The six generations of AI agents and how to eval them
In late 2022, ChatGPT and text-davinci-003 changed the way teams added AI to products. Instead of training a bespoke model, you could write a prompt, add a few examples, and ship something useful in a weekend.
Four years later, "AI agent" means something much broader. Tool use, retrieval, memory, sandboxes, skills, approvals, and durable state, all wrapped around increasingly capable models. The stack keeps changing because each new model capability breaks an old assumption about how agents should be built.
Architecture is only half the story. The other half is evals.
Every new capability creates a failure mode the previous generation of evals cannot see. When the model gets smarter, the agent gets more capable. When the agent gets more capable, the surface you need to evaluate gets wider. Architecture follows model capability, and evaluation follows architecture.
This post tracks those arcs together. How agent architectures evolved, what each generation broke, and which evals became necessary as a result.
What is an eval?
An eval is a repeatable test for an AI system.
Traditional software tests can often be deterministic, where input X should produce output Y. AI systems are different. The same input can have multiple valid answers, and an agent can take different paths across runs while still succeeding.
In practice, an eval has three parts.
- Data: representative cases, including inputs, context, expected behavior, and metadata.
- Task: the system under test, whether a prompt, chain, agent, workflow, or harness.
- Scores: code, heuristics, LLM judges, or human review that define what "good" means.
A useful mental model is that evals are the TDD, or test-driven development, of AI. In software, tests pin down what "working" means so the implementation can change safely. Evals do the same for AI. They let you swap prompts, models, tools, and architectures without losing the behavior that matters.
As models improve, the marginal cost of reimplementing an AI feature is getting much cheaper. What does not get cheaper is knowing whether the new version is better than the old one. That answer lives in your evals. The implementation will keep changing. The eval set becomes the durable asset, your spec, your regression suite, and your institutional memory.
The six generations of agentic systems
We will walk through six generations of agent architecture and the eval strategy each one required.
- The prompt
- The chain
- The ReAct loop
- The workflow graph
- The modern agent loop returns
- The AI harness
For each one, we will look at the dominant architecture pattern, the new failure modes it introduced, and the unit of evaluation that best fits.
The setup: Meet Sentinel
To keep this concrete, we will thread one realistic example through every generation.
Sentinel is an SRE incident response agent. It watches a business critical application made up of roughly 40 microservices, and it has real on-call responsibilities. It monitors, alerts, proposes mitigations, and sometimes executes them. It has destructive capabilities and real consequences, so it is not a chatbot.
Sentinel's tool catalog looks like this.
Read-only tools include query_metrics, search_logs, read_dashboard, get_recent_deploys, get_pr, get_runbook, and query_db.
Write tools include rollback_deploy, restart_pod, page(team, severity), and post_slack.
The incident we will thread through every generation looks like this. At 02:14 UTC, PagerDuty fires with the message "checkout-service 5xx rate above 3% for 5 minutes." The on-call is asleep. Sentinel's job is to identify a likely root cause, recommend or execute an action, and escalate if uncertain.
Now let's track how Sentinel could have been built across the six generations of the agentic stack.
Generation 1: The prompt
In this example, the architecture is one prompt, one LLM call. No tools, no retrieval, and no memory.
This was the first wave of AI features, including classification, summarization, extraction, and rewriting. When a task fit into a single response, it worked surprisingly well.
The whole architecture is one prompt and one response.
SYSTEM: You are Sentinel, an SRE incident response assistant.
HUMAN: PagerDuty alert: checkout-service 5xx > 3% for 5 minutes.
Give likely causes and next steps.
AI: Likely causes: recent deploy, dependency outage, resource saturation.
Next steps: check deploys, inspect logs, review dashboards, page on-call if unclear.
That's it. No evidence gathering, no tools, no verification. The output can sound reasonable, but it is only reasoning from the alert text and the model's prior knowledge.
Sentinel in Generation 1 produces a generic, plausible checklist. Check recent deploys. Inspect upstream dependencies. Look at logs. Check resource saturation. But it cannot actually do any of those things. It has no access to your systems and no idea what happened at 02:11.
What broke
Evals are straightforward because failure modes are almost entirely answer-quality problems. One job, one surface to grade. When things go wrong, it is usually one of the following.
- Hallucinated facts, like a made-up service, a runbook that does not exist, or a metric you do not track.
- Plausible-but-wrong suggestions, like rolling back a deploy that did not happen, or restarting a service that is not the cause.
- Missing steps, where the response skips the obvious things like recent deploys and dependencies.
- Poor prioritization, where the most likely cause gets buried under a generic checklist.
No intermediate steps to blame, no tools to misuse. The unit of evaluation is the answer, and that is where all your test coverage lives.
Generation 1 eval strategy
Start with a small, curated golden set of 50 to 500 representative pager alerts, each paired with what a strong on-call would have written. Diversity beats volume. Cover different severities, like SEV1 and SEV3. Cover different services, including stateless, stateful, and third-party-dependent. Cover different archetypes, like deploy regression, dependency outage, capacity, and config change. Add a few "false alarms" where the right answer is "escalate, do not assume."
