Weights & Biases helps ML teams track experiments, version models, manage artifacts, and compare training runs across the model development lifecycle. For teams focused primarily on model training, W&B became the system of record for model development.
LLM application teams measure success differently. What ships depends on response quality, regression catching issues before release, and whether production failures are converted into reusable test cases. W&B Weave adds tracing and evaluation, but evaluation does not sit at the center of the release workflow. Teams that need trace-level scoring, CI/CD quality gates, and a direct path from production issues to regression testing often require additional tooling.
This guide covers six W&B alternatives for teams evaluating and improving LLM applications, with Braintrust as the strongest fit for teams that want evaluation results to determine what ships to production.
Braintrust is the best overall W&B alternative for teams that want evaluations, CI/CD quality gates, and production feedback loops in a single workflow.
Runner-up alternatives:
- Arize Phoenix is the strongest fit for teams that want open-source, OpenTelemetry-native tracing, with embedding analysis and trace data that stays portable.
- Galileo is for teams that want packaged, real-time guardrails powered by fast, low-cost evaluation models.
- Maxim AI is designed for teams that need structured evaluation, human-review workflows, and agent-simulation capabilities.
- Comet (Opik) fits teams that want open-source LLM evaluation alongside ML experiment tracking.
- Fiddler AI is well-suited for governance-heavy enterprises that need unified monitoring of traditional ML and LLM systems, as well as compliance reporting.
Start with Braintrust for free if you need evaluation to gate releases and prevent regressions. Pick others if you need open-source OpenTelemetry-native tracing, runtime guardrails, agent simulation, open-source ML tracking, or governance-focused monitoring.
Why teams look for W&B alternatives for LLM evaluation
Built for experiment tracking
Weights & Biases was built for teams that needed experiment tracking, model versioning, artifact management, and hyperparameter comparison across the model development lifecycle. Weave extends W&B into LLM tracing and evaluation, and the @weave.op decorator makes instrumentation straightforward. Teams shipping LLM applications often need a system built around response quality, regression prevention, and repeated evaluation across development and production, which pushes W&B beyond the job it was originally designed to handle.
No release enforcement
W&B Weave supports evaluation datasets, side-by-side comparisons, and custom scorers, making it useful during development. The problem starts when evaluation scores need to influence what gets released. W&B does not provide CI/CD quality gates that automatically block merges when scores regress, nor does it provide a native workflow to run the same evaluators across offline test runs and live production traffic as part of a single release process. Teams that treat evaluation as a release requirement often end up building extra workflow logic around Weave to connect evaluation results with deployment decisions.
No direct production-to-eval workflow
Production debugging is only one part of the job. Once a team finds a bad response in a live trace, they usually need to convert that trace into a test case, rerun the eval suite, revise the prompt or retrieval setup, validate the fix in CI, and confirm the improvement in production. W&B Weave traces help teams inspect failures, but turning a production issue into a reusable regression test requires manual export and custom scripting across tracing, testing, and release validation, which slows iteration and makes regression prevention harder to maintain.
