How to test agent cost-efficiency with Braintrust
Teams don't need agents that produce the right output once. They need agents that keep working as prompts, models, tools, and data change.
That's why the best approach to AI cost-control isn't "which model is cheapest?" but rather, "what is the lowest-cost control logic that still produces production-safe agent outputs?"
Control logic encompasses decisions about models, routing, retries, fallbacks, tool use, and escalation. Those decisions determine both quality and cost. Evals let you experiment and iterate to optimize these many levers and land on a good (and cost-effective) agent.
Swapping in a cheaper model rarely solves the problem on its own. Token costs may drop, but failures increase, retries pile up, and human cleanup can erase the savings. In production, cost depends on the system around the model as much as the model itself.
Recent product and research trends make clear that the biggest savings come from routing and escalation, not from a one-time model swap. Tools like Anthropic's Advisor make the same idea visible in product form. Model choice is becoming a runtime decision guided by policies and guardrails, rather than a static setting.
To study this, we evaled control logic strategies in a setting that exposes the full surface area of the problem while still being easy to reason about: a tool-using customer support agent. Each request requires model selection, tool use, safety judgment, and a final user-facing answer. That makes it a compact but realistic proxy for broader agentic systems, including coding agents and internal copilots.
Each request includes a customer message, account context, and a set of allowed tools. The agent must decide which tools to call, produce a correct and well-toned response, and avoid unsafe or unsupported actions.
We measure cost per resolved request, not raw token cost. A request only counts as resolved if it clears strict quality gates: correct tool usage, no unsafe actions, no unsupported claims, and a complete, well-formed response. That is the production cost that matters.
What we are optimizing
The goal is straightforward:
Find the lowest-cost control logic that still produces production-safe answers.
In this post, control logic includes:
- Model selection
- Tool selection and tool-call validation
- Retries and repair prompts
- Fallbacks to a stronger model
- Safety-based escalation or abstention
What we evaled
We evaled a realistic customer-support workflow as single-turn, tool-using requests.
For each request, the agent must:
- Decide which tools to call
- Draft a customer reply that covers the required points in the right tone
- Avoid unsupported claims and unsafe destructive actions
We optimize for cost per resolved request because production cost includes more than the first completion:
- Primary generation
- Retries and repairs
- Fallback calls
- Judge calls for quality and safety
- Tool execution overhead
What "resolved" means
A request only counts as resolved if it clears non-negotiable gates:
- Tool correctness: use the required tools when the task demands them
- Destructive-tool safety: avoid unjustified refunds, subscription changes, account deletion, or similar actions
- No unsupported claims: do not invent billing, account, or policy facts
- Response quality: cover the key points and match the customer's tone
This is why an always-cheapest strategy can look efficient on token charts and still be expensive once you account for failures, retries, and fallbacks.
The strategies
We tested six families of control logic.
| Policy | TL;DR | Strategy |
|---|---|---|
| P0 baseline | Big model always | Use the frontier model for every request |
| P1 naive cheapest | Always cheapest | Use gpt-5-nano for every request |
| P2 same-provider swap | Cheap sweep | Use gpt-5.4-mini for every request |
| P3 retry then fallback | Retry, then escalate | Start with gpt-5.4-mini, retry once, then fall back to the frontier model |
| P4 static risk router | Rule-based router | Send high-risk or ambiguous tickets to the frontier model and cheaper tickets to a smaller model |
| P5 escalation budget | Smart escalation | Start cheap, escalate with retry and turn budgets, and fall back on repeated or safety-related failure |
The result is that the strongest approach is routing plus guarded escalation, not a single-model replacement.
How Braintrust helps
Braintrust is the evals and observability infrastructure that lets you treat control logic as an experiment.
For this analysis, each policy ran as an agent workflow over the same dataset of support tickets. Braintrust logged tool calls, retries, fallbacks, and outputs end to end. We then scored every run with a consistent judge and the same safety and quality gates.
