widely deployed implementation of that specification. The Lib/ directory of the CPython repository contains approximately 300+ pure-Python standard library modules, totaling hundreds of thousands of lines of idiomatic, production-quality code written and reviewed by Python's core developers.
Several properties make the CPython standard library an unusually clean eval corpus for this purpose:
Determinism and version-pinning. Every CPython release is tagged in Git, meaning a specific commit hash corresponds to exactly one version of the source. The corpus referenced in this eval is pinned to a specific release, ensuring complete reproducibility across experimental runs.
AST-parseability without external dependencies. Every .py file in Lib/ can be parsed into an AST using Python's own ast module with zero external dependencies. This enables programmatic extraction of function signatures, docstrings, class hierarchies, decorators, and return annotations without executing the code.
Authoritative ground truth. The standard library's docstrings and type annotations were written by the same engineers who wrote the code. Questions derived from them have verifiable, text-grounded answers that are not subject to interpretation.
Contamination controls, not guarantees. CPython is public, heavily indexed, and present in many code corpora, so the standard library should not be treated as contamination-free. Recency is useful as a heuristic, especially for Python 3.14 and the smaller number of genuinely new 3.13 additions, but it is a weaker argument for Python 3.12, which was public long enough to appear in tutorials, release notes, blog posts, and model training windows. The eval therefore leans less on "newness" as proof of novelty and more on pinned source, exact AST-derived facts, context-size comparisons, and perturbation rows that modify the supplied context.
Notably, no major existing benchmark uses CPython's Lib/ directory directly as a primary retrieval corpus. The closest is CRUXEval, which uses 69 standard library function names as generation seeds for 102,000 functions - but the stdlib source itself is not the retrieval context.7 The popular SWE-bench evaluates patch generation across 12 popular Python third-party repositories,8 while RepoQA tests needle-function retrieval over 50 third-party repos.9
This eval targets a specific gap: it stress tests exact retrieval over a standard library source, using AST-derived questions where the answer exists exactly once in the supplied context and the ground truth is machine-verifiable.
The crux of this eval is context-size pressure. T25 and T50 use prefix-aligned corpus tiers, so we can stress test how accuracy and latency move as the prompt grows. If a model is answering from weights or broad prior knowledge, it may still succeed on familiar APIs and structural patterns, especially for older or well-documented standard library behavior. The sharper signal comes from exact source-local questions and a set of synthetic perturbation rows: if a real symbol is renamed only inside the injected context, a model reading the window should follow the modified source, while a model leaning on memorized associations should be more brittle.
The broader consideration is that infrastructure matters alongside model quality. Baseten's GLM-5.2 serving stack is designed to make long-context inference practical; Artificial Analysis reports Baseten at 285.3 output tokens per second for GLM-5.2 in its provider benchmark view.10
Methodology
We built two Braintrust datasets from the CPython standard library to stress test exact retrieval at increasing context pressure: cpython-stdlib-T25 and cpython-stdlib-T50. Each dataset contains 100 rows, and each row includes a natural-language question, the full tier-specific context blob, expected ground truth, and metadata such as question type, source file, difficulty, and AST node type. Running the same rows against GLM-5.2 and Opus 4.8 keeps the comparison controlled: same prompts, same expected answers, same scorers, and the same cold-versus-warm call structure.
The final comparison used 500 model calls per model: 300 calls on T25 (100 questions x 3 trials) and 200 calls on T50 (100 questions x 2 trials). The first call for each row is the scored answer; the repeated calls are used for latency and cache observation. In the three-trial runs, the task function makes these sequential calls against the same row:
- A cold call, whose answer is scored.
- A first warm call, used for latency/cache observation.
- A second warm call, also used for latency/cache observation.
The GLM-5.2 task uses Baseten's OpenAI-compatible endpoint. The Opus 4.8 task uses Anthropic prompt caching with the context block marked as cacheable.11 Braintrust wraps both clients, captures token and cache metrics, and records custom timing metrics such as time to first token and total latency on child spans.
One limitation is that the eval answers are intentionally short. GLM-5.2 also claims output-side gains through Multi-Token Prediction and speculative decoding, including a longer draft window and more accepted tokens per pass. This eval records TTFT and total latency, but it primarily stresses long-context retrieval, prefix reuse, and cache behavior; it does not stress GLM-5.2's long-output advantage.
Scoring uses three complementary signals:
- ASTSemanticMatch: deterministic primary scorer aligned to each AST-derived question type.
- SubstringMatch: lenient recall scorer for simple expected-answer containment.
- FactualityJudge: an LLM-based audit scorer using nvidia/NVIDIA-Nemotron-3-Ultra-550B-A55B on Baseten.
Questions and hypotheses
We designed the eval around six questions that separate model retrieval quality from scoring behavior, context length, question type, and serving dynamics.
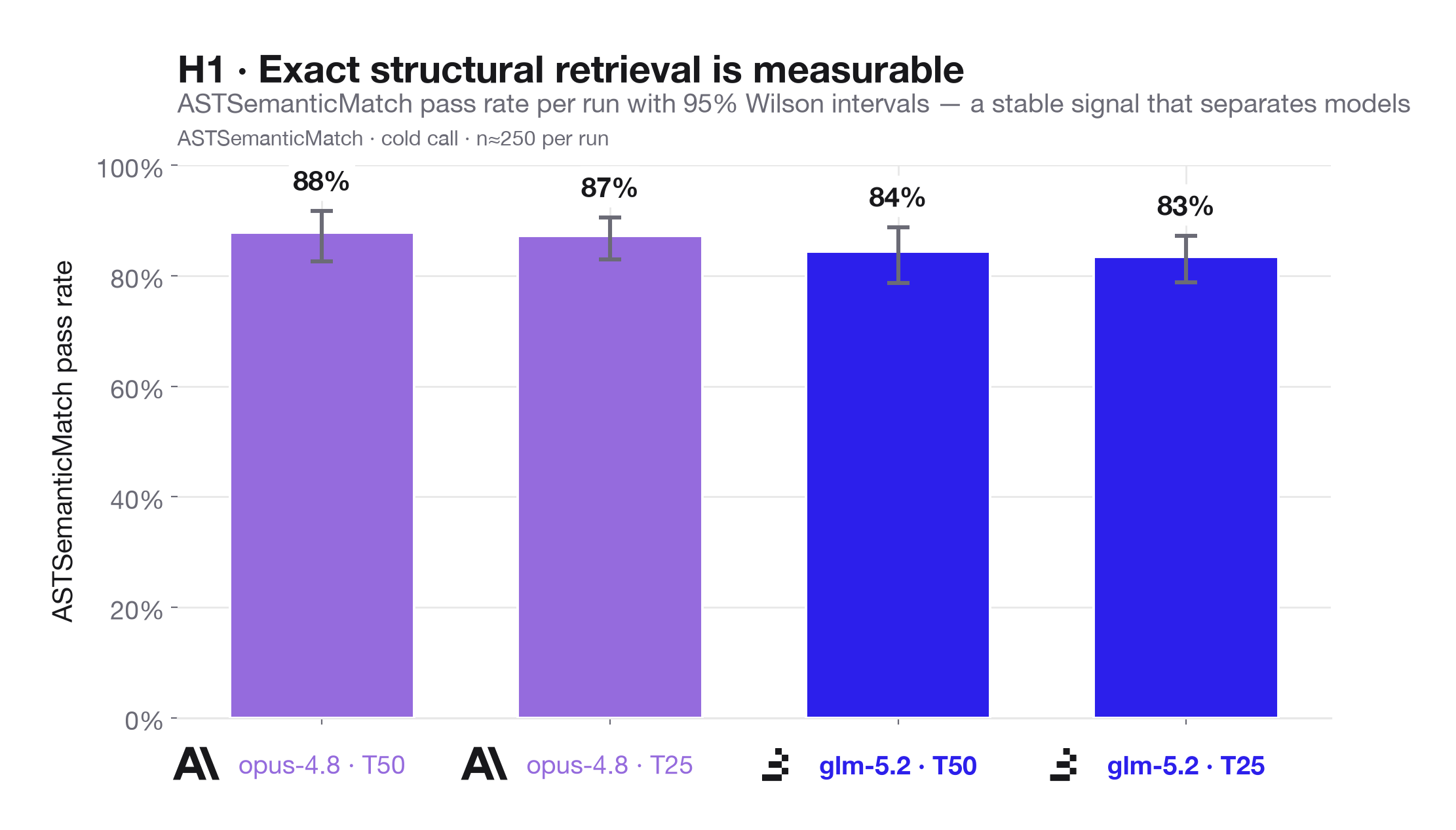
H1: Exact structural retrieval is measurable with deterministic scoring. For questions whose answers can be expressed as AST-derived facts, ASTSemanticMatch should provide the primary pass/fail signal. If a model retrieves the relevant structure from context, it should match exact function counts, class locations, base classes, decorators, return annotations, and docstring first lines according to type-specific rules.
