GPT-5 vs. Claude Opus 4.1
Two of the supposedly most capable large language models, OpenAI's GPT-5 (tested 2025-08-07) and Anthropic's Claude Opus 4.1 (2025-08-05), landed within days of each other this week. Both promise significant improvements in reasoning, comprehension, and adaptability, but deciding which to deploy isn’t straightforward. Benchmarks tell part of the story, customer feedback fills in more of the picture, and ultimately, the right choice depends on your workload and constraints.
We ran both models through one of the hardest academic benchmarks available, analyzed the results, and talked to customers already experimenting in production. Here’s what we found.
Want to see GPT-5 and Opus 4.1 in action for yourself? You can use the playground to compare different models and prompts side-by-side.
General breakdown
Claude Opus 4.1 is fast and efficient, making it well-suited for high-throughput tasks where speed matters. GPT-5 is slower and more expensive but consistently more accurate, especially on multi-step reasoning challenges. If your workload depends on wringing out every possible correct answer, GPT-5 is the stronger option. If you care more about responsiveness and cost, Claude may fit better.
Running HLE benchmarks
We used Humanity's Last Exam (HLE) — 2,500 PhD-level multiple-choice questions across math, physics, chemistry, linguistics, and engineering — to push both models to their limits. HLE is intentionally designed so that even frontier models struggle, making it a useful stress test. Let's break down the results by category:
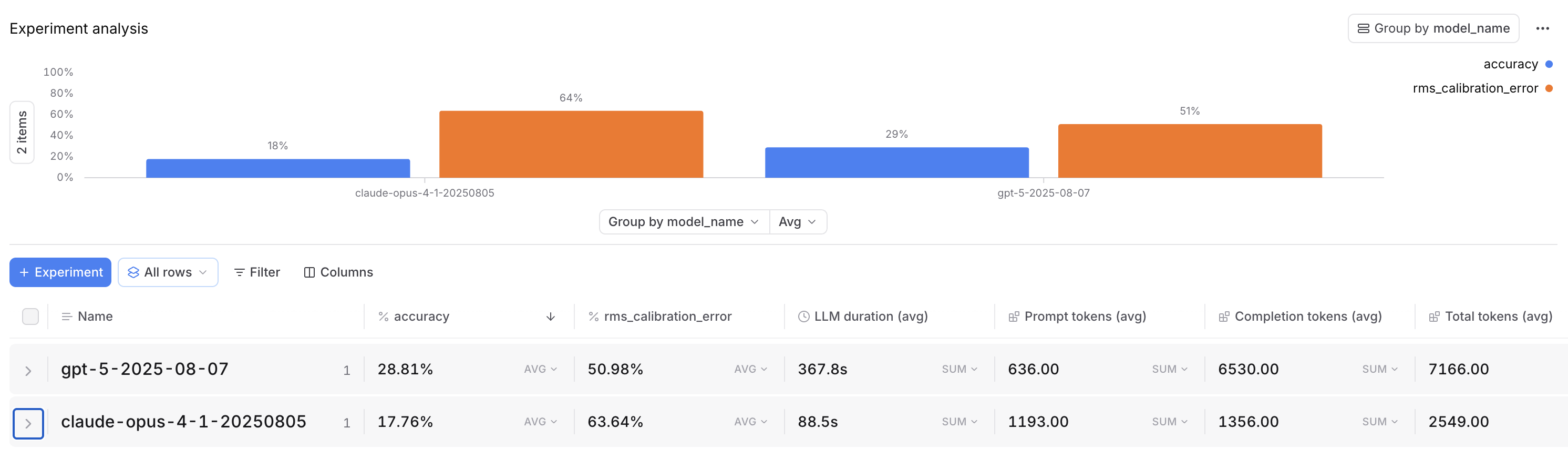
Accuracy: GPT-5 outperformed Claude by ~62%, with a 28.81% accuracy score compared to Claude's 17.76%. However, it's worth noting that random chance would get you a ~20% accuracy rate.
Calibration (self-awareness, or understanding what you don’t know): Both models were very overconfident when wrong, but GPT-5 was slightly more self-aware at 51.10%, while Claude came in at 63.64% (a lower percentage is better).
Efficiency tradeoff: GPT-5’s accuracy advantage comes at a large time and compute cost - it took 190 seconds per question and ~7,000 tokens, while Claude took only 88 seconds per question and ~2,500 tokens.