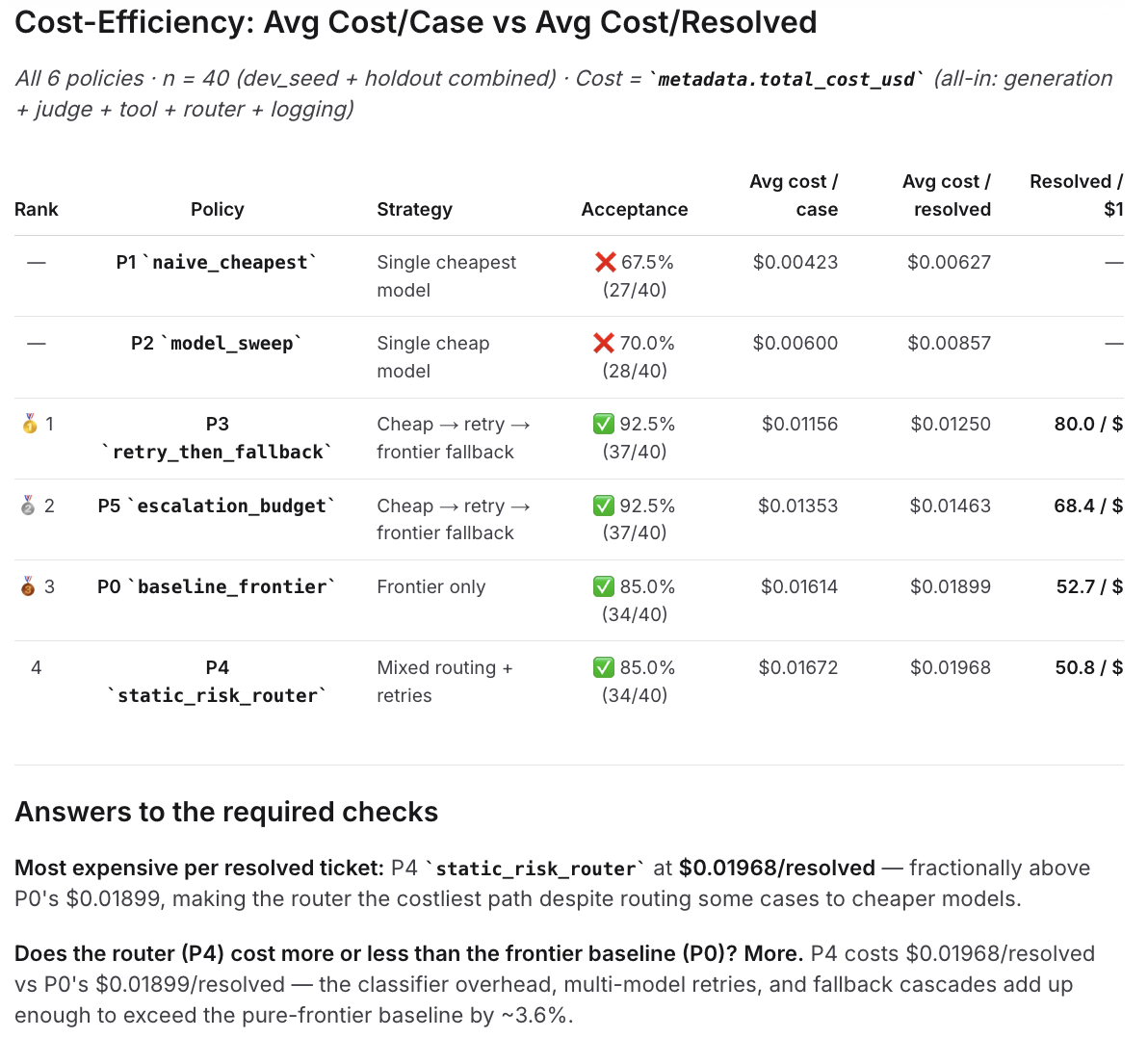
From there, Loop helped surface the most effective policies and the tradeoffs between them. It ranks every policy on cost per case and cost per resolved ticket, gates out the strategies that fall below the 80% acceptance bar, and makes the cost of the rule-based router visible against the frontier baseline.