The observed ASTSemanticMatch rates are stable enough to separate the two models while keeping uncertainty visible across the pooled cold-call runs.
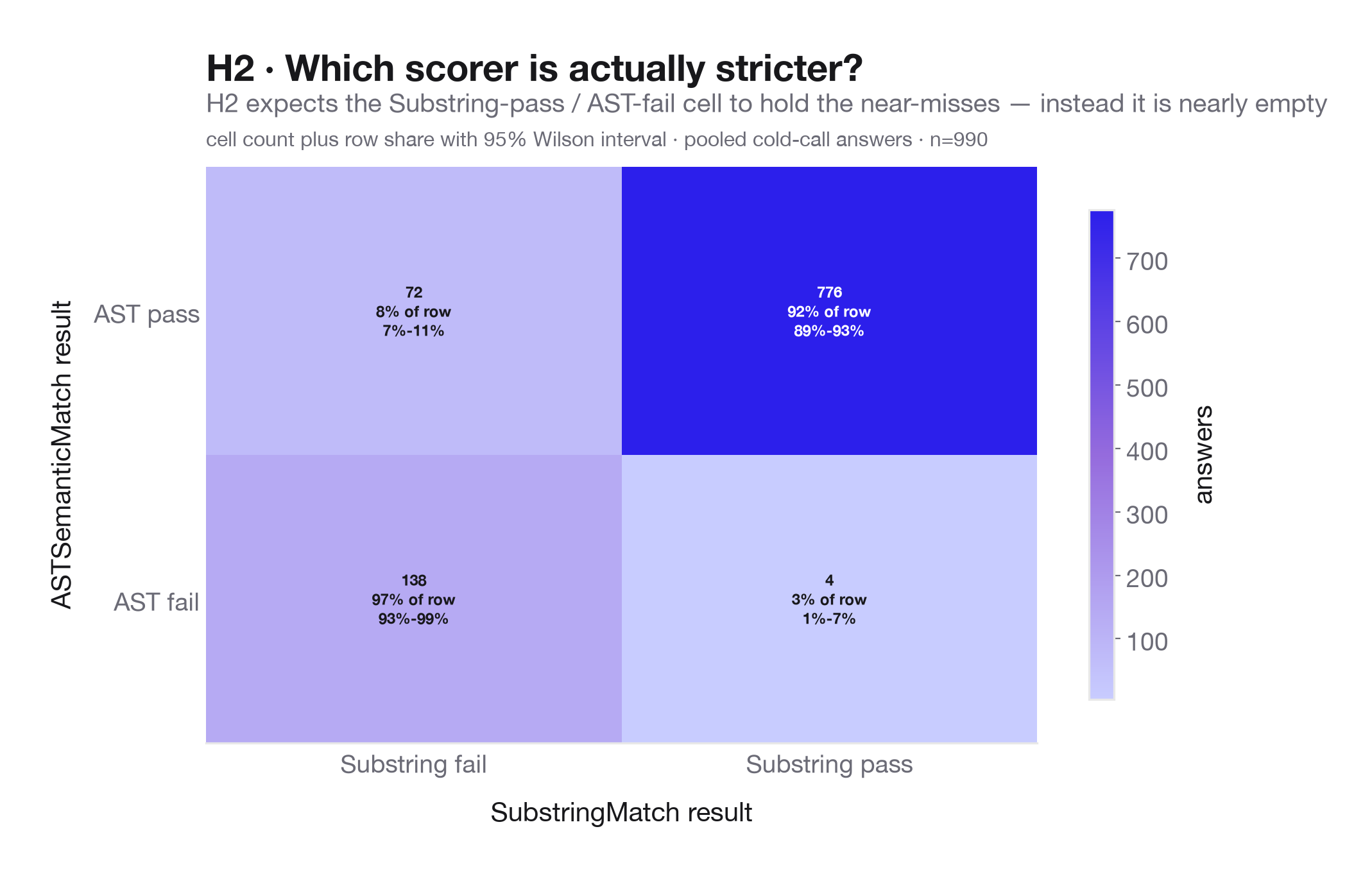
H2: Near-misses and formatting differences are separable from semantic failures. SubstringMatch was intended as a permissive recall check against ASTSemanticMatch, so disagreement between the two scorers helps identify cases where a model included the expected answer but failed the stricter structural criterion. This lets us distinguish true retrieval failures from answer-formatting or phrasing issues.
In practice, the expected near-miss cell is nearly empty: only four pooled answers pass SubstringMatch while failing ASTSemanticMatch, which suggests most failures are semantic retrieval misses rather than minor formatting misses.
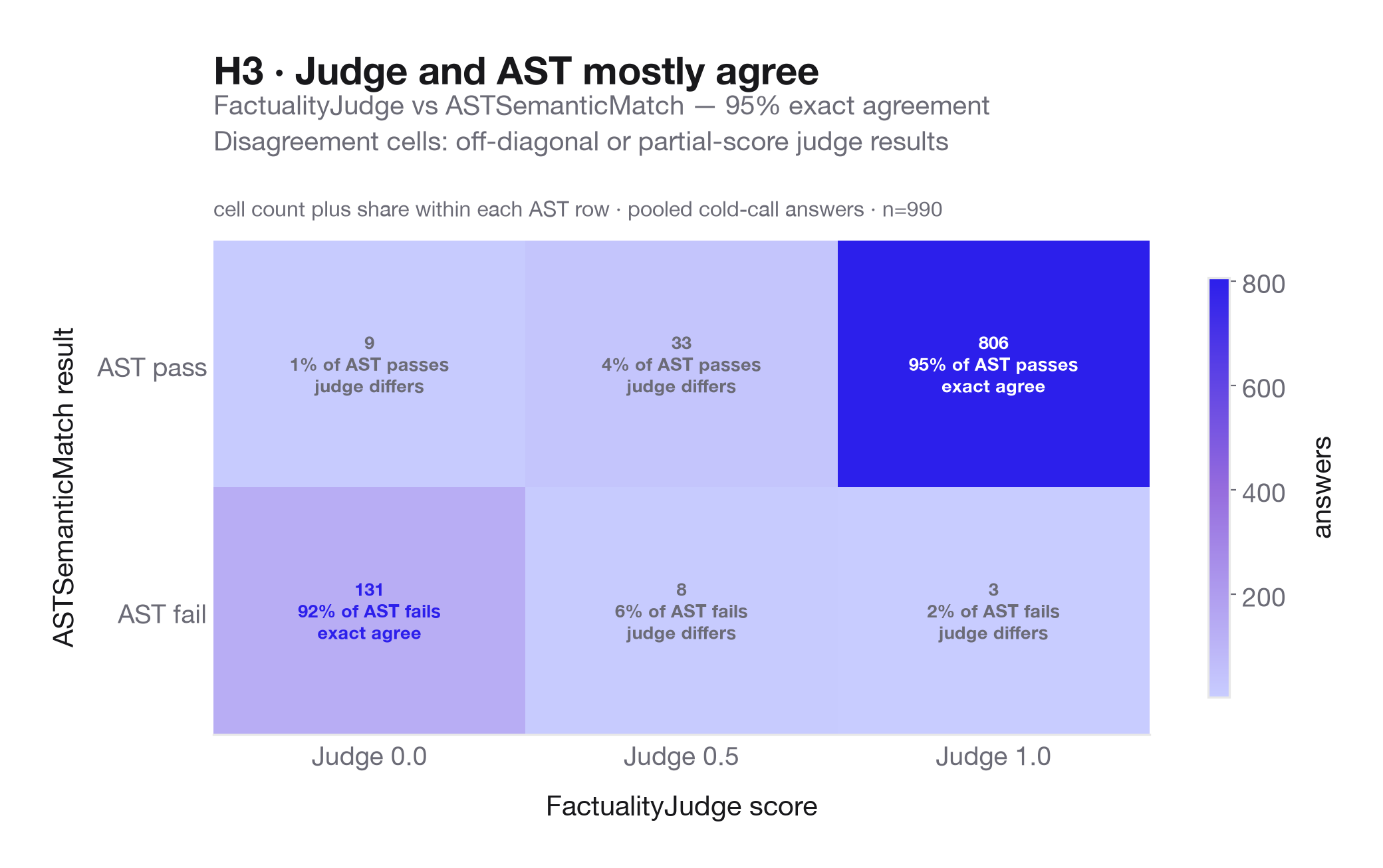
H3: Model-judged factuality can audit the deterministic scorers without replacing them. FactualityJudge gives a third signal for ambiguous or partially correct answers, especially where semantic equivalence is hard to capture with string rules alone. We expect it to agree broadly with ASTSemanticMatch, and the interesting cases are scorer disagreements: they tell us where deterministic scoring is too strict, too lenient, or missing a nuance.