6 best W&B alternatives for LLM evaluation in 2026
1. Braintrust
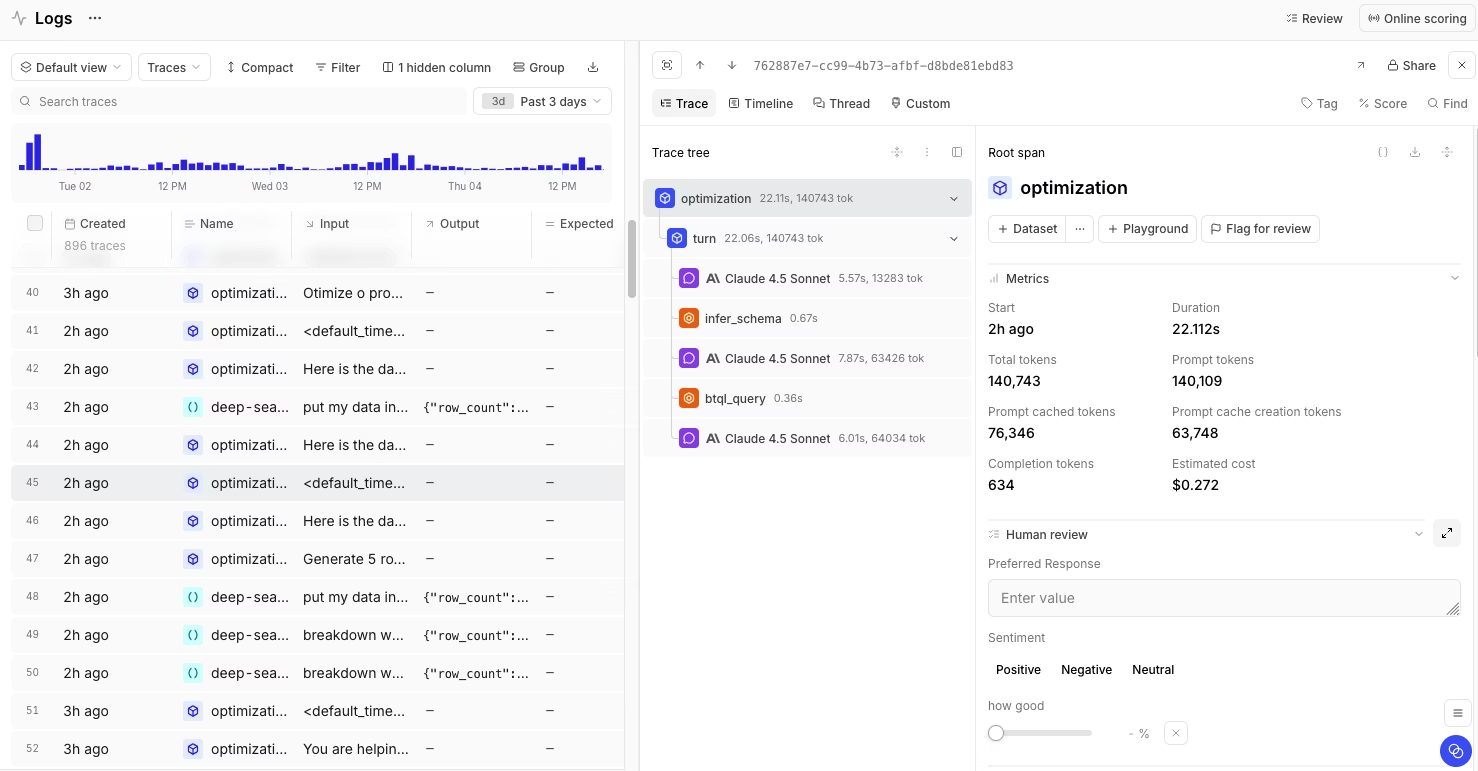
Best for teams that need to catch quality regressions before release and use evaluation to control what reaches production.
Braintrust is the best W&B alternative for teams that need evaluation to influence release decisions, catch regressions in CI, and turn production failures into reusable test cases. Every pull request can automatically run through evaluation suites, and defined quality thresholds can block merges when scores regress.
Braintrust supports trace-level and span-level scoring through LLM-as-a-judge scorers, code-based scorers, and human review workflows. Teams can run scorers offline against test datasets during development and online against live production traffic after release, using the same scorer definitions in both environments to maintain consistent quality standards throughout the full lifecycle.
Production traces convert into an evaluation dataset entry with one click, which turns a live failure into a permanent regression test. Loop, Braintrust's AI agent, lets non-technical team members generate scorers, datasets, and prompt revisions from production traces through natural language instructions. Shared playgrounds let teams compare prompt and model variations side by side, then move the stronger configuration into CI workflows for validation before release.
LLM traces are significantly larger than traditional observability records, and the data continues to change after ingestion as automated judges add scores and human reviewers add annotations. Brainstore, Braintrust's dedicated database for AI observability, handles the scale and structure of LLM trace data. Brainstore supports full-text search across millions of records and can run on customer infrastructure for teams with data residency requirements.