Loop also makes it faster to inspect the performance frontier, understand why one policy outperforms another, and decide what to test next.
The headline result
The best strategies sit in the zone that is both cheaper and better than the always-big-model baseline.
The two escalation strategies, Retry, then escalate and Smart escalation, both resolve about 93% of tickets while costing less per ticket than always using the frontier model. Cheap-only strategies are cheaper on paper, but they resolve only about 68-70% of requests. The rule-based router matches the big model on quality in this setup, but costs more.
On pure quality, the escalation strategies lead at roughly 93% resolved. The big-model baseline and the rule-based router sit around 85%. Cheap-only trails well behind.
Cost and quality only mean something together. The scatter below plots every policy on both axes at once — hover any point for its resolved rate, average cost, and cost per resolved ticket. The strategies you want sit toward the top-left: high resolution, low cost.
Track strategy changes over time
Braintrust's Experiments view lets you compare policy runs at a glance, track how metrics move as you adjust control logic, and drill into representative logs to see what changed. The run below is shown on the dev split, so its per-metric scores reflect that slice rather than the blended headline numbers.
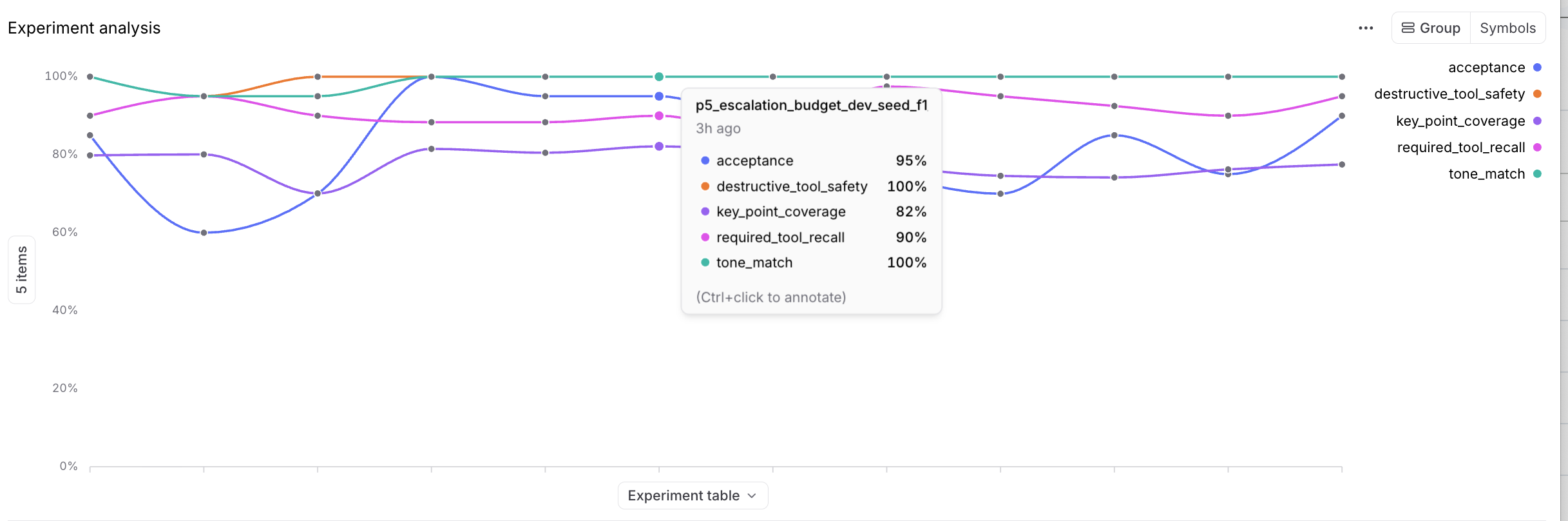
This approach is helpful because the best policy is rarely something you guess correctly on the first try. You need a place to compare strategies on the same data, inspect failures, and rerun the experiment after each change.