The judge broadly agrees with the AST scorer, with off-diagonal cells serving as the audit set for where deterministic scoring and model judgment diverge.
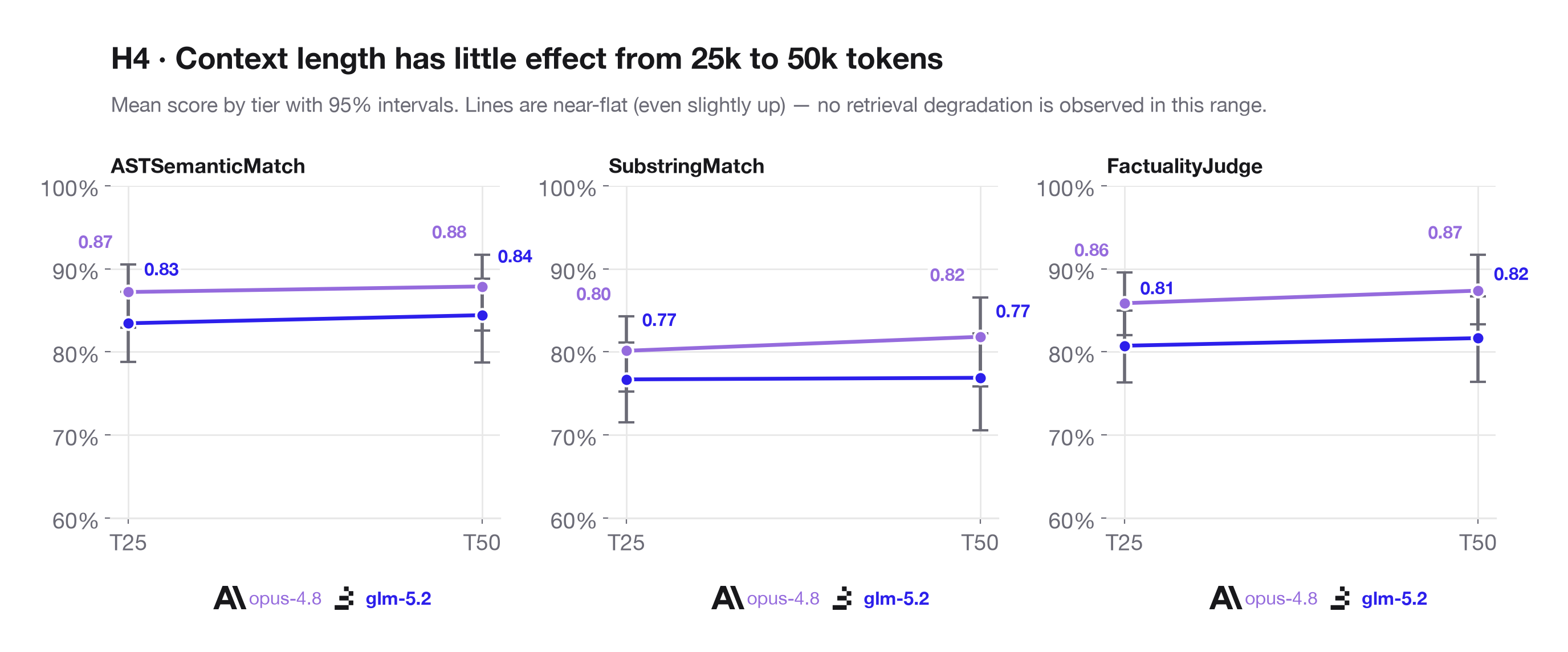
H4: Context length should have an observable effect on retrieval fidelity. T25 and T50 use the same eval design at different context sizes, so score changes across tiers stress test whether exact retrieval becomes harder as the prompt grows. For GLM-5.2, this is also the sparse-attention fidelity test: does selecting a content-dependent subset of tokens preserve exact retrieval of source-local facts under context pressure? A drop from T25 to T50 would suggest context-size sensitivity; flat scores would suggest robust retrieval across this range.
Across 25k to 50k tokens, the score lines are near-flat or slightly higher at T50, so this run does not show retrieval degradation over the tested range.
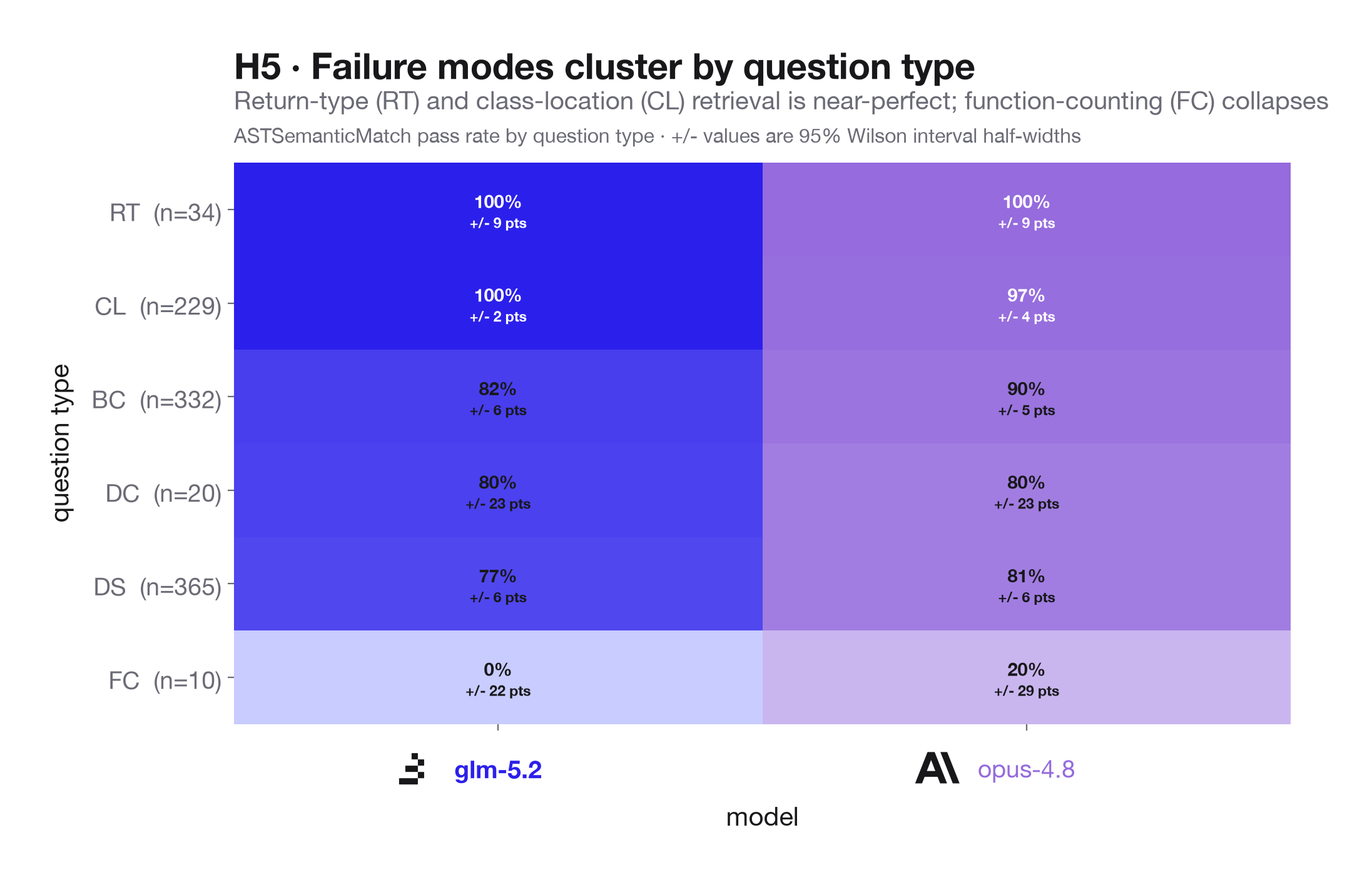
H5: Question type should expose different failure modes. Because each row is tagged by question type, we can compare performance across return types, class locations, base classes, function counts, decorators, and docstring first lines. This helps test whether failures cluster around counting, path retrieval, list/set completeness, or free-form text extraction rather than treating accuracy as a monolith.