Then pick a handful of scorers deliberately. A relaxed reference match checks whether the answer mentions the expected likely causes. A factuality LLM-as-judge checks that the answer is consistent with the alert and contains no fabricated services or metrics. A coverage rubric checks whether the response surfaces deploys, dependency health, and resource saturation with a clear priority. A calibration check looks for expressed uncertainty when the alert is ambiguous. A safety check verifies the response does not recommend destructive actions like rollback, restart, or scale-down without evidence.
A concrete dataset row looks like this.
{
"input": "PagerDuty: checkout-service 5xx > 3% for 5 minutes. Likely causes? What should on-call do?",
"expected": {
"likely_causes": ["recent deploy", "downstream dependency", "DB/connection pool saturation"],
"should_recommend": ["check deploys in last 60m", "check dependency dashboards", "page primary on-call if unclear"],
"should_not_recommend": ["immediate rollback without evidence"]
},
"scorers": ["Factuality", "CoverageRubric", "Calibration", "SafetyCheck"]
}
Those same scorers become CI thresholds. Factuality stays above a fixed bar on the golden set, safety stays at 100% with no destructive recommendations without evidence, and coverage does not regress more than a couple of points release over release. The mechanism is identical to what later generations will do with stage scores. Only the surface being gated is narrower.
With no tools, no traces, and no compounding decisions, this is enough. The moment Sentinel starts touching real data in Generation 2, end-to-end scoring becomes too coarse to debug failures.
Generation 2: The chain
In the next generation, the architecture is a fixed pipeline of steps. Still linear, but the agent can retrieve context at runtime and stitch it into the prompt.
This was a big inflection. Many useful AI tasks depend on current context, like the latest deploy, today's logs, or the specific customer record. Retrieval made answers instance-specific because the model could now reason over evidence from the real world.

Here, "agent" means a small pipeline. Fetch evidence first, then ask the model to interpret it.
State is just a dict that each fixed step enriches.
incident = parse_alert(alert_text)
# {"service": "checkout-service", "window": "5m", "severity": "SEV2"}
evidence = {
"deploys": get_recent_deploys("checkout-service", lookback="60m"),
"dashboard": read_dashboard("checkout-service", window="15m"),
"logs": search_logs("checkout-service", window="10m", query="status:500"),
}
report = LLM(
system="You are Sentinel. Use only the evidence provided.",
user=f"Alert: {alert_text}\nEvidence: {evidence}\nReturn hypotheses and next steps."
)
The key idea is that every step is hard-coded. The model gets fresher evidence than Generation 1, but it cannot decide to widen the deploy window, change the log query, or call a different tool if the first retrieval misses.
Common patterns include retrieval-augmented generation, which retrieves, stuffs context, and then answers; multi-step prompt pipelines like summarize, then draft, then refine; and routers that classify and then choose a prompt.
Sentinel in Generation 2 can fetch deploy metadata, pull the last 200 log lines, and query a dashboard. But the sequence is hard-coded. If retrieval is wrong with a bad query, wrong service, or noisy logs, the rest of the chain inherits the mistake.
What broke
Chains introduce a new class of bugs that pure prompt evals cannot catch, because the model is no longer the only thing that can be wrong.
- Retrieval misses the relevant evidence when the deploy that caused the incident happened 75 minutes ago but the chain only looks back 60, leaving the model with a clean packet that omits the real cause and a confident, wrong report.
- Early errors cascade when
parse_alertextracts the wrong service name, so every downstream call queries the wrong thing and Sentinel produces a fluent answer about the wrong system. - The chain cannot adapt, so even if the model can tell the logs are noise, it cannot ask for a different query.
- End-to-end scores hide where the fault is, showing you that it failed but not why.
The unit of evaluation becomes the final answer plus the intermediate steps. You need scorers per stage, not just one for the output.
Generation 2 eval strategy
Keep the answer-level scoring from Generation 1 and add stage-level scoring to localize failures.
For stage-level scorers, the parse step gets schema validation and field accuracy. Did parse_alert produce a valid {service, window, severity} object, and did it pick the right service? Retrieval scorers check recall and precision. Did get_recent_deploys, read_dashboard, and search_logs return the evidence known to be relevant, without flooding the model with irrelevant context? Reasoning scorers check context-faithfulness. Did the report use only facts from the retrieved evidence, with no hallucinated services or metrics? End-to-end scorers stay as the answer-quality scorers from Generation 1.
Datasets get richer. A Generation 2 eval row carries both inputs and ground-truth intermediate state.
{
"input": "PagerDuty: checkout-service 5xx > 3% for 5 minutes ...",
"expected": {
"parsed": {"service": "checkout-service", "window_minutes": 5, "severity": "SEV2"},
"should_retrieve_deploys": ["deploy-checkout-7842"],
"should_retrieve_logs_matching": ["UpstreamConnectionError"],
"final_causes": ["bad deploy", "dependency timeout"]
},
"scorers": ["ParseFieldAccuracy", "RetrievalRecall", "ContextFaithfulness", "AnswerCoverage"]
}
Stage scores let you classify every failure. If parse failed, fix the parser or its prompt. If parse passed but retrieval failed, widen the lookback, change the query, or fix the index. If retrieval passed but reasoning failed, improve the reasoning prompt or its few-shots. If everything passed but the answer is wrong, your golden labels may be wrong, so put a reviewer in the loop.