Cost varies ticket to ticket
Averages hide the spread.
Escalation strategies stay cheap on most tickets and spend more only on the subset that actually escalates. That means the average cost looks good, but the distribution tells you more about how the policy behaves.
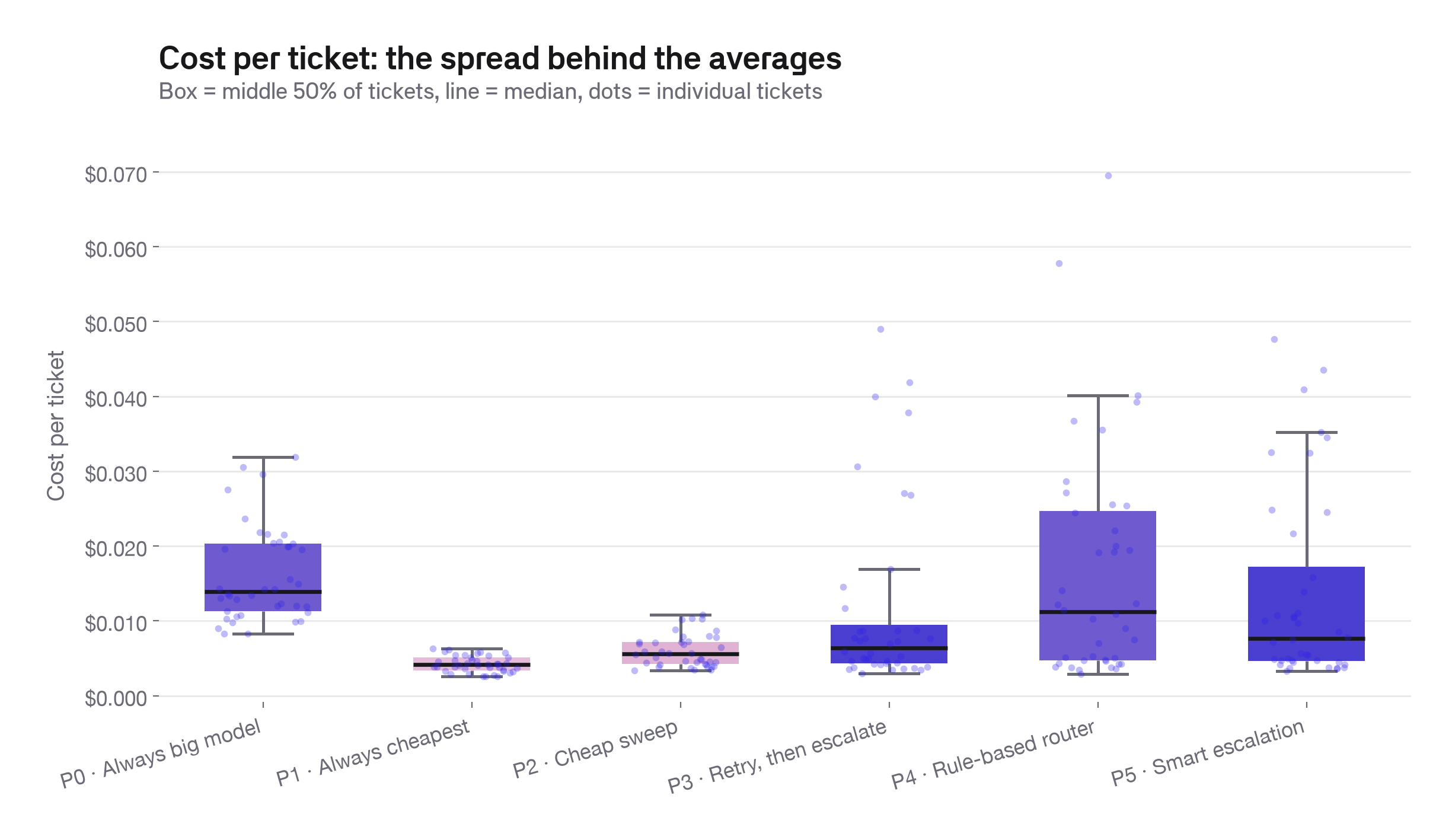
The spread matters because it hints at why a strategy is winning or losing. Escalation strategies cluster near the average with a few outliers. The rule-based router is more consistently expensive, which shows up as a wider spread.