The failures do cluster by question type: return-type and class-location retrieval are near-perfect, while module-level function counting is the weakest category in this sample.
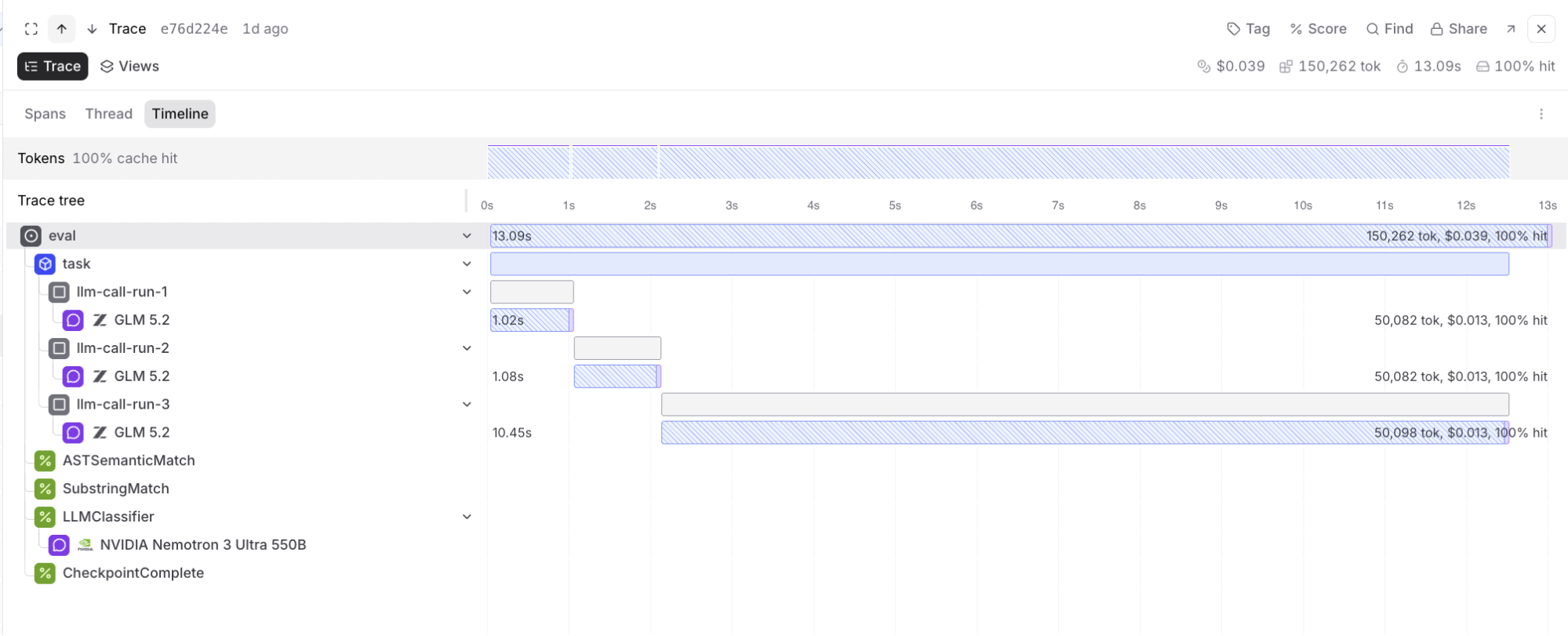
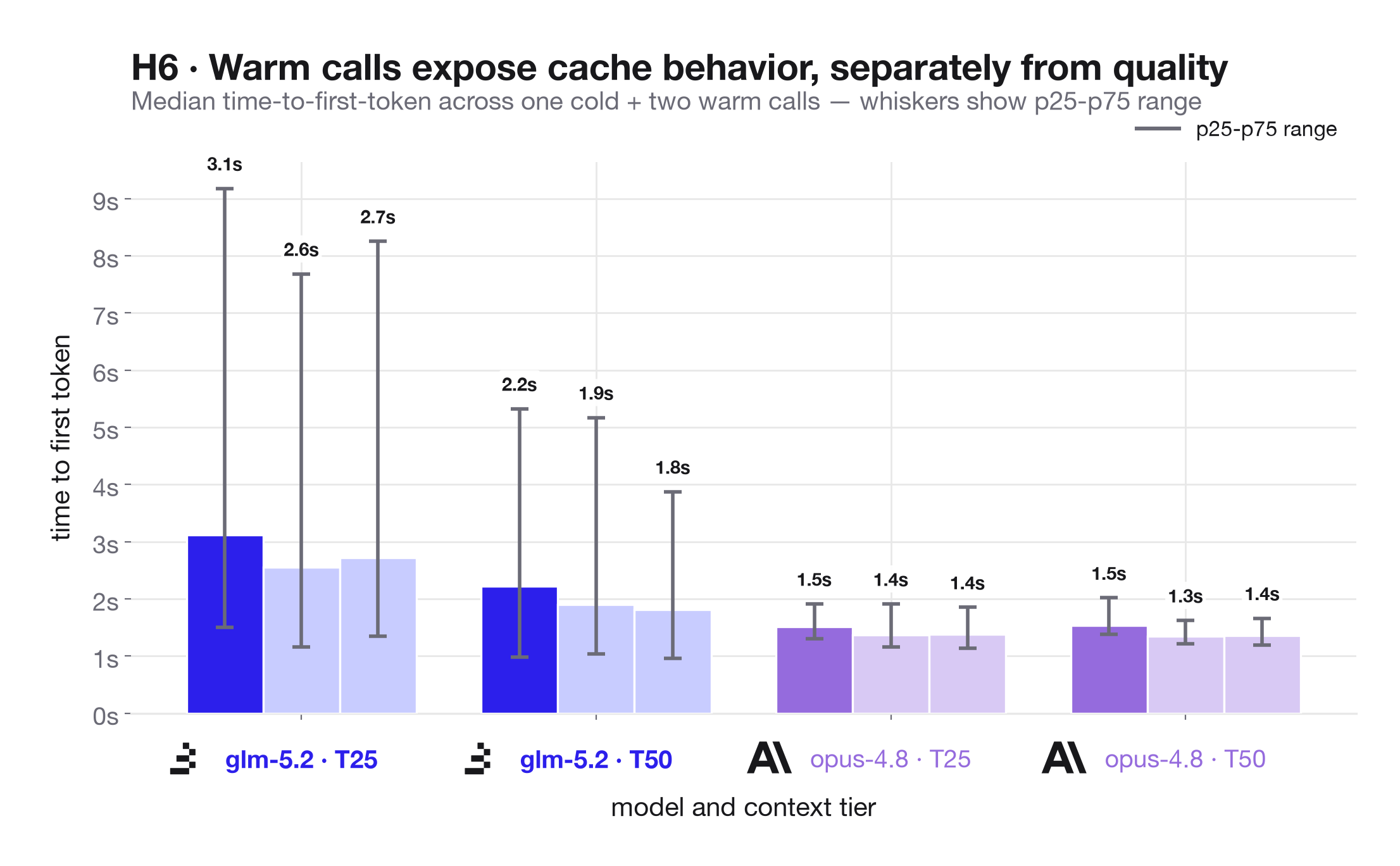
H6: Warm-call traces should expose serving behavior independently of answer quality. Each task performs one cold call followed by two warm calls over the same context. The scored output comes from the cold call, while warm calls let us inspect cached-prefix usage, time to first token, and total latency without conflating retrieval quality with cache dynamics. For GLM-5.2, these traces are a proxy for the hard systems part of sparse attention: whether the served endpoint turns the model's architectural efficiency into stable latency in repeated long-context calls.