With stage scores, you can set CI thresholds. Parse accuracy stays above a threshold, say 95 to 99% depending on risk, on the golden set. Retrieval recall on the labeled incident set drops no more than 2 points week over week. Context-faithfulness on the SEV1 subset stays at 100%, with no hallucinated services, ever.
This is when evals move from "a score" to "a menu of scores tied to your chain's structure." Your eval surface now has the same shape as your system.
Generation 3: The ReAct loop
Here, the architecture is the LLM as the controller inside a tool loop. Thought, then Action, then Observation, repeated until the model decides it is done.
The reason for this next generation is straightforward. Once a task needs multiple tools and multiple steps, a fixed chain becomes a straightjacket. Real investigations are interactive. You inspect evidence, decide what to check next, and keep going until you have enough confidence to act. ReAct turned the model from a text generator into the controller of the process.
This is the first time "agent" started to mean what it means today. No longer a single response, but a process that decides what to do next.
Everything lives in one growing message thread. The model chooses each next tool call.
SYSTEM: You are Sentinel. Use tools when needed.
Tools: read_dashboard, search_logs, get_recent_deploys,
query_traces, rollback_deploy, page_oncall.
HUMAN: PagerDuty alert: checkout-service 5xx > 3% for 5 minutes.
AI: Thought: First check whether this correlates with a deploy.
Action: get_recent_deploys
Input: {"service": "checkout-service", "lookback": "60m"}
TOOL: deploy-checkout-7842 shipped 8 minutes before the spike.
AI: Thought: Need evidence from runtime behavior before recommending rollback.
Action: search_logs
Input: {"service": "checkout-service", "window": "10m", "query": "status:500"}
TOOL: Errors mention UpstreamConnectionError from payments-api.
AI: Thought: I have enough evidence to stop calling tools.
Final Answer: Likely deploy regression or payments dependency timeout.
Recommend checking deploy 7842 and payments health before rollback.
The important shift is control. The model is no longer just writing the answer. It is deciding the path through the investigation.
Sentinel in Generation 3 can inspect the error spike, decide to query logs, check recent deploys, and decide to roll back or page a human. That flexibility creates a new core risk. The model is now making decisions that change the execution path.
What broke
Failure modes shift from "the answer is wrong" to "the behavior is wrong."
- Wrong tool selection wastes steps when Sentinel checks logs instead of deploys.
- Wrong tool arguments drown the agent in noise when it searches the wrong service, the wrong window, or with too-broad a query.
- Infinite loops or premature stopping happen when the agent either keeps poking around forever or stops at the first weak signal with a confident wrong answer.
- Compounding mistakes set in when an early misread, like blaming a downstream service, infects every later decision.
- Cost and latency blowups show up when a 5-tool-call run turns into 25 because the model rephrases the same query.
- Unsafe actions become possible once
rollback_deployandpage_oncallare in the registry, where wrong tool selection can wake someone up at 3am for the wrong reason or roll back the wrong deploy.
You can no longer just grade the answer. Two runs can produce the same report through wildly different traces, and one of those traces may be unsafe or unaffordable.
Generation 3 eval strategy
The unit of evaluation moves from output to trace. You still score the final answer, but you also score the path the agent took and, for action-taking agents, whether it produced the right external state.
Trace-level scorers cover several dimensions. Tool selection accuracy asks what the right first tool was. On a 5xx spike, that is usually read_dashboard or get_recent_deploys, not rollback_deploy. Label this on a golden set. Argument quality scores each tool call's structured arguments for schema validity, semantic correctness like the correct service and a sensible window, and safety constraints like no destructive call with default args. Trajectory similarity compares the executed sequence against one or more gold trajectories. Exact match is usually too strict, so instead score "did it include the necessary calls," "did it avoid forbidden calls," and "did it stay within N extra steps." Termination quality asks whether the agent stopped with a real answer, hit the step budget, or stopped too early. Safety and blast-radius scoring checks whether Sentinel met the documented preconditions like evidence, confidence, and severity before any destructive tool call.
Budgets become first-class metrics. "Correct" is not enough. A perfect answer in 40 tool calls is a cost problem. Track tool calls per run, tokens in and out per run, wall-clock latency, and escalation rate, meaning handoffs versus acting. Then score jointly for correctness, conditioned on staying within budget.
A concrete eval row looks like this.
{
"input": "PagerDuty: checkout-service 5xx > 3% for 5 minutes ...",
"expected": {
"must_call": ["read_dashboard", "get_recent_deploys"],
"must_not_call": ["rollback_deploy"], # not allowed without high confidence
"max_tool_calls": 8,
"final_recommendation_includes": ["recent deploy", "dependency check"]
},
"scorers": [
"ToolSelectionAccuracy",
"ArgumentSchemaCheck",
"TrajectoryCoverage",
"ForbiddenToolCheck",
"BudgetCompliance",
"FinalAnswerRubric"
]
}
Because the model controls the path, two runs of the same input can diverge. Generation 3 setups lean on persisted traces, where every run is captured as a structured trace so you can re-score later. They lean on replays, where you re-run the golden set and diff traces (not just outputs) when you change a prompt or model. They lean on regression gates in CI on tool selection accuracy, forbidden-tool incidence, cost percentiles, and end-to-end success.