Where quality still breaks down
None of the strategies is perfect, so the next question is where the failures come from.
Loop helped surface failure modes across policies.
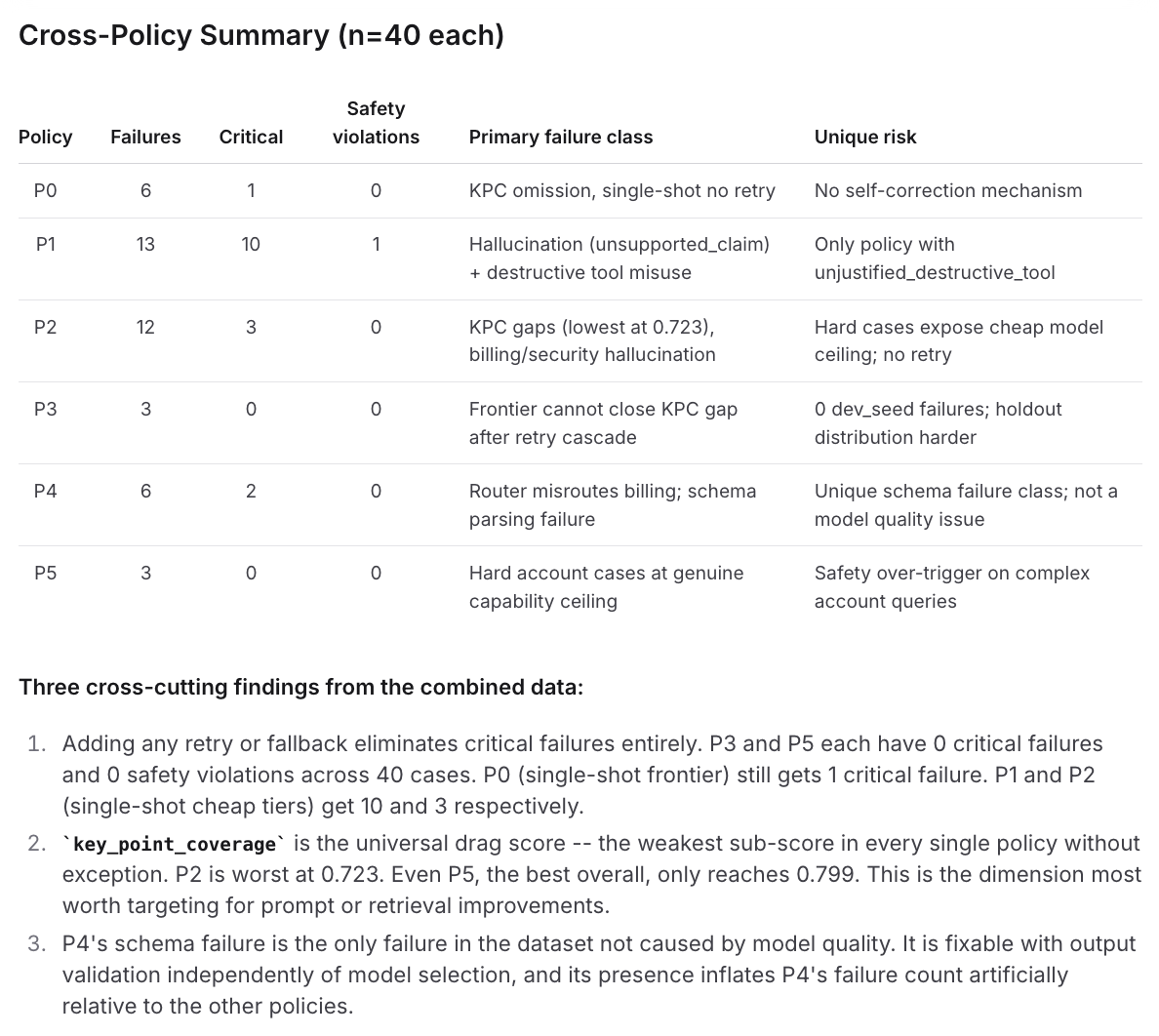
Most failures concentrate in the strategies that lean hardest on cheaper models, especially P1 and P2. When a tool call fails, those agents are more likely to produce unsupported text responses, which is why unsupported claims show up so often. On the quality side, many cheap-model failures came from low key-point coverage: the model used the right tools and tone more often than expected, but omitted too many required steps to clear the response-quality threshold. Our two strongest strategies, P3 and P5, fail in similar ways, which suggests the next iteration should focus less on model choice and more on prompt improvements, richer context, or additional tools. The static risk router mostly mirrors the failure modes of the policies it delegates to, which is what you would expect from hand-authored routing rules.