The warm-call traces show lower median time-to-first-token than cold calls, especially for the Opus T50 cached-prefix path, confirming that the latency instrumentation is measuring a behavior distinct from answer quality.
A single GLM trace makes the caching behavior concrete. In the Braintrust span view, the warm follow-up call carries almost the entire prompt as cached input tokens, while the short question suffix remains new work. That is the cache-hit story we care about: the trace does not merely show a faster second request, it exposes provider-side cached-token accounting for the repeated long prefix. For long-context production loops, this distinction matters because a lower TTFT could come from noise, queueing, or sampling variance; a cached-prefix hit shows that the serving stack is actually reusing the expensive part of the prompt.
The separate 100k-token latency run adds an important caveat. GLM-5.2 produced the fastest individual first-token response in the dataset at 778 ms, which is directionally consistent with Baseten's published story that a tuned GLM-5.2 stack can be extremely fast. But the raw distribution also had a much heavier tail: across 300 GLM first-token measurements, 36 exceeded 10 seconds, 29 exceeded 17 seconds, and the maximum reached 25.9 seconds. Opus 4.8, by contrast, had one measurement above 10 seconds and none above 17 seconds in the same 300-measurement setup. The practical interpretation is not "GLM is slow"; it is that the fast path is real, while the shared serving path we exercised still showed cold-start, queueing, or capacity spikes that dominate p90/p95 latency.
Findings
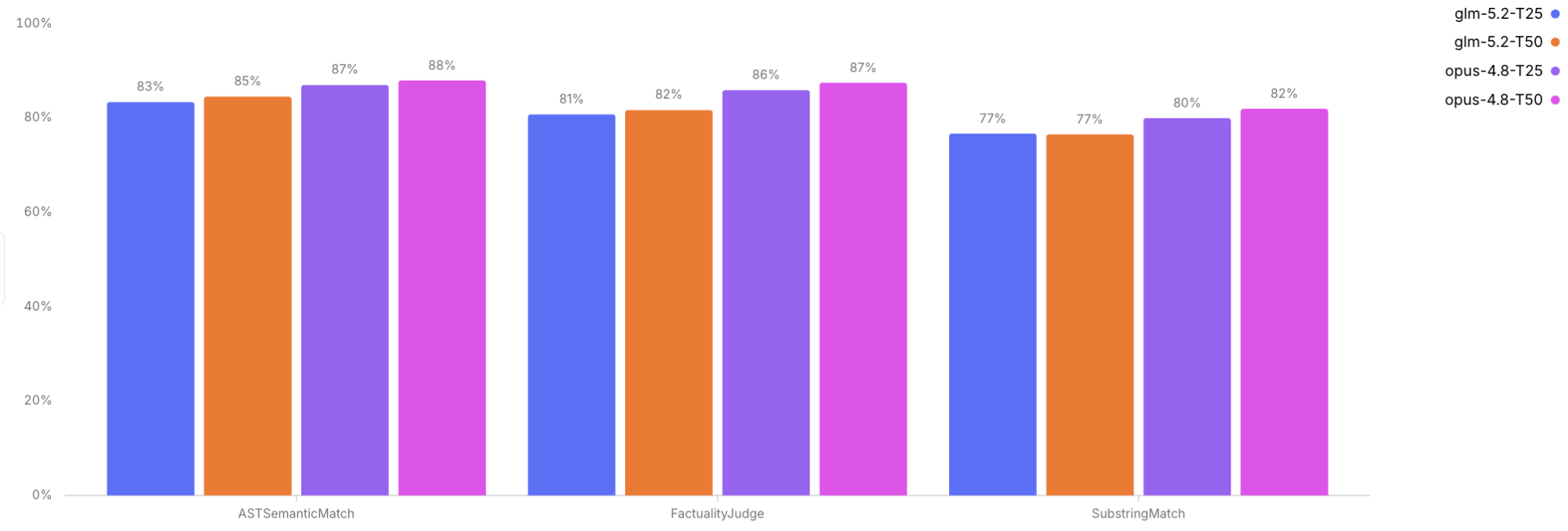
Across both context tiers, Opus 4.8 carves out a lead on GLM-5.2 on all three scoring views, but the margin is rather modest. The strongest signal is on ASTSemanticMatch, the primary deterministic scorer: Opus reaches 87% on T25 and 88% on T50, while GLM reaches 83% and 85%. SubstringMatch shows the same ordering but lower absolute values in this run, suggesting exact string containment is not a good substitute for the type-aware AST scorer.
Braintrust's built-in agent loop helps reveal that the cost picture is more asymmetric. Opus buys roughly 3 to 6 points of score improvement, depending on metric and tier, but at about 4x to 4.5x the average cost per trace. That makes the product question less like "which model wins?" and more like "how much marginal retrieval quality is worth the additional serving cost for this workflow?"
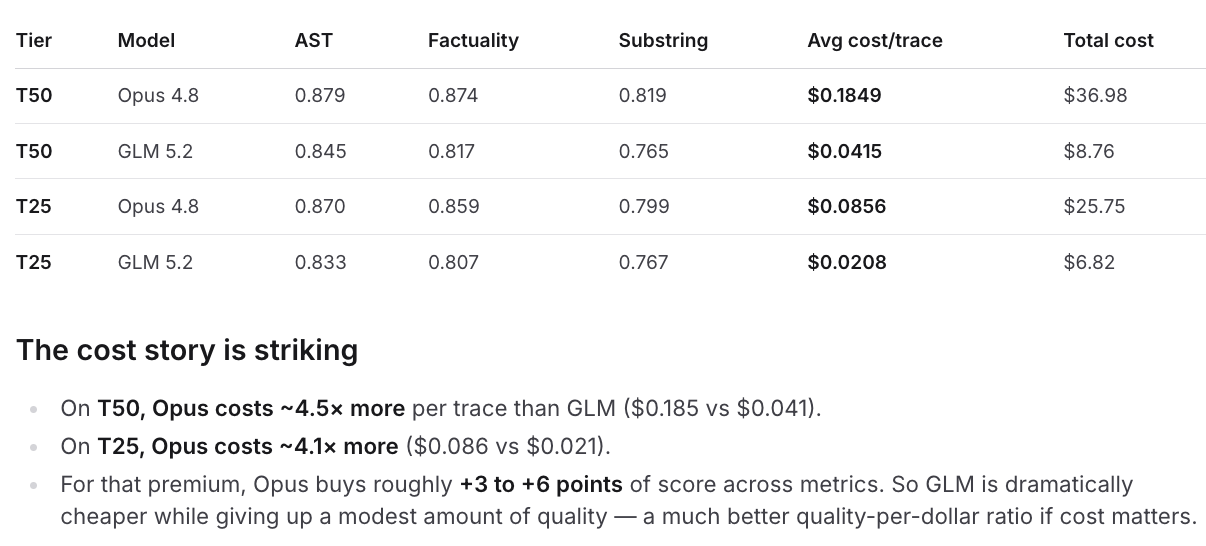
From the GLM-5.2 architecture lens, the key question is whether sparse attention preserves source-local retrieval fidelity as context grows. On this dataset, the answer is yes within the tested range: GLM's ASTSemanticMatch rate is effectively flat from T25 to T50, and Opus shows the same pattern. This does not prove the internal DeepSeek Sparse Attention mechanism is lossless, nor does it directly inspect which prior tokens the model selected. It does show no external retrieval degradation from 25k to 50k tokens on these source-local AST facts when GLM-5.2 is served through Baseten.
