Trace keynote recap: See it, improve it, optimize it

A year ago, most teams were asking whether AI could work in production at all. Today, the focus has shifted to making AI work better, across every product and use case, without slowing down.
But AI has fundamentally changed observability, making this harder than ever. A trace is no longer a single request and response, but a multi-step agent with tools calling tools and attachments measured in gigabytes. What used to be a simple production app quickly generates an overwhelming volume of data.
The teams shipping fastest are the ones who can surface meaningful insights from that data and turn them into iteration and automation that continuously improves their systems. That requires a platform that supports the full loop: seeing what's happening, iterating to make improvements, and automating where possible.
That's the experience we're building in Braintrust, and it was the theme of Trace, our first user conference. Here's the full recap.
Scale and observability
If you've built an AI app, you know the feeling of deploying something you're confident is going to work, only to watch it regress when the prompts explode in scale and complexity. And the even worse feeling of watching it accelerate out of control while you're trying to diagnose the issue.
With Braintrust, teams can use semantic search to quickly identify issues. Traces load in real time regardless of scale or complexity. Annotation is effortless and flexible, so you can add whatever context you want. And aggregate charts let you keep tabs on system behavior over time.
All of these features are built on top of Brainstore, our purpose-built database for AI product development.
Brainstore
Brainstore combines massively scalable object storage with a high-throughput Rust-native streaming engine, backed by a built-in vector index and millisecond query performance. Because it was built specifically for AI, Brainstore has:
- 24x faster queries than legacy systems, so investigations stay interactive
- Full-text search in under 500ms compared to nearly 10 seconds on traditional platforms, so you can actively debug instead of losing context while you wait
- Near-real-time write latency, so your observability data keeps up with your system
- 3.7x faster span loading, so you can move through traces as quickly as you think, even at production scale
Brainstore also introduces new capabilities: SQL-first trace analytics with standard SQL including advanced operators like HAVING and PIVOT/UNPIVOT, near-real-time trace visibility with improved ingestion at high volume, and trace-level scoring and automations that run on full traces rather than single rows, enabling workflow-level quality assessment.
Braintrust enables teams to investigate problems faster, even across long conversations and multi-step agent runs, without sampling, truncation, or throwing data away.
Evals and iteration
Most teams agree that evals matter. But in practice, they are too manual, employ multiple tools, and are disconnected from real user data. When those tests stop reflecting reality, teams fall back on vibes and hope nothing breaks.
Teams should be iterating and improving their application, not figuring out how to spin up and maintain eval infrastructure. Braintrust makes your AI SDLC systematic and integrated.
Production traces become datasets at the click of a button, so evals can truly represent how users are interacting with your AI systems. Teams push those datasets into experiments, choose between default and custom scorers to define quality, and iterate from there. Evals run automatically in CI/CD, catching regressions before production.
Reducing friction at every step of evaluation means teams spend less time maintaining and more time creating meaningful improvement.
Braintrust CLI
We heard our customers loud and clear: they want the magic of the Braintrust UI brought directly to their coding agents. That's why we're introducing the Braintrust CLI.
Historically, you could run experiments via the SDK or the UI. Now you can do all of that from the terminal.
The CLI is designed to be agent-first. It's built for real agent workflows, not one-off scripts. And it's comprehensive: it lets you do essentially everything you can do in the UI, including prompts, scorers, tools, datasets, experiments, logs, and SQL. Read the docs to get started.
Optimization
Observability tells you what happened. Evals tell you whether it's getting better. But connecting the two reliably, repeatedly, and at scale is still manual. That's why Braintrust is building proactive insights and optimizations into our platform to both discover issues and implement fixes automatically.
Topics
When you're looking at thousands of traces, insights and errors are buried deep inside. Surfacing them used to require teams of people manually reading logs.
Topics, available in beta today, summarizes each trace into a simple statement, then clusters them into categories: recurring issues, common tasks, shifts in sentiment. Not a sea of logs that are sparsely reviewed or annotated.