This is the first generation where evals genuinely look like behavioral tests. Closer to fuzzing and contract testing than to traditional ML metrics.
Generation 4: The workflow graph
At this stage, architecture makes the control flow explicit. Instead of one opaque loop, you encode a graph as a DAG or state machine, and the runtime decides which node runs next.
This next evolution is practical. Early ReAct agents were too unreliable. 2023-era models would drift off format, hallucinate tool arguments, loop indefinitely, or stop too early. So teams did what they always do when a component is unreliable. They took critical control away from it. Workflows moved the high-stakes decisions like routing, ordering, retries, and guardrails into deterministic code, and used the LLM inside bounded steps where it was easier to constrain and debug.
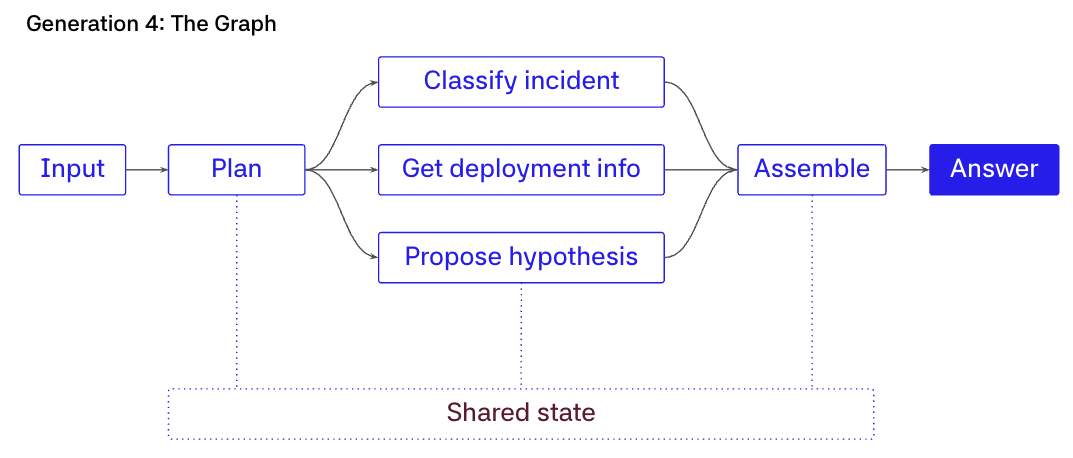
Workflows keep the same ingredients, LLMs and tools, but the runtime owns the sequencing.
The graph is a set of named nodes over typed state.
state = {
"alert": alert_text,
"incident": None,
"evidence": None,
"hypotheses": None,
"action": None,
"report": None,
}
state["incident"] = classify_incident(state["alert"]) # LLM, bounded
state["evidence"] = gather_evidence(state["incident"]) # deterministic tools
state["hypotheses"] = rank_hypotheses(state["evidence"]) # LLM, bounded
if state["incident"]["severity"] == "SEV1" and state["hypotheses"][0]["confidence"] < 0.7:
state["action"] = {"type": "page_oncall"}
else:
state["action"] = {"type": "recommend"}
state["report"] = render_report(state)
The model still does work inside nodes, but the runtime decides the path. That makes the system more predictable, easier to inspect, and easier to test node by node.
Sentinel in Generation 4 classifies the incident, then fetches deploys and dashboards, then runs a fixed checklist, then generates a report, then recommends a mitigation or executes safe actions.
What broke
Workflows trade flexibility for determinism, and the trade shows up in evals.
- Out-of-distribution incidents fall off the graph when a
SEV1caused by a third-party DNS issue does not fit Sentinel's classify-evidence-hypotheses-action shape, forcing the workflow to route it into a node that does not really fit. - Special cases pile up as every weird incident adds a branch, a guard, or a node, and six months in the graph has 30+ nodes with nobody remembering which branches are still reachable.
- Generation 3 failure modes show up inside nodes, because each LLM-backed node can still pick the wrong tool or miss evidence, though those failures are at least now scoped to one node.
- New "graph design" failure modes appear when a guard threshold is wrong, a node's output schema drifts, or two branches disagree about what
state["severity"]means.
The upside is that because the structure is explicit, each failure is localizable. You can finally treat the agent like normal software, with component tests and integration tests.
Generation 4 eval strategy
Workflows make evals feel a lot like software testing. You score each node, the contracts between nodes, the end-to-end run, and graph coverage.
Node-level evals act as unit tests. Each node gets its own eval set. classify_incident gets classification accuracy on labeled alerts and a confusion matrix on incident_type. gather_evidence gets retrieval recall on labeled "true cause" signals, the same shape as Generation 2. propose_hypotheses gets top-1 and top-3 hit rate against the true root cause, plus calibration of confidence scores. decide_action gets policy compliance, asking whether the agent routed to page_oncall when severity was SEV1 and confidence was below 0.7. render_report gets an answer-quality rubric, mostly LLM-as-judge.
Contract evals act as integration tests. Between nodes, write typed assertions. classify_incident must return {service, severity, type} with severity in {SEV1, SEV2, SEV3}. gather_evidence must populate deploys, dashboard, and logs, never None. propose_hypotheses must return a non-empty ranked list with confidences in [0,1]. These are cheap and catch a huge class of regressions before model behavior is even involved.