The position analysis gives a similar read. Failures are not simply a late-context problem: the lowest cells are not monotonically concentrated at the end of the prompt. The more plausible failure mode is local source disambiguation, especially when repeated method names appear across nearby classes.

Perturbation rows make that disambiguation problem visible. Both models land at the same perturbation accuracy overall, and the misses are concentrated on renamed symbols like clear_v2, pop_v2, remove_v2, and __sub___v2, where the model often retrieves the same method name from the wrong class or file region. That makes perturbations a useful anti-memorization control, but also a stress test for source-local symbol resolution.
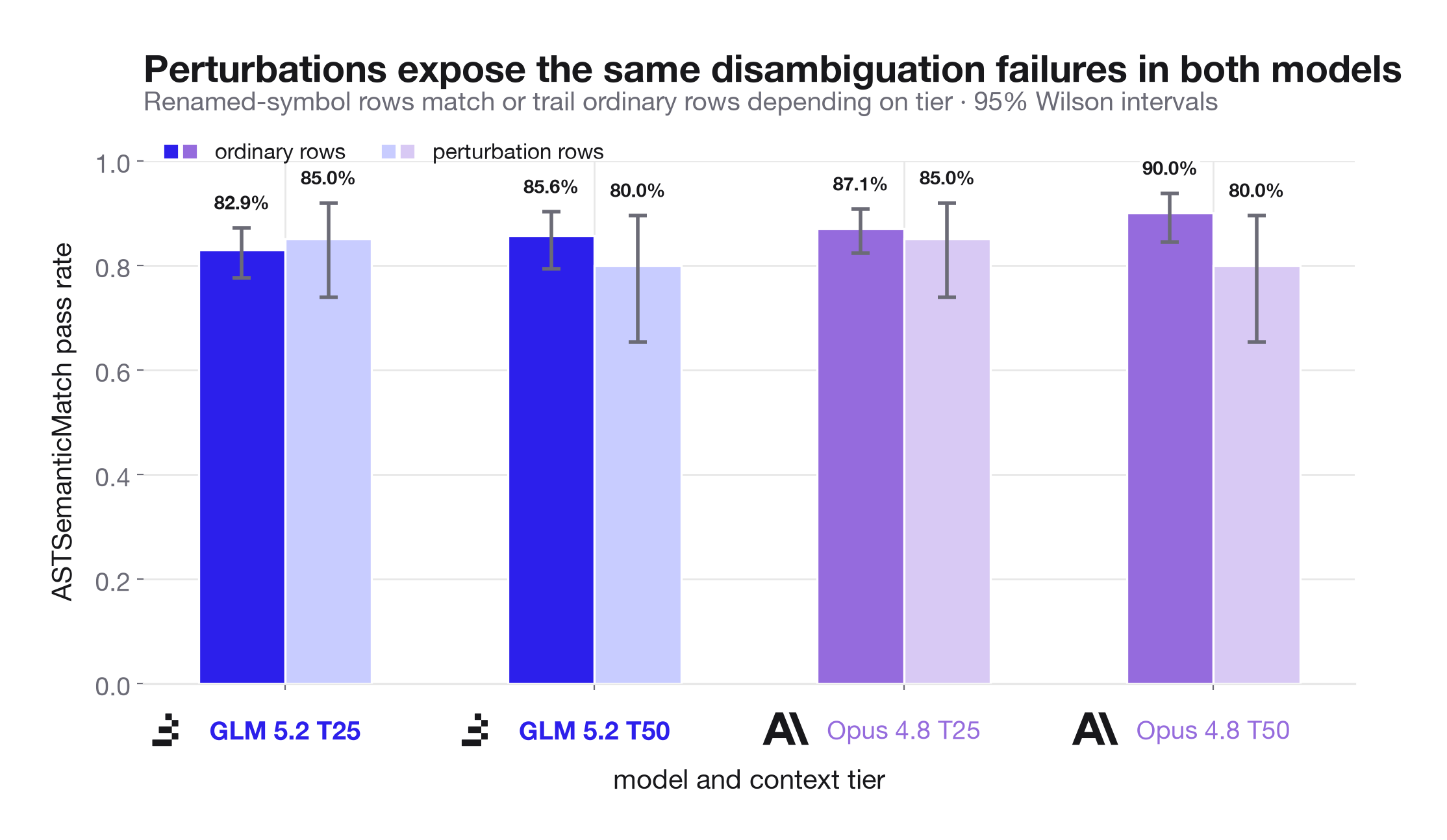
The cost side is more asymmetric. Using exact Braintrust provider token logs from the original experiments, GLM and Opus each answer 83 of 100 perturbation trial rows correctly, but GLM does so at about $0.046 per correct perturbation answer versus $0.324 for Opus. In other words, the perturbation control signal is roughly 7x cheaper on GLM in this run.
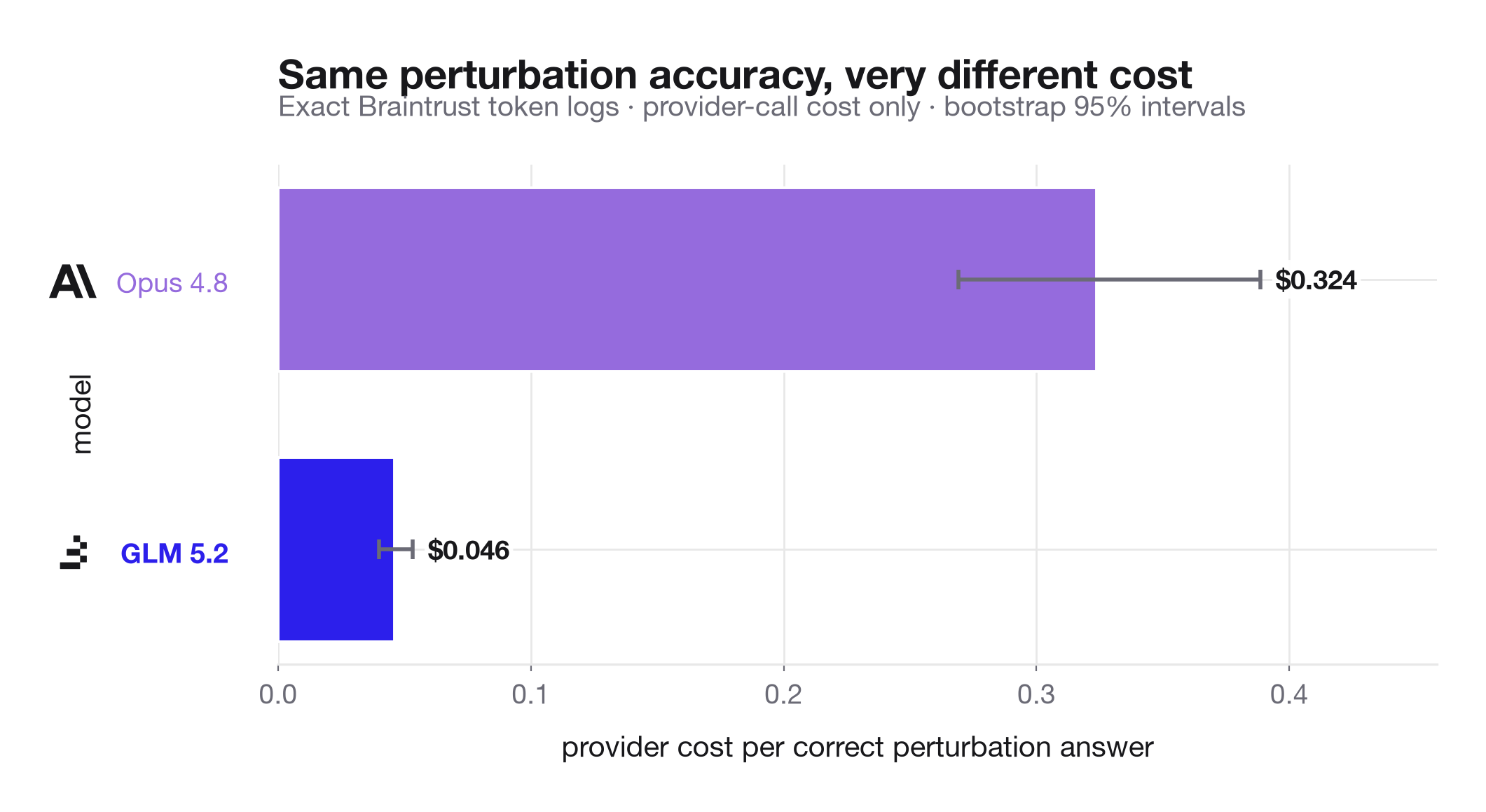
The most important serving-system detail is that perturbations are not cost-neutral. Because each perturbation mutates the context, it breaks some shared-prefix cache reuse. Ordinary rows show nearly complete prompt-cache reuse, while perturbation rows reduce the cached-token share, especially for Opus T50. That turns the perturbation slice into a useful serving stress test as well as an anti-memorization control: context mutations change the accuracy problem and the cache economics at the same time. GLM's architecture creates serving complexity through sparse, content-dependent KV access patterns, and Baseten is central to whether techniques like IndexCache-style index reuse, KV-aware routing, prefill/decode disaggregation, and speculative decoding turn the model's theoretical efficiency into usable product latency and cost.
