Playgrounds in Braintrust enable A/B testing by allowing you to compare multiple prompt variants side-by-side. Run different prompt versions, models, or parameters simultaneously, while Braintrust tracks quality scores, latency, cost, and token usage for each variant.
When to A/B test prompts
A/B testing helps you verify prompt improvements with real quality scores before deployment. Use A/B testing when you are:
- Iterating on prompts and need to catch regressions before users do
- Comparing performance across different models (GPT-4o, Claude, Gemini)
- Evaluating changes systematically against test datasets
The fundamental challenge with prompt development is that changes have unpredictable effects. Adding an example might improve one scenario while breaking another. A/B testing transforms this guesswork into measurable comparison.
Setup
Braintrust supports A/B testing prompts both natively in the web interface and with code via the SDK. For product managers and non-technical users, playgrounds in the web app provide a visual way to experiment with prompts, models, and scorers to see how changes affect key metrics. Engineers can create notebooks or scripts to A/B test prompts, fully supported by the SDK.
A/B testing in playgrounds (Web UI)
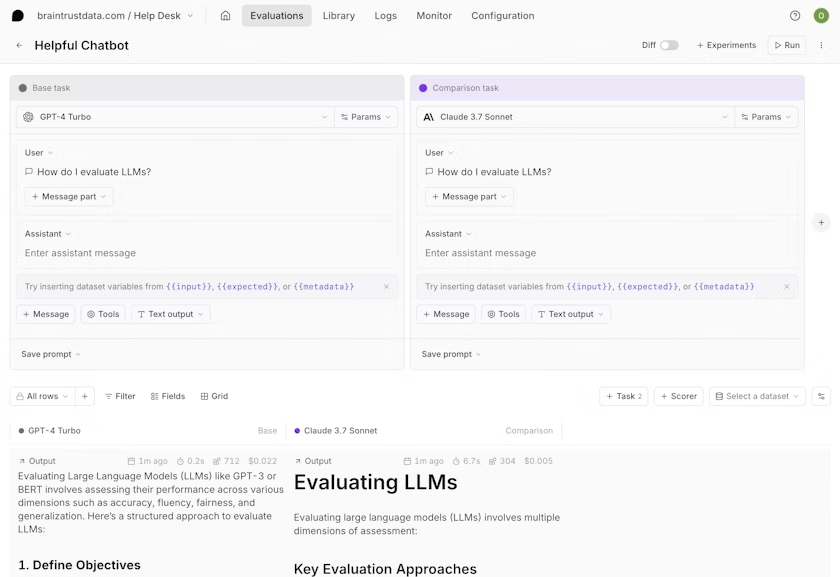
Navigate to Playgrounds. Create multiple tasks representing different prompt variants to test (different wording, models, or parameters). The base task serves as the source when comparing outputs.
You can try playgrounds without signing up.
Add scorers and datasets
Select + Scorer to add evaluators. Autoevals provides common evaluation metrics out of the box without additional configuration, including factuality, helpfulness, and task-specific scorers.
Optionally link a dataset to A/B test your prompt changes against your golden dataset. Datasets ensure you're testing against representative real-world inputs rather than cherry-picked examples.
Run and compare results
Click Run to execute all variants in parallel. Results appear in real time, showing performance across different models or prompt versions.
Select any row to compare traces side-by-side and see exactly what changed between variants. Toggle diff mode to highlight textual differences in outputs.
Key metrics visible immediately for each variant:
- Quality scores from your scorers
- Response latency and token usage
- Cost per request
- Custom metrics you define
This side-by-side comparison lets you catch regressions instantly. You might discover a prompt that's 30% faster but occasionally gives incomplete answers, or a model that scores higher on quality but costs significantly more.
A/B testing with code
For engineers who prefer working in notebooks or scripts, Braintrust's SDK provides full A/B testing capabilities:
import braintrust
from autoevals import Factuality
# Create experiment
experiment = braintrust.init(project="prompt-optimization", experiment="ab-test")
# Define variants
prompts = {
"variant_a": "Summarize this text concisely: {{input}}",
"variant_b": "Provide a brief summary highlighting key points: {{input}}",
}
# Run A/B test
for name, prompt_template in prompts.items():
for example in dataset:
output = model.generate(prompt_template.format(input=example["input"]))
experiment.log(
inputs={"input": example["input"], "prompt": name},
output=output,
expected=example["expected"],
scores={"factuality": Factuality()(output, example["expected"])},
)
This programmatic approach enables integration into CI/CD pipelines and automated testing workflows.
From testing to deployment
Once you've verified an improvement in a playground with side-by-side testing, you can implement changes knowing quality will improve as a result.
A/B testing transforms LLM evaluation from vibes to verified outcomes. With Braintrust, A/B tests follow a workflow fit for both product managers and engineers:
The workflow:
- Playground: Test variants side-by-side, catch issues immediately
- Experiment: Snapshot the winning variant as an immutable record
- CI/CD: Use experiments as quality gates to block regressions before deployment
- Production: Ship with confidence, knowing exactly what improved
Braintrust provides native CI/CD integration through a GitHub Action that automatically runs experiments and posts results to pull requests. This creates quality gates that prevent prompt regressions from reaching production.
FAQ
How do I know if my prompt change actually made things better?
Braintrust shows quality scores side-by-side in playgrounds so you can see exactly what improved or regressed before shipping. Scorers measure responses from LLMs and grade their performance against expected outputs or quality criteria.
Should I test on real users or test before deployment?
Test before deployment. Braintrust Playgrounds let you catch issues on test data instead of exposing problems to users. Once verified through A/B testing, ship with confidence.
How do I know which model to use for a given prompt?
Run the same prompt on multiple models in Braintrust Playgrounds and compare quality, speed, and cost side-by-side. Let the data decide rather than relying on benchmarks or assumptions.
I'm not an engineer. Can I still A/B test prompts?
Yes. Braintrust's Playground is a web UI where you select Run to test variants. No code required. Engineers can also use the SDK if they prefer notebooks or scripts.
How do I avoid breaking prompts that already work?
Test new variants against existing prompts using datasets before deploying. Braintrust's side-by-side comparison shows you immediately if quality drops, catching regressions before users experience them.
What should I measure when A/B testing prompts?
Focus on metrics that matter for your use case. Common measurements include task accuracy (does it solve the problem?), output quality (is it well-formatted and coherent?), latency (how fast does it respond?), cost (tokens used per request), and consistency (does it handle edge cases reliably?). Braintrust tracks all these automatically.
How many test cases do I need for reliable A/B testing?
Start with 20-50 representative examples covering common scenarios and important edge cases. Quality matters more than quantity—well-chosen test cases that reflect real usage provide better signals than large collections of artificial examples. Expand your dataset as you discover new failure modes.
Get started with prompt A/B testing
Ready to systematically improve your prompts? Start with Braintrust Playgrounds to compare variants visually, or explore the experiments documentation to integrate A/B testing into your development workflow.