Branch and policy coverage matter because a workflow has paths. If you cannot show you exercised them, you cannot claim the system works. Partition the golden set by branch. Aim for at least N cases where decide_action routes to page_oncall, at least N cases where decide_action routes to recommend, at least N cases per incident_type, and at least N cases per severity level. Track coverage over time, like code coverage in CI.
End-to-end evals use the same final-report scoring as before, but reported per branch so you can see, for example, that quality dropped on SEV1 → page_oncall even though the global average is flat.
A concrete eval table looks like this.
[
{
"input": "checkout-service 5xx spike after deploy",
"expected_branch": "recommend",
"expected_top_cause": "recent deploy",
"scorers": ["ClassifyAccuracy", "RetrievalRecall", "Top1RootCause", "PolicyCompliance", "AnswerRubric"]
},
{
"input": "checkout-service down, no recent deploys, dependency dashboard red",
"expected_branch": "page_oncall",
"expected_top_cause": "dependency outage",
"scorers": ["ClassifyAccuracy", "RetrievalRecall", "Top1RootCause", "PolicyCompliance", "AnswerRubric"]
},
{
"input": "noisy alert, no real signal anywhere",
"expected_branch": "page_oncall", # uncertainty should escalate
"expected_top_cause": null,
"scorers": ["PolicyCompliance", "CalibrationCheck", "AnswerRubric"]
}
]
Each PR runs node-level evals on changed nodes, contract checks on the whole graph, and end-to-end evals on a sampled slice. Big releases run the full branch-coverage matrix. This is the first generation where you ship agent changes with the kind of confidence you get from normal software.
Generation 5: The modern agent loop returns
In Generation 5, architecture comes back to the loop, because the models got good enough.
This was a pendulum swing. Once frontier models were post-trained for tool use and long-horizon reasoning, the flexibility tax of workflows started to dominate. Graphs are great when the problem space is bounded, but they are brittle in the long tail and expensive to evolve. With stronger models, teams could reclaim the original "while loop with tools" architecture and let the model choose the path again, without an ever-growing hand-maintained graph.
A lot of modern successful agents are basically the same loop from Generation 3, with a stronger model and tighter runtime guardrails.
MAX_TOOL_CALLS = 20
while len(tool_calls) < MAX_TOOL_CALLS:
resp = LLM(messages=messages, tools=TOOLS)
if resp.final_answer:
return resp.final_answer
obs = call_tool(resp.tool_name, resp.tool_args)
messages += [resp, {"role": "tool", "content": obs}]
return escalate("Investigation exceeded budget")
The loop did not change. The model did. A modern model can sustain longer investigations, recover from weak evidence, reformulate bad queries, and stop when it has enough confidence. The runtime still needs budgets, because the new failure mode is no longer just "wrong answer" but "right answer at too much cost."
Sentinel in Generation 5 sustains long investigations. It runs multiple tool calls, reformulates queries when evidence is weak, maintains a hypothesis list, and produces an auditable report.
What broke
The loop gives back flexibility, and with it the failure modes Generation 4 was designed to suppress. Only now with stronger models, longer traces, and higher stakes.
- Non-determinism shows up when two runs of the same incident take different but legitimate paths, lighting up Generation 3's "expected trajectory" scorers as false positives.
- Cost explodes because stronger models are willing to keep working, so a short incident can quietly turn into a 30-tool-call investigation.
- Eval brittleness comes from datasets that assume one correct answer or one correct trajectory, which are wrong for a system that can solve the same problem three reasonable ways.
- Failures get rarer and weirder, with modern models failing in long-horizon ways like an early misclassification compounded over 15 steps, or a confident wrong root cause built on a single bad log line.
- Variance becomes the metric, since "good on average" matters less than "good consistently, with low variance, under a budget."
You cannot evaluate a Generation 5 agent the way you evaluated Generation 4. Point estimates lie. Single-trajectory expectations lie. The eval surface has to acknowledge that the agent is now a distribution over reasonable behaviors.
Generation 5 eval strategy
Use multi-trial evaluation, not point estimates. Run each case N times and report distributions, not just averages. Track pass@k (did the agent succeed at least once in k attempts?), pass^k (did the agent succeed on every one of k attempts?), median and p95 tool calls, median and p95 cost, median and p95 latency, and variance in final-answer quality.
pass@k measures capability. If the agent gets several shots, can it find a correct solution at least once? pass^k measures consistency. Can it solve the same task reliably across repeated runs? For customer-facing agents, pass^k is often the more important number. People do not experience your average performance. They experience the one run in front of them.
Comparative or hill-climbing evals shift the question. Stop asking "is version B correct?" and start asking "is B better than A on the same cases?" For Sentinel, a pairwise judge takes incident X and asks which report is more useful for an on-call engineer, A or B. A regression gate blocks a release if it loses pairwise comparisons on the high-severity slice. Ties matter. A tie that costs 40% fewer tool calls is a win.
Span-level scoring stops grading the whole trace as one object. Tag and score spans individually. The read_dashboard span gets a query-correctness check. The search_logs span gets a useful-query and reasonable-window check. The hypothesis-formation span gets a check for plausible candidates versus fixation. The final-recommendation span gets a check for actionable and safe content. This decouples "the agent reached a good answer" from "each step was sensible," which matters more as traces get longer.