Historical Anthropic baselines
We also compared newly run historical Anthropic baselines against GLM-5.2 on the same 25K and 50K datasets. Opus 4.6 and Sonnet 4.6 each ran three trials on T25 and two trials on T50; GLM-5.2 uses the existing T25/T50 scored rows with complete metrics.
GLM-5.2 remains the strongest exact-retrieval historical baseline in this comparison. The older Anthropic models are close on factuality and substring-style overlap, but they fall well behind GLM on ASTSemanticMatch, especially at 25K context. At 25K, Opus 4.6 is about 26.1 points behind GLM on ASTSemanticMatch, while Sonnet 4.6 is about 27.4 points behind. Their factuality scores are roughly flat to slightly ahead of GLM, but that does not offset the exact semantic retrieval gap. Opus 4.8 remains the highest-quality model overall, while GLM-5.2 separates clearly from the older Anthropic baselines.
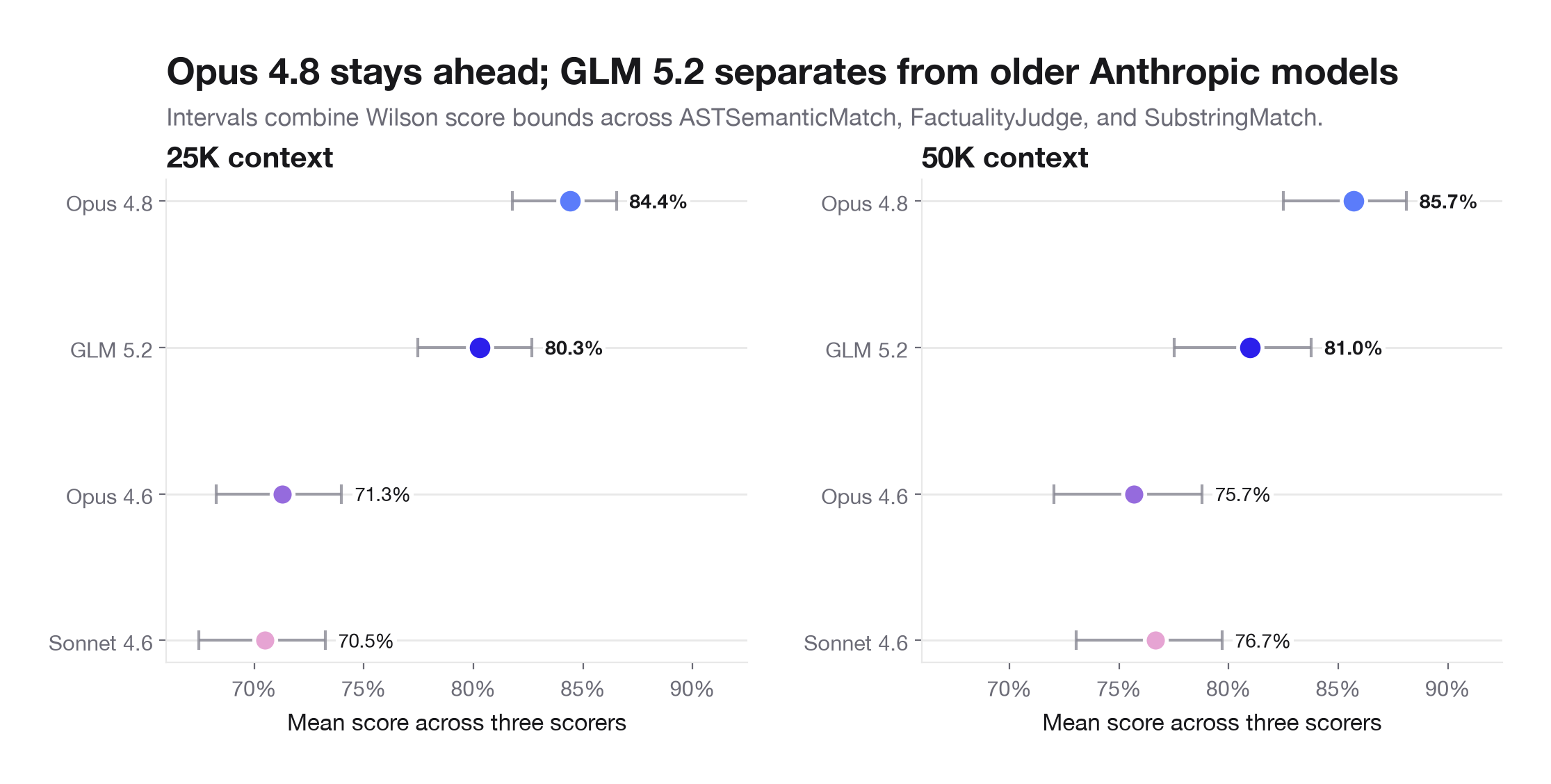
At 50K, the Anthropic models improve materially on ASTSemanticMatch but still trail GLM by about 17.6-17.8 points. Sonnet 4.6 is the more compelling historical Anthropic comparison at 50K: it roughly matches Opus 4.6 on AST, edges it on factuality and substring, runs faster, and costs less.
On cost and latency, GLM has the clearest quality-per-dollar position. Sonnet 4.6 narrows the latency gap and is cheaper than Opus 4.6, but it is still more expensive than GLM while scoring lower on the blended quality measure used in the tradeoff analysis.
The repeated-run uncertainty does not change the main conclusion. Using 95% Wilson intervals around the score rates, then combining those intervals conservatively for the three-metric mean, GLM's blended-quality interval remains above the older Anthropic intervals on both tiers:
| Tier | GLM-5.2 | Opus 4.6 | Sonnet 4.6 |
|---|---|---|---|
| 25K | 77.5-82.7% | 68.3-74.0% | 67.5-73.2% |
| 50K | 77.5-83.8% | 72.0-78.8% | 73.1-79.7% |
The robust part of the gap is ASTSemanticMatch. At 25K, GLM's AST interval is 78.8-87.2%, while Opus and Sonnet are about 51.7-62.8% and 50.3-61.5%. At 50K, GLM is 78.7-88.8%, while Opus and Sonnet are about 60.0-73.0%. Factuality is much less separable: the Anthropic models are slightly ahead on the point estimates, but the intervals overlap heavily with GLM. Sonnet vs. Opus is also mostly inside uncertainty on blended quality, especially at 50K; Sonnet's clearer advantage is operational, with lower cost and latency than Opus.