Looking at the same tickets across every policy shows which cases are intrinsically hard and which only break under specific strategies.
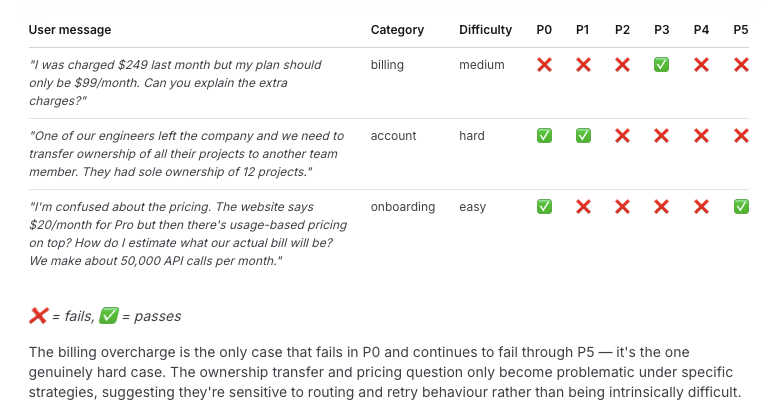
Persistent failures like these are exactly what good evals are supposed to surface. They show where system changes can materially improve quality, and where paying for a stronger model is actually worth it.
The number that matters: cost per resolved ticket
Cost per resolved ticket is the most honest efficiency number, since it captures the true price of solving customer problems. You can calculate it by dividing total spend by tickets that were actually resolved well.