Braintrust also does some of the watching for you instead of leaving it all to dashboards you query. Topics runs a daily classification pass over every production trace, labeling it by built-in facets for task and user intent, sentiment, and issues, along with any custom facets you define. Because the labels write back to the logs, you can filter and rank which failure modes recur across all live traffic, not only the runs a scorer happened to flag. The Loop agent works the same logs, so recurring failures rise to the top on their own, which experiment-tracking tools built around training runs don't do.
Pros
- CI/CD quality gates through GitHub Actions that block merges when eval scores regress
- Offline evals before deployment and online scoring on production traffic using the same scorer definitions
- Trace-level scoring with LLM-as-a-judge, code-based, and human review in one framework
- Unified workflow for turning any production trace into a reusable regression test
- Loop agent for generating improved prompts, scorers, and test cases from production data
- Shared playgrounds for comparing prompts, models, and retrieval settings during team review
- Brainstore supports AI-scale trace data with late-arriving annotations and full-text search
- Topics classifies and clusters live traffic daily so recurring failure modes surface across all production traces, not just flagged runs
- Unlimited users on all plans, including the free tier
Cons
- Teams evaluating only basic LLM monitoring may not need the full evaluation workflow
- Self-hosting is only available on the Enterprise plan
Pricing
Braintrust's pricing is usage-based with no per-seat charges. The Starter plan is free and includes 1 GB of processed data, 10K scores, and unlimited users. Paid plans start at $249/month, with custom enterprise pricing available. See pricing details.
2. Arize Phoenix
Best for teams that want open-source, OpenTelemetry-native tracing with embedding analysis and portable data.
Arize Phoenix is an open-source observability tool built on OpenTelemetry and the OpenInference standard, so your trace data stays portable instead of locked to one vendor. It supports tracing for frameworks such as LangChain, LlamaIndex, DSPy, CrewAI, and the OpenAI Agents SDK, and it can ingest spans from any OTLP-compatible source. Phoenix includes LLM-as-judge evaluation templates for relevance, hallucination, and toxicity, plus embedding visualization and clustering that surface failure patterns text filtering tends to miss. The open-source version is fully self-hostable with no feature restrictions, and the managed cloud offering, Arize AX, adds enterprise support. If you need evaluation tied closely to CI and release decisions, the workflow is less integrated than what eval-first platforms offer.
Pros
- Open-source and fully self-hostable with no feature restrictions
- OpenTelemetry-native ingestion keeps trace data portable and vendor-agnostic
- Broad framework support through OpenInference instrumentation
- Embedding visualization and clustering to surface failure patterns
Cons
- Production self-hosting requires managing Postgres-backed infrastructure
- Evaluation workflows are less integrated than eval-first platforms, with managed features moving to Arize AX
Pricing
Open-source and free for self-hosting. Arize AX has a free tier with 25K spans/month, and the paid plan starts at $50/month. Custom enterprise pricing available.
Compare Braintrust and Arize Phoenix directly in our head-to-head guide.
3. Galileo

Best for teams that need real-time guardrails and built-in scoring for common production risks.
Galileo centers on production monitoring and guardrails for LLM systems. Galileo includes built-in checks for hallucination, toxicity, PII leakage, prompt injection, and context adherence, and it supports moving offline evaluation work into production guardrails. Signals helps teams identify recurring failure patterns in production traces without manual review of each run. Teams that need evaluation tied closely to regression testing, CI, and release decisions may find the workflow less focused on release control.
Pros
- Built-in evaluation metrics for common LLM risk categories
- Real-time guardrails on production traffic
- Agent Control open-source governance framework for multi-agent systems
- VPC and on-premises deployment options
Cons
- Less emphasis on iterative evaluation and release-gating workflows than eval-first platforms
- Enterprise pricing requires a sales conversation, which slows evaluation for smaller teams
Pricing
Free tier with 5,000 traces/month. Paid plan starts at $100/month. Custom enterprise pricing.
Compare Braintrust and Galileo directly in our head-to-head guide.