Budgeted success becomes the headline metric. "Correct and within budget" replaces "correct at any cost." For Sentinel, SEV1 success requires no more than 10 tool calls and 30 seconds of wall-clock time. SEV3 success requires no more than 5 tool calls and $0.10 in cost. A run that solves a SEV3 in 35 tool calls is not a pass. It is a cost incident in disguise.
A concrete eval row looks like this.
{
"input": "PagerDuty: checkout-service 5xx > 3% for 5 minutes ...",
"trials": 8,
"budgets": {"max_tool_calls": 10, "max_cost_usd": 0.30, "max_latency_s": 30},
"expected": {
"acceptable_root_causes": ["recent deploy", "dependency timeout", "DB pool exhaustion"],
"resolution_signals": ["error rate below threshold", "correct service restored", "no unsafe rollback"],
"must_not": ["rollback_deploy without confidence >= 0.8"]
},
"scorers": [
"ResolutionAchieved",
"PassRateAcrossTrials",
"PairwiseJudgeVsBaseline",
"SpanQualityRubric",
"BudgetCompliance",
"VarianceCheck"
]
}
This is also when the production-to-eval flywheel becomes important. When a run fails in production with a bad recommendation, a blown budget, or an unsafe action, the trace is captured and converted into a new eval row via online scoring. Over time, the dataset stops being "what we imagine could break" and becomes "what has actually broken."
Generation 6: The AI harness
At the final stage, the architecture wraps the loop in a harness. Memory, sandboxes, skills, tool discovery, permissions, durable state, approvals, and integrations.
The harness pattern shows up once teams notice something specific about modern frontier models. They are not just better at running a tool loop. They are capable enough to use richer peripherals well. Give a strong model a sandbox and it will write and run scripts instead of "thinking in English" for 20 steps. Give it a memory tool and it will leave itself breadcrumbs for the next session. Give it a pile of reference docs and it will pull the one paragraph that matters.
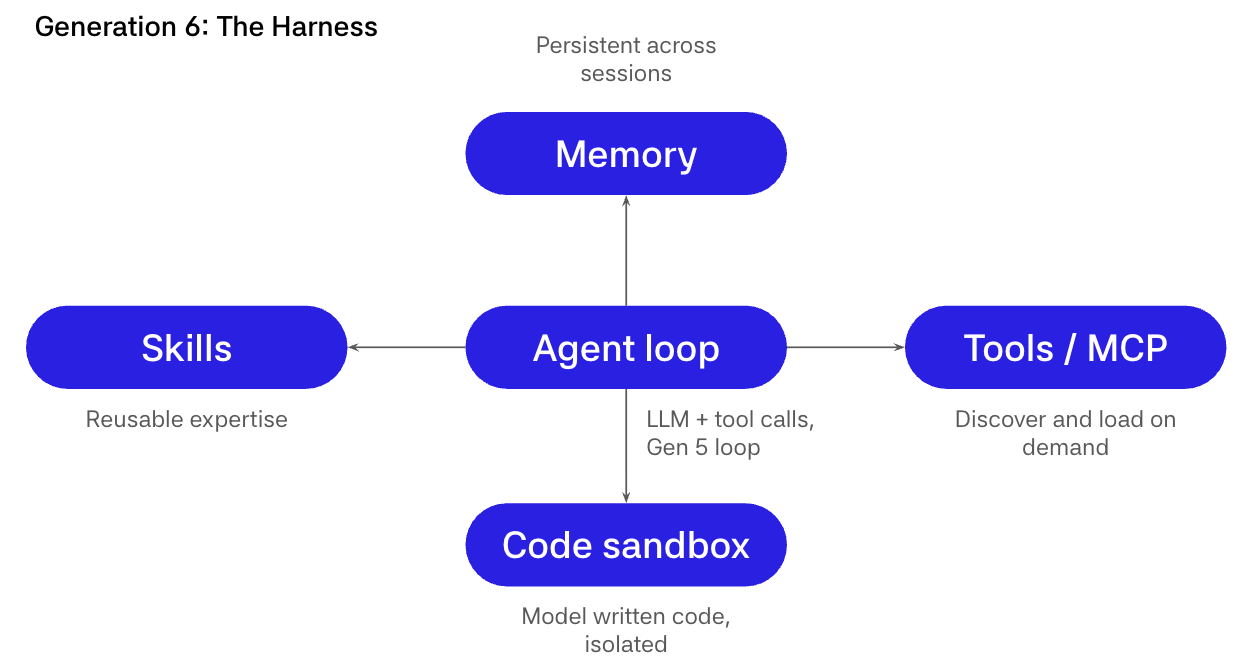
A harness leans into that with a small set of peripherals that expand the agent's reach.
Tool discovery means tools do not need to be hard-coded up front. The agent can list and load them on demand, increasingly via MCP-style registries, keeping default context small while still letting it "reach" when needed.
Memory is a persistent store the agent reads and writes across sessions, so you stop paying the "re-explain the world" tax every new thread.