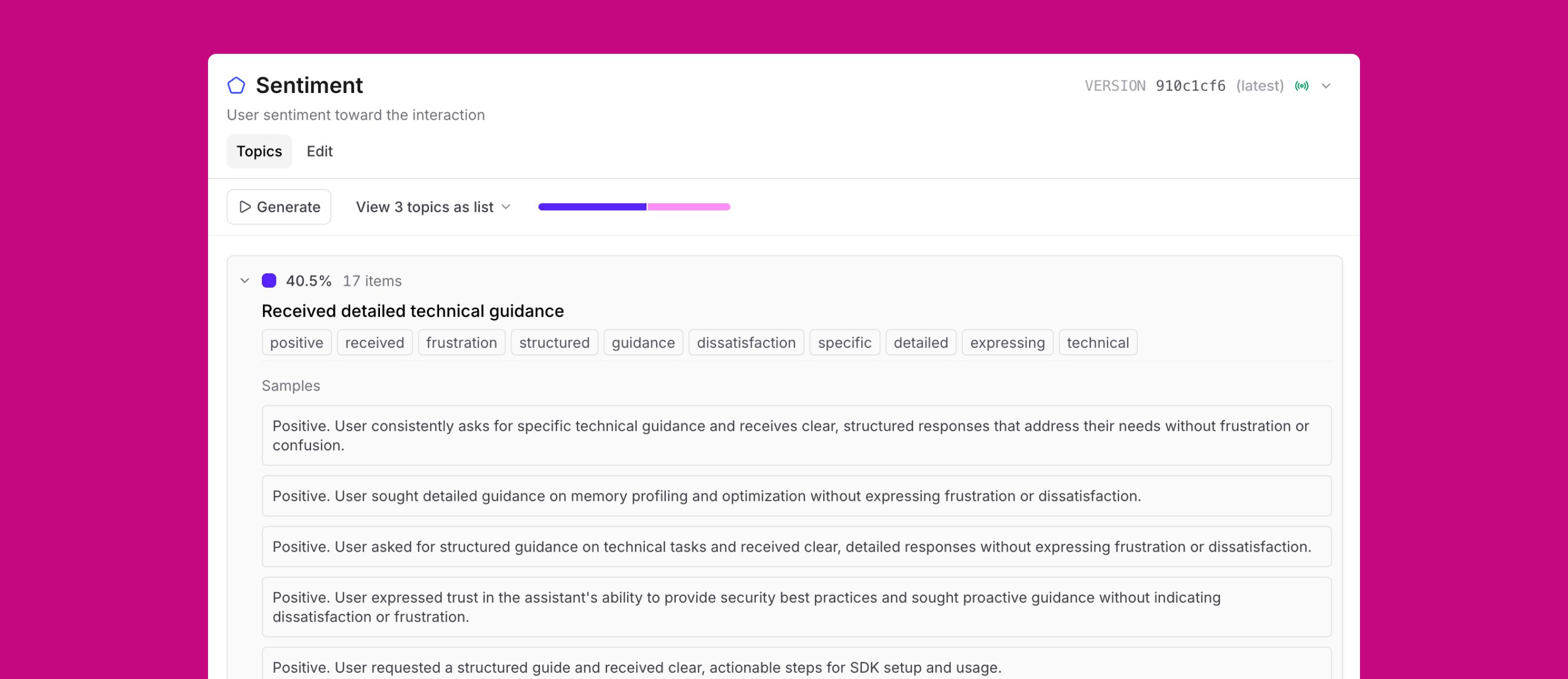
Because Topics is built directly into Braintrust, those patterns are not static reports. They become inputs to your evals, new datasets, and new quality gates. Topics runs automatically on new logs as they come in, so your classifications stay current. And uncategorized traces can be just as insightful, helping you proactively discover new use cases in real time.
Topics uses embeddings for clustering, cheap models for summarization, and Brainstore as a vector database. Read the blog post for details on how it works, or check out the docs to get started.
Loop
Once you have Topics surfacing patterns, Loop is how you act on them. Feed a topic into Loop and ask it to iterate on the prompt, test new models, or optimize around a specific failure mode. Instead of manually triaging and rewriting prompts, you're improving against real production patterns.
Over the last year, we've heard the same thing from many of you: there's plenty of data but no clear path from "this looks wrong" to "this is what we should change." Loop connects observability and evals into a single workflow, using production data as the starting point and preserving context as you investigate issues and make changes.
Together, Topics and Loop help teams:
- Identify failure mode patterns early
- Convert production patterns into eval coverage automatically
- Improve agents continuously as real usage evolves
Humans stay responsible for defining what "good" means and for making the final call on changes. Loop handles the manual work of keeping datasets current, running evals as behavior changes, and surfacing where quality is drifting.
Gateway
We initially built an AI proxy to power playgrounds and route requests across providers without hand-writing model-specific code. Along the way, we realized customers had the same problem in production, where governance is critical: a single key, rate limits, cost controls, and consistent observability across models.
The Braintrust Gateway, also launching in beta, standardizes access and observability across models and providers, and all of your gateway requests will automatically be traced in Braintrust. If you're using an existing gateway like Cloudflare or Vercel, your setup doesn't change. More enterprise features like deeper cost controls and rate limiting are coming next. Read the docs to learn more.
Iteration is everything
Everybody has access to the same models the moment they come out. What matters is how fast you can iterate: see what your system did, measure it, improve it, validate it again, and increasingly, automate the parts that don't require human judgment.
That's what Braintrust is building. That's what will help you ship quality AI products.