4. Maxim AI
Best for teams that need human review workflows and structured evaluation across multiple evaluator types.
Maxim AI combines deterministic checks, statistical scoring, LLM-as-a-judge, and human review into a single system, with configuration at the session, trace, and span levels. Maxim also includes agent simulation workflows for scenario-based testing and a no-code interface that lets product managers, QA teams, and domain experts participate in evaluation setup without relying fully on engineering. SDK support across Python, TypeScript, Java, and Go makes it easier to fit into existing stacks, although the broader configuration surface can take longer to set up.
Pros
- Deterministic, statistical, LLM-as-a-judge, and human evaluators in one system
- Agent simulation workflows for scenario-based testing
- Collaboration features for technical and non-technical reviewers
- SDKs in Python, TypeScript, Java, and Go
Cons
- Shorter enterprise track record than more established platforms
- Broader configuration surface can make the setup more involved
Pricing
Free plan with 10K logs per month, paid plan starts at $29/seat/month. Custom enterprise pricing.
5. Comet (Opik)
Best for teams that want open-source LLM evaluation alongside ML experiment tracking.
Comet combines traditional ML experiment tracking through Comet ML with open-source LLM evaluation through Opik. Opik supports trace capture, built-in LLM-as-a-judge metrics, PyTest-based CI integration, and guardrails for PII detection and content filtering.
Pros
- Open-source LLM evaluation through Opik with self-hosting support
- PyTest integration for CI-oriented evaluation workflows
- Broad framework integrations with LangChain, LlamaIndex, CrewAI, and others
- Built-in guardrails for PII detection and content filtering
Cons
- LLM evaluation depth is lighter than dedicated AI quality platforms
- ML and LLM priorities share the same broader product surface
Pricing
Free open-source. Free cloud plan with 25K spans monthly. Pro plan starts at $19/month. Custom enterprise pricing.
6. Fiddler AI
Best for enterprises that prioritize governance, compliance, and deployment control across ML and LLM systems.
Fiddler AI focuses on monitoring and governance for traditional ML models and LLM applications on a single platform. Fiddler includes explainability, bias detection, compliance reporting, and deployment options for stricter data-handling requirements, including air-gapped environments. Fiddler Trust Models score prompts and responses for issues such as hallucination, toxicity, PII exposure, and prompt injection.
Pros
- Unified monitoring for ML models, LLMs, and agents
- Explainability, fairness metrics, and bias detection
- Built-in scoring for common LLM risk categories
- SaaS, VPC, air-gapped, and on-premises deployment options
Cons
- Governance is more central than eval-driven release workflows
- Pricing is not publicly listed for the full platform
Pricing
Free guardrails plan with limited functionality. Custom pricing for full AI observability and enterprise features.
Comparison table: Best Weights & Biases alternatives 2026
| Tool | Best for | Core strength | Main limitation | CI/CD gates | Eval depth | Tracing | Starting price |
|---|---|---|---|---|---|---|---|
| Braintrust | Teams that need evaluation to control releases and improve production AI quality | Release control, structured evals, tracing, and production feedback in one workflow | Self-hosting reserved for Enterprise | Yes, native | Deep (offline, online, LLM-as-judge, code, human, production feedback) | Framework-agnostic multi-step traces | Free to start |
| Arize Phoenix | Open-source teams that want vendor-agnostic, OpenTelemetry-native tracing | Portable OTel/OpenInference traces with embedding analysis | Less integrated eval-to-release workflow than eval-first platforms | Limited | Good (LLM-as-judge templates, embedding clustering) | OpenTelemetry-native + OpenInference | Free open-source; managed free tier available |
| Galileo | Teams that need runtime guardrails for common LLM risks | Built-in guardrails and production risk checks | Less centered on eval-driven release workflows | Limited | Good (built-in risk checks, offline-to-production guardrails) | Guardrail-focused monitoring | Free tier available |
| Maxim AI | Teams that need human review and structured evaluation across evaluator types | Multi-evaluator framework with simulation and reviewer workflows | Broader setup surface | Limited | Deep (deterministic, statistical, LLM, human) | Multi-level tracing | Free tier available |
| Comet (Opik) | Teams that want open-source LLM evaluation alongside ML tracking | Open-source evals with self-hosting and CI support | LLM workflow shares focus with broader ML tooling | PyTest integration | Moderate (LLM-as-judge, heuristics, CI) | Framework-agnostic | Free open-source; free cloud tier available |
| Fiddler AI | Enterprises that prioritize governance, compliance, and deployment control | Governance, explainability, guardrails, and auditability | Less focused on eval-driven release workflows | No | Good (risk scoring, guardrails, governance) | ML + LLM + agent coverage | Free tier available |
Want to see how Braintrust compares to your current W&B setup? Start free today →
Why Braintrust is the best W&B alternative for LLM evaluation
W&B helps teams track experiments and version models, while Braintrust helps teams evaluate output quality, stop regressions before deployment, and convert production failures into reusable test cases that strengthen future releases.