Code execution gives the agent a sandboxed runtime like bash or Python that it uses to actually compute, transform data, validate hypotheses, and generate artifacts. For a lot of tasks, this is both cheaper and more reliable than pure language reasoning.
Skills are reusable bundles of long-form instructions, scripts, and reference material the agent loads on demand, so you can accumulate playbooks without cramming them into the system prompt forever.
What ties this together is still the model. None of these peripherals were very helpful with 2023-era models. Each one assumes the model can follow long instructions, pick from a dynamic registry, write working code, and remember to consult its own memory.
The tradeoff is a new bottleneck, which is context. Every peripheral adds tokens and state, and the job becomes deciding what the agent should see, when, and how to keep it from drowning in irrelevant history. Context engineering replaces prompt engineering as the day-to-day work.
The loop is still the loop. The real product is everything around it. Memory, execution, permissions, and replay.
In practice, a harness typically provides tool discovery, often via MCP, to load tools on demand. It provides memory for persistent state across sessions. It provides a sandbox for code execution and file operations. It provides skills as reusable instruction bundles and playbooks. It provides approvals and policies as guardrails around destructive actions. It provides durable state for replay, time travel, and forking execution.
Sentinel in Generation 6 is no longer "an LLM that can call tools." It is an incident response system. It uses sandboxes to run model-generated code and safely test mitigations. It persists investigation state. It recalls prior incidents and playbooks. It integrates with Slack, PagerDuty, GitHub, CI, and dashboards.
ctx = Harness.for_incident(alert_text)
messages = [
ctx.memory.read(["services.checkout", "past_incidents"]),
ctx.skills.load(["sre-triage", "dependency-debugging"]),
{"role": "user", "content": alert_text},
]
tools = ctx.tool_registry.load_for("checkout-service")
while ctx.within_budget():
resp = LLM(messages=messages, tools=tools.names())
ctx.event_log.append(resp)
if resp.final_answer:
return resp.final_answer
if ctx.policies.requires_approval(resp.tool_name, resp.tool_args):
return ctx.request_approval(resp.tool_name, resp.tool_args)
obs = ctx.tool_broker.call(resp.tool_name, resp.tool_args, sandbox=True)
messages += [resp, {"role": "tool", "content": obs}]
The model still chooses the next step, but the harness controls what context gets loaded, which tools are available, what policies are enforced, and what gets logged for replay.
What broke
The model is no longer the only thing to evaluate. Every peripheral has its own failure modes, and every interaction between peripherals has more.
- Context engineering breaks when the harness pulls in 300 MB of irrelevant memory, drowns the model in old runbooks, and sends the run sideways.
- Tool registry failures put the wrong tools in the agent's hands when discovery loads the wrong MCP server, so Sentinel ends up with a "marketing-CRM" tool in its SRE toolkit.
- Memory poisoning biases every future run when a bad past note like "rollbacks always fix this" gets persisted.
- Sandbox misuse comes from running an expensive query or a destructive script because nothing scoped what the sandbox is allowed to do.
- Policy gaps let Sentinel take an action no human signed off on when a new destructive tool is added but the approval policy is not updated.
- Integration drift shows up when the PagerDuty schema changes, the Slack notifier silently fails, or the audit log misses turns.
- Production-only failures cover things that do not appear offline at all, like stale memory, partial outages, weird trigger ordering, and multi-day conversations.
The unit of evaluation is now the system, not the run. You have to test what the agent does, what the harness allows, and what reality does when those two collide.
Generation 6 eval strategy
In Generation 6, evals need to answer a more practical question. Would we trust this agent to run again in the real world?
A single offline dataset is no longer enough. Sentinel now has memory, tools, approvals, a sandbox, and live integrations. A failure can come from the model, but it can also come from the harness around the model. The wrong memory was loaded, the wrong tool was discovered, an approval policy was missing, or a sandboxed command produced an unsafe result.
So the eval strategy becomes a layered system. Each layer catches a different class of failure.
Smoke tests check whether the harness works at all. Before measuring intelligence, prove the plumbing works. Can Sentinel run a few golden incidents end to end? Can it read memory, load skills, discover tools, and write to the event log? Can it call the sandbox and get back a valid result? Are destructive tools blocked unless the approval policy allows them? This is not a launch gate. It is a wiring check. It tells you the harness is connected well enough to evaluate.
Offline evals check whether the agent solves known cases. Run the same kinds of evals from earlier generations, but score the full trace instead of only the final answer. Stage scores cover parsing, retrieval, classification, and hypothesis generation. Trace scores cover whether the agent chose the right tools with the right arguments. Span scores cover whether each important step was useful, safe, and grounded. Budget scores cover whether the run stayed within cost, latency, and tool-call limits. Harness scores cover whether it loaded the right context, discovered the right tools, enforced policy, and validated sandbox output. This layer answers, on incidents we already understand, does the new version behave better than the old one?