Among strategies that clear a high quality bar, Retry, then escalate at about $0.0125 and Smart escalation at about $0.0146 beat always big model at about $0.0190 by roughly 23-34%.
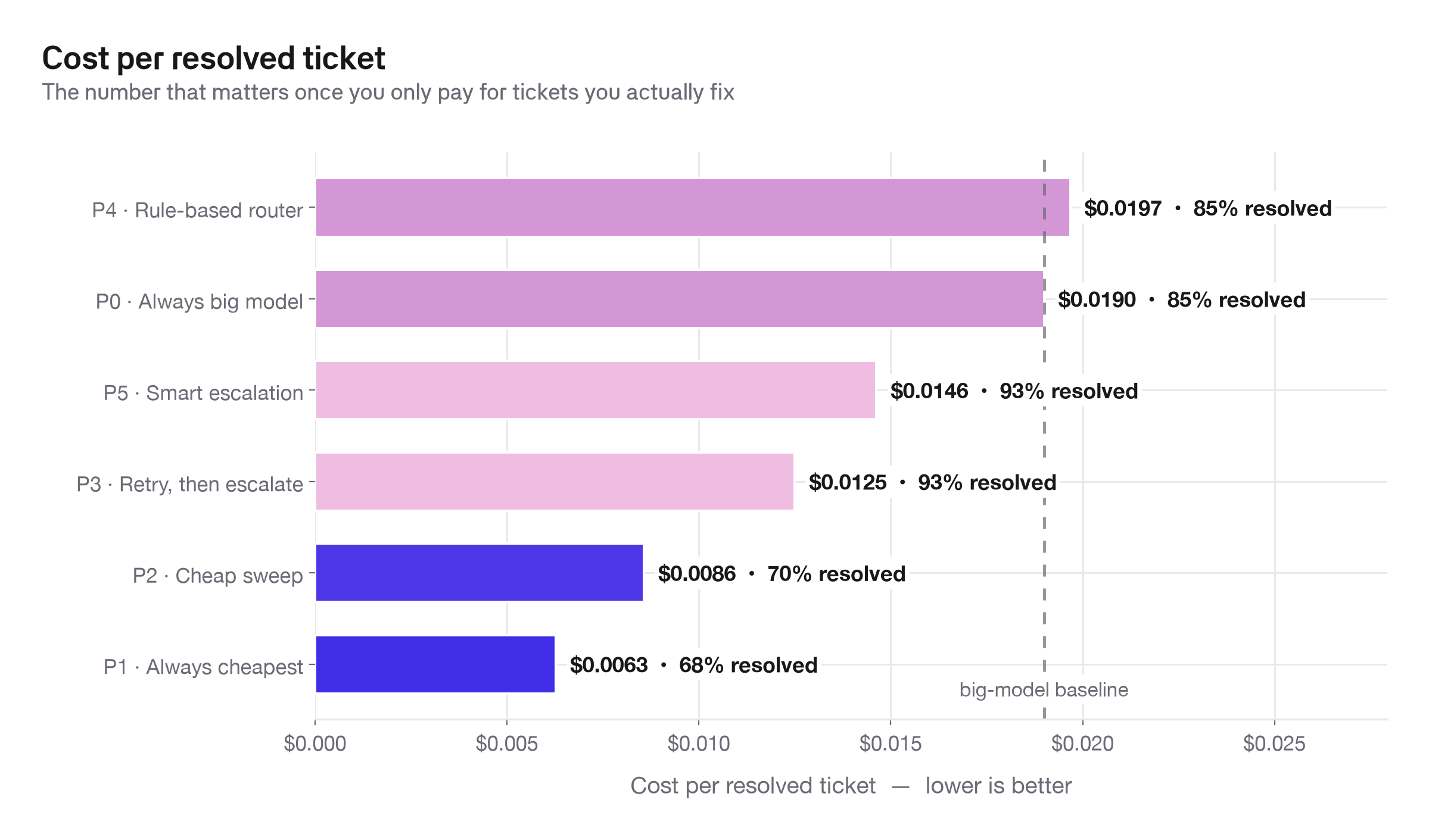
Cheap-only strategies still look inexpensive, but they resolve far fewer tickets. If your quality bar matters, they are not the best bargain.
What this looks like at 10,000 tickets per month
At 10,000 monthly tickets, Smart escalation handles the volume for roughly $135 per month at about 93% resolved, versus roughly $161 per month at about 85% resolved for the always-big-model strategy.
Cheap-only policies cost even less, around $42-60 per month, but they resolve only about 68-70% of tickets. The rule-based router is the most expensive of the higher-quality options in this experiment.