Reasoning effort
We also tested GPT-5 at different reasoning effort levels to determine how reasoning effort might impact accuracy, calibration, and efficiency:
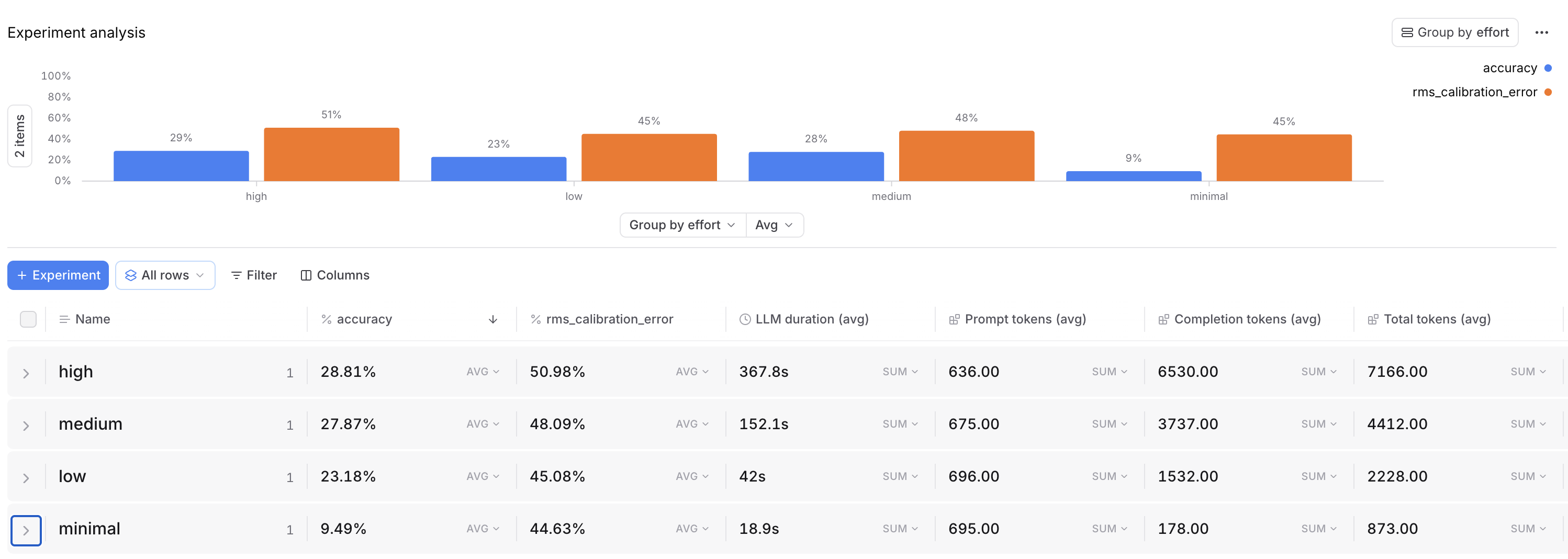
| Effort | Accuracy | RMS Calibration Error | LLM Duration (avg) | Total Tokens (avg) |
|---|---|---|---|---|
| High | 28.81% | 50.98% | 367.8s | 7166.00 |
| Medium | 27.87% | 48.09% | 152.1s | 4412.00 |
| Low | 23.18% | 45.08% | 42.0s | 2228.00 |
| Minimal | 9.49% | 44.63% | 18.9s | 873.00 |
We ultimately found that medium effort is the best balance for most production use cases.
How customers have been reacting to GPT-5
Early feedback from our customers on GPT-5 has been mixed. Some see it as a clear improvement over Claude on the hardest prompts, particularly for niche problem-solving like debugging tricky Spark SQL or identifying subtle shell script issues. Others feel it’s more of a “4.5” update than a full generational leap, especially for agentic use cases where it still requires multiple prompt iterations to deliver optimal results.
Speed has been a recurring point of discussion. GPT-5’s latency is noticeably higher than Claude’s, especially when reasoning effort is cranked up. It can also be finicky and pedantic, requiring prompt tuning to hit the right output style. For workloads where latency and cost dominate, customers often still prefer Claude.
How to know for sure which to deploy
Benchmarks like HLE are useful for comparing models under controlled conditions, but they don’t always reflect the nuances of your production environment. The best way to decide is to run your own evaluation that mirrors reality as closely as possible: real prompts, gold-standard answers, cost and latency tracking, and metrics that matter for your use case.
If your application depends on complex reasoning, broad world knowledge, or generating reliable code, start with GPT-5 at medium reasoning effort and run Claude as a challenger on the most critical steps. If your workload is dominated by long-document synthesis, policy enforcement, or editorial summarization, start with Claude and only bring in GPT-5 for tasks that require deeper reasoning or integrated code outputs.
With Braintrust, you can swap models in production with a single line of code, compare them side-by-side in the playground, and monitor their performance over time. That means you don’t have to commit to a single model blindly — you can run controlled tests in production, keep the winner, and continuously validate as models evolve.
In the end, the question isn’t just “which model is better?” It’s “which model is better for my workload, at my cost and latency targets, with my success metrics?”
Try Braintrust today to evaluate the models yourself.