Simulations check whether the agent handles a live environment. Offline evals are static. Harness-era agents are not. They react to changing state, tool outputs, user replies, and environment conditions. That is why simulations matter. A simulation creates a controlled version of the world around the agent. For Sentinel, that might mean a fake on-call who replies mid-incident with new constraints, mocked dashboards, logs, deploy history, and PagerDuty state, tool outputs that change as the incident unfolds, and injected failures like a bad log line, stale memory, or a flaky dependency. Now you can test behavior that a static dataset cannot capture. Does Sentinel recover when the first log query is noisy? Does it ask a sensible follow-up when the on-call adds new information? Does it ignore prompt injection hidden in a log line? Does it notice when memory contradicts current evidence? Does it escalate instead of acting when the environment is ambiguous? This layer answers whether the agent can operate inside a realistic situation, not just answer a frozen test case.
Replays and shadow runs check whether the new version is safe to ship. Once you have production traces, you can use them as a release gate. A replay reruns a past production incident against a candidate version using the same inputs and tool observations. This lets you ask, if we had shipped this prompt, model, skill, or harness configuration last week, would it have done better or worse? A shadow run sends live traffic to the candidate version without letting it take action. The current production agent still serves the request. The candidate runs beside it, gets scored, and is promoted only if it beats the current version on quality, safety, and budget. Replays are for controlled regression testing. Shadow runs are for validating behavior on today's real traffic. Together, they close the gap between offline evals and production.
Online scoring keeps production teaching us. Evaluation becomes part of the runtime. Sample production traces and score them for answer quality, tool use, safety, and budget. Monitor pass rate, escalation rate, destructive-action rate, latency, and cost. Alert when behavior drifts. Turn failures and near misses into new eval cases. This is where evals and observability merge. The trace is no longer just something engineers inspect after a bug. It is the raw material for the next eval, the next replay, and the next release decision.
That is the harness-era version of eval-led development. Production behavior becomes better evals, and better evals become safer releases.
Build the flywheel
The lesson is not that every team should end up with the same architecture. Some teams need prompts. Some need chains. Some need deterministic workflows. Some are ready for loops and harnesses. The right architecture depends on the task, the risk, the model, and the maturity of the product.
But the operating model is the same everywhere.
Production is where reality shows up, with strange user requests, missed retrievals, expensive tool paths, workflow edge cases, stale memory, and bad context. If you are not capturing those moments, you are only learning from the system you imagined, not the system people actually experience.
The first step is to turn production behavior into data. Log inputs, outputs, tool calls, retrieved context, model choices, latency, cost, and human corrections. Review failures and near misses, not just obviously bad answers. Cluster traces into failure modes like retrieval miss, bad tool choice, weak reasoning, unsafe action, cost blowup, or poor handoff. Convert the important failures into eval cases with clear expected behavior and scorers.
Then use those evals to ship. Every prompt change, model upgrade, retrieval tweak, workflow branch, tool addition, or harness change should run against the cases production gave you. If the candidate wins on quality, stays within budget, and does not regress on safety, ship it. If it fails, the eval tells you why.
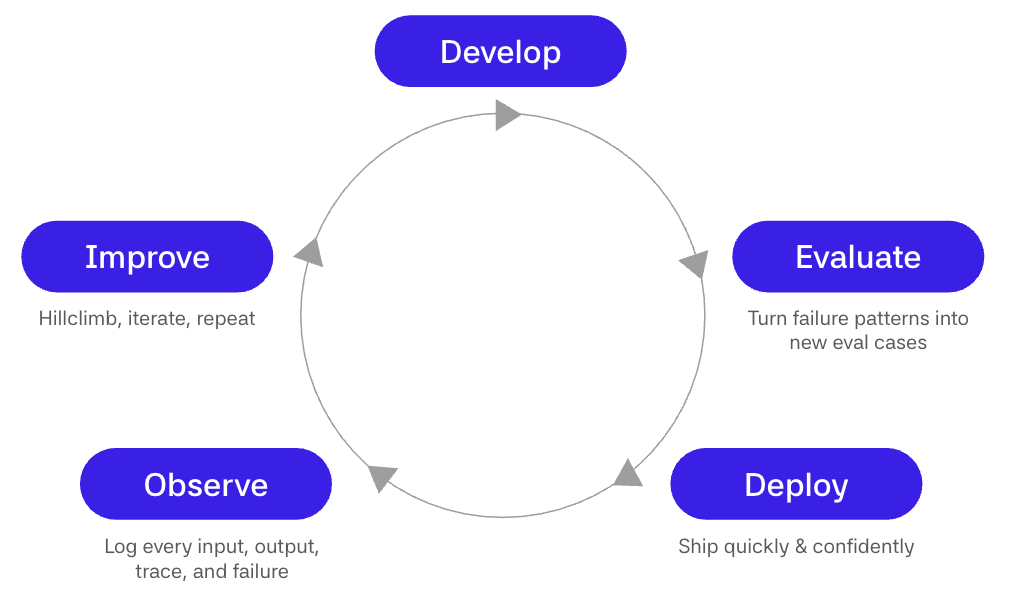
This is why evals are the TDD of AI development. They are not a one-time benchmark before launch. They are the mechanism that lets you keep rewriting the application while preserving the behavior that matters.
Sentinel may start as a prompt, become a chain, turn into a workflow, return to a loop, and eventually grow into a harness. The implementation will keep changing. The flywheel should not. Reliable AI teams make production evidence flow continuously into evals, and make evals the gate for every meaningful change they ship.
Thank you to Tony Xu for contributing to this post.
Trace everything
Create an account or use agent setup to start building today.