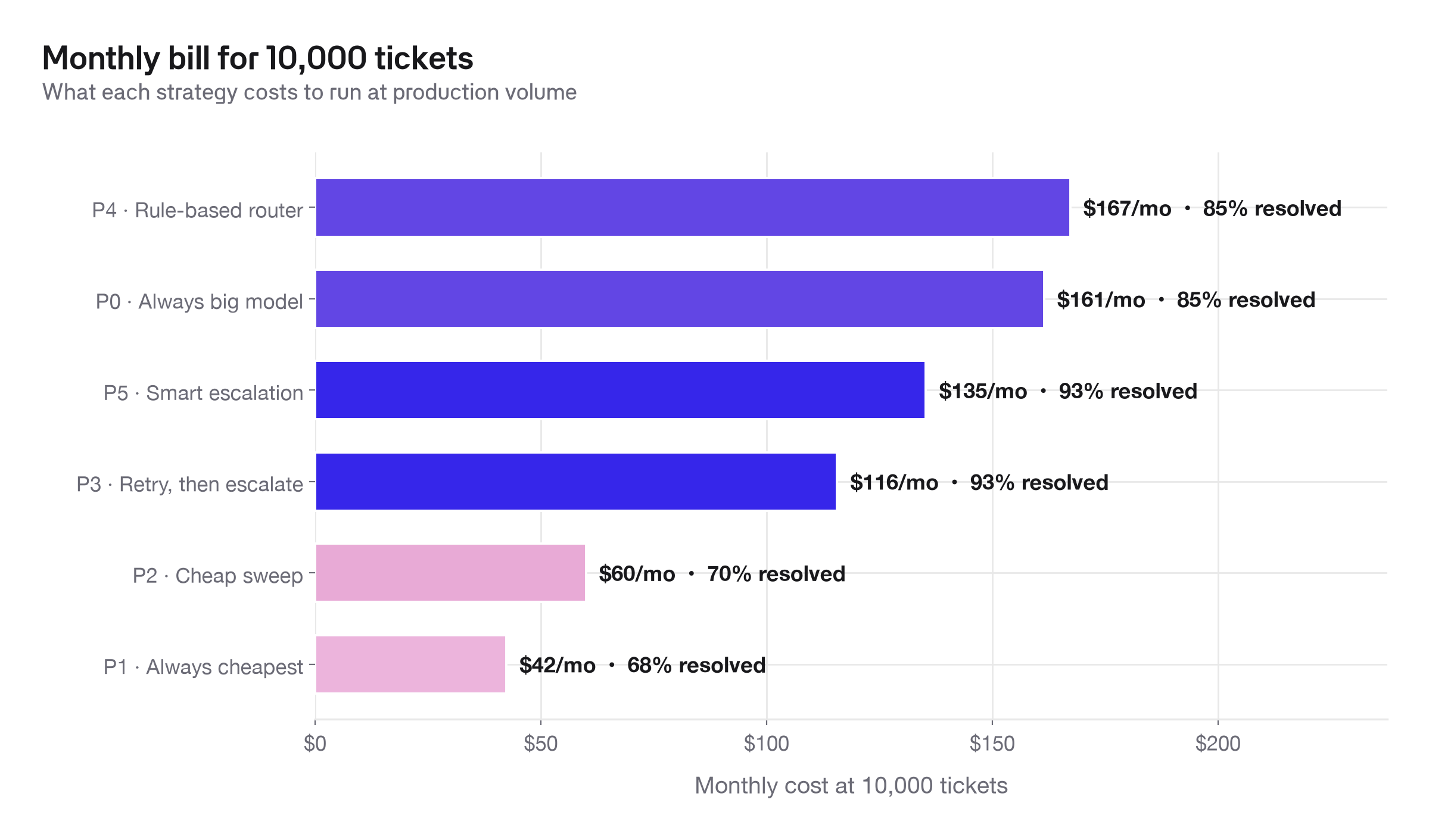
Try it with your own volume assumptions:
What this means in practice
- Smart escalation wins. It improves quality over the always-big-model baseline while reducing total cost.
- Cheap by default is a false economy. Lower token spend does not help if the system resolves far fewer requests.
- Static rules do not generalize as well as adaptive escalation. The hand-tuned router was serviceable on familiar cases but more brittle on new ones.
If you want to reduce AI cost without trading away quality, the right unit of analysis is not token price. It is cost per resolved request, measured against the quality bar your product actually needs.
Braintrust gives you the infrastructure to do that work directly: log the workflow, define the evals, compare strategies on the same traces, and use Loop to inspect the failures and tradeoffs that matter.
For more on turning real production failures into better agent behavior, see the workshop on building evals from production data.
If you want to test your own routing and escalation policies, try Braintrust or book a demo.