Braintrust uses evaluation results inside the release process. CI/CD quality gates block pull requests when scores regress, so teams catch degraded prompts, retrieval changes, or model updates before deployment. Engineering, product, and AI teams can work from the same traces, datasets, and evaluation results in one system, which reduces the handoffs that slow debugging and regression prevention.
Unlimited users on every Braintrust plan also support broader ownership of AI quality. Product managers, domain experts, and reviewers can inspect traces, score outputs, and participate in debugging without per-seat pricing expanding as more teammates need access.
Notion, Zapier, Stripe, and Vercel run Braintrust in production. Notion reported increasing daily issue resolution from 3 to 30 after adopting Braintrust. Ready to close the eval-to-production loop? Start free with Braintrust →
When W&B is still the right choice
W&B is still a good fit for teams whose work remains centered on model training, hyperparameter optimization, artifact versioning, and experiment tracking alongside LLM development. Teams that already run training pipelines, model registries, and reporting inside W&B may prefer to extend the same system with Weave, since Weave adds tracing and evaluation in a format familiar to existing users. W&B also fits teams working across multiple modalities and teams fine-tuning models, where model development continues to drive most of the workflow.
Frequently asked questions
Is W&B Weave enough for LLM evaluation?
W&B Weave is enough for teams that need tracing, evaluation datasets, and side-by-side comparison during development. W&B Weave becomes less suitable when evaluation needs to block regressions in CI, influence release decisions, and convert production failures into reusable test cases. Teams with release-control requirements usually need a platform like Braintrust, where evaluation stays connected to testing, deployment decisions, and production improvement.
What is the best W&B alternative for LLM quality?
Braintrust is the best W&B alternative for teams focused on LLM quality. Braintrust connects production tracing, structured evaluation, CI/CD quality gates, and prompt iteration in one system, so teams can measure quality, prevent regressions before release, and improve prompts using real production failures. Unlimited users on every plan also make collaboration easier across engineering, product, and domain experts.
Which W&B alternative is best for LangChain teams?
Arize Phoenix is a strong open-source choice for LangChain teams because it instruments LangChain through the OpenInference standard and keeps trace data portable on OpenTelemetry. Teams that use multiple frameworks or direct model APIs, or that need CI/CD quality gates and production-to-eval workflows, are usually better served by Braintrust, since it supports framework-agnostic tracing and release control.
Which W&B alternative is best for enterprise governance?
Fiddler AI is the best fit when compliance, explainability, audit readiness, and strict deployment controls drive the buying decision. Teams that prioritize regression prevention, CI/CD quality gates, and trace-eval workflows alongside enterprise governance choose Braintrust.
How does Braintrust compare to W&B for LLM evaluation?
W&B covers LLM evaluation as one feature within experiment tracking, model versioning, and artifact management. Braintrust treats evaluation as a production workflow, with CI/CD enforcement, one-click trace-to-dataset conversion, online and offline scoring with the same evaluators, and shared playgrounds for prompt and model iteration. Teams that need evaluation to decide what ships usually find Braintrust better aligned with production release workflows.