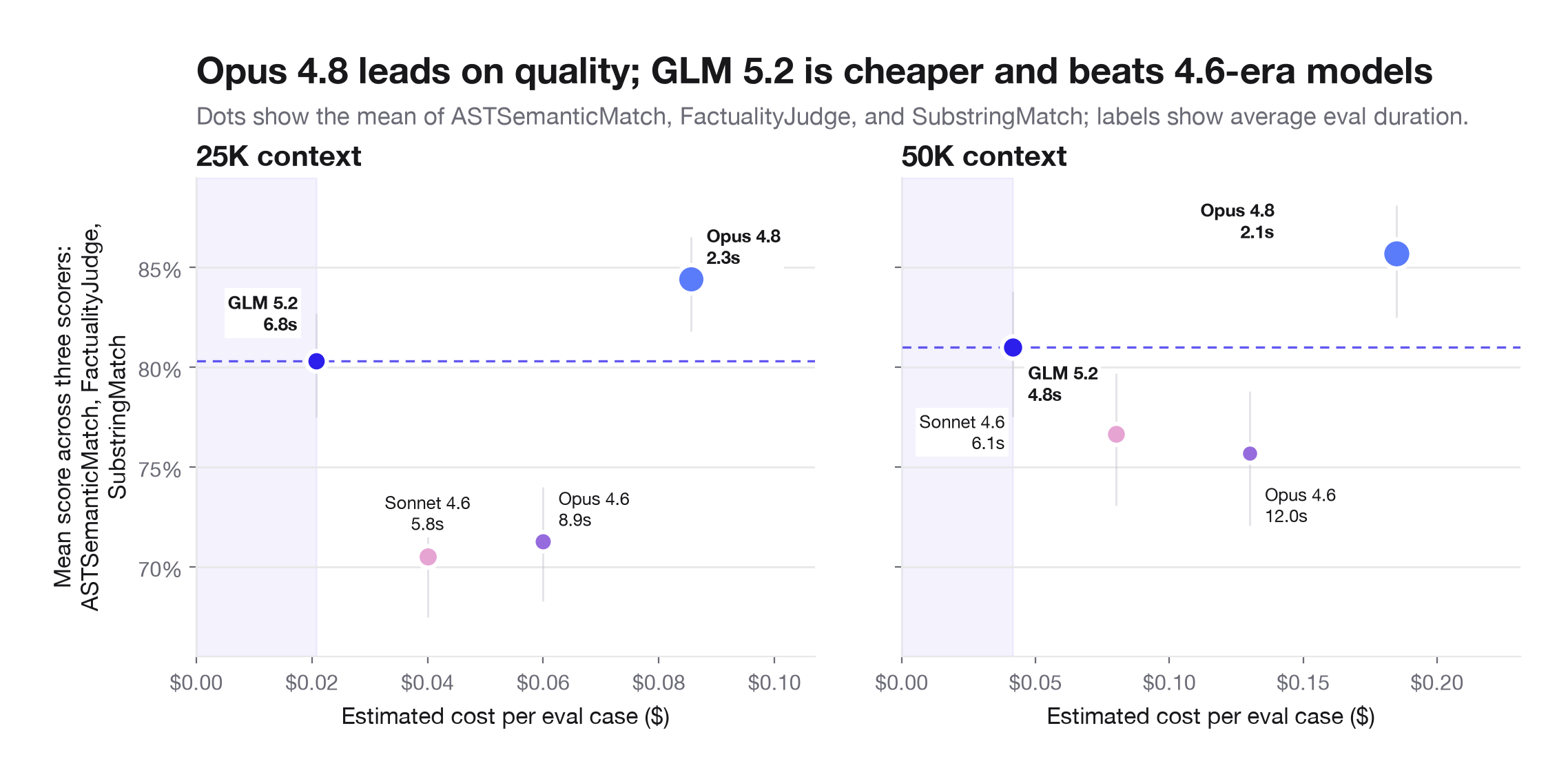
| Model | Tier | AST | Factuality | Substring | Mean quality | Cost | Duration |
|---|---|---|---|---|---|---|---|
| GLM-5.2 | 25K | 83.4% | 80.7% | 76.7% | 80.3% | $0.0208 | 6.78s |
| Opus 4.6 | 25K | 57.3% | 81.5% | 75.0% | 71.3% | $0.0600 | 8.87s |
| Sonnet 4.6 | 25K | 56.0% | 81.1% | 74.3% | 70.5% | $0.0400 | 5.76s |
| GLM-5.2 | 50K | 84.4% | 81.7% | 76.9% | 81.0% | $0.0415 | 4.80s |
| Opus 4.6 | 50K | 66.8% | 83.8% | 76.4% | 75.7% | $0.1300 | 12.04s |
| Sonnet 4.6 | 50K | 66.7% | 84.0% | 79.3% | 76.7% | $0.0800 | 6.07s |
Notes: T25 uses the 3x Anthropic runs (n=300) and T50 uses the 2x runs (n=200).
The practical read is that GLM-5.2 served through Baseten is competitive on exact long-context retrieval at substantially lower cost, while Opus 4.8 remains the higher-scoring and more latency-stable option in this run. The gap is small enough that application constraints matter: latency, budget, retry strategy, and tolerance for exact-retrieval misses may determine the better production choice more than headline accuracy alone. Baseten's public GLM-5.2 benchmarks and our fastest observed responses point in the same direction: the model can be very fast when the infrastructure is in the right regime. The remaining production question is tail control: how consistently can a real workload stay on that fast path? This eval reads as a focused test of the read side of GLM-5.2's agentic loop, not as a full test of long-output generation or end-to-end coding-agent performance.
Reliability note
The Baseten access tier for this experiment was Basic (unverified). GLM hit provider-side 429 Rate limit exceeded errors during high-concurrency runs. See Baseten's rate limits and budgets documentation for details on the tier structure.12 Our Anthropic organization had high-throughput custom limits for Claude models; Opus had one transient overloaded_error. For both providers, we retried only the specific failed row/trial cases via a checkpointed resume flow, and final runs ensured complete answering for each question in the dataset.
References
1 Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, et al. "RULER: What's the Real Context Size of Your Long-Context Language Models?" COLM 2024. https://arxiv.org/abs/2404.06654
2 Baseten. "How We Built the World's Fastest API for GLM-5.2." Baseten Blog, June 2026. https://www.baseten.co/blog/how-we-built-the-worlds-fastest-api-for-glm-52/
3 "IndexCache." arXiv, 2026. https://arxiv.org/abs/2603.12201
4 Baseten. "How We Built the Fastest GLM-5 API." Baseten Blog, March 2026. https://www.baseten.co/blog/how-we-built-the-fastest-glm-5-api/
5 Python ast module documentation. https://docs.python.org/3/library/ast.html
6 CPython Source Repository. https://github.com/python/cpython
7 Alex Gu, Baptiste Roziere, Hugh Leather, et al. (Meta). "CRUXEval: A Benchmark for Code Reasoning, Understanding and Execution." arXiv, 2024. https://arxiv.org/abs/2401.03065
8 Carlos E. Jimenez, John Yang, Alexander Wettig, et al. "SWE-bench: Can Language Models Resolve Real-World GitHub Issues?" ICLR 2024 Oral. https://arxiv.org/abs/2310.06770
9 Jiawei Liu, Jia Le Tian, Vijayaraghavan Murali, et al. "RepoQA: Evaluating Long Context Code Understanding." arXiv, 2024. https://arxiv.org/abs/2406.06025
10 Artificial Analysis. "GLM-5.2: Providers." Artificial Analysis. https://artificialanalysis.ai/models/glm-5-2/providers
11 Anthropic. "Prompt Caching." Anthropic API Documentation. https://docs.anthropic.com/en/docs/build-with-claude/prompt-caching
12 Baseten. "Rate Limits and Budgets." Baseten Documentation. https://docs.baseten.co/inference/model-apis/rate-limits-and-budgets
Trace everything
Create an account or use agent setup to start building today.