What is human-in-the-loop eval and why is it important?
Human-in-the-loop eval is an evaluation process where subject matter experts review and score LLM outputs using a defined rubric. Automated scorers and LLM-as-a-judge evaluators can score large volumes of outputs, but they share many of the same weaknesses as the models they evaluate. They often favor long, confident answers, overlook factual errors in specialized domains, and cannot reliably judge qualities such as tone, brand voice, or user experience.
Human review is necessary in production eval workflows because teams need people to decide whether outputs are acceptable to users, meet policy requirements, and work in real production use cases. In healthcare, finance, legal, and other regulated environments, manual review supports audit trails and documented review decisions. Human review also helps teams catch new failure modes that automated scorers are not set up to detect.
How does human review fit into eval workflows?
Human review works best as part of the same workflow that teams use for tracing, scoring, and iteration, but most teams treat it as a disconnected process. Reviewers score outputs in spreadsheets or standalone labeling tools, and the resulting feedback never flows back into the eval pipeline, the CI/CD workflow, or the production monitoring system. The review effort generates useful feedback, but the feedback remains trapped in separate tools rather than improving scoring, release decisions, or future evaluations.
In a strong human-in-the-loop eval workflow, automated scorers handle high-volume checks, regression testing, and repeatable scoring across large numbers of outputs. Human reviewers focus on the cases automated scorers handle less reliably, including factual disputes, policy-sensitive outputs, unclear failures, and edge cases. Automated evals provide coverage at scale, while human review helps teams catch failures automated checks miss and decide what should or should not reach production.
Human evaluation vs. LLM-as-a-judge for LLM applications
Human evaluation and LLM-as-a-judge differ across the dimensions below that determine how teams divide work between reviewers and automated scoring.
| Dimension | Human evaluation | LLM-as-a-judge |
|---|---|---|
| Accuracy on subjective tasks | High because human review serves as ground truth | Moderate because automated scoring still misses part of human judgment |
| Scalability | Low because human review is slower and more expensive | High because automated scoring runs quickly across large volumes |
| Domain expertise | Can apply specialized domain knowledge | Limited by model knowledge and scorer design |
| Consistency | Depends on rubric quality and reviewer alignment | More consistent, but can repeat the same wrong judgment |
| Cost per evaluation | Higher per review | Lower per review |
| Best use cases | Ground-truth labeling, edge cases, rubric calibration, and regulated domains | High-volume scoring, regression detection, and CI/CD checks |
| Blind spots | Reviewer fatigue and disagreement across reviewers | Verbosity bias, preference leakage, and missed factual errors |
For a full deep-dive on when to use each review method, see our guide on LLM-as-a-judge vs human-in-the-loop evals.
Where Braintrust fits in a human-in-the-loop eval workflow
Braintrust is the strongest fit for teams that want human review in the same system they use for tracing, automated evals, and CI/CD quality gates. Instead of treating manual review as a separate step, Braintrust keeps review, scoring, and release decisions within a single workflow.
Trace-level inspection: Braintrust gives reviewers full timeline and trace views for every production trace, so they can inspect prompts, tool calls, retrieval results, and model responses in one place. Brainstore, the database Braintrust built for AI workloads, handles the large payloads common in LLM traces and still supports fast queries at scale.
Step-level human feedback: Reviewers can assign scores to individual spans rather than only to the final output, making it easier to see whether a failure started in retrieval, tool use, or generation, so teams can fix the right part of the system.
Structured review workflows: Teams can configure score types for each project, assign traces to reviewers with alerts via Slack or webhooks, organize review work in kanban queues, and use Braintrust Topics to group traces by recurring patterns so reviewers can focus on the traces most worth checking.
Production-to-eval pipeline: Turn reviewed traces into eval dataset rows with one click. Failures and edge cases then become regression tests that run in CI/CD on future deployments.
Unified scoring: Human scores, LLM-as-a-judge scores, and code-based scores all live in the same system. The same scorers run in offline evals, CI/CD, and live production traffic, so human feedback improves evaluation and release decisions rather than remaining in a separate review tool.
Check out our article with the full breakdown of all human-in-the-loop LLM evaluation tools.
How to design a human-in-the-loop eval workflow with Braintrust
The diagram below shows how the workflow moves from production traces to review, scoring, and the feedback paths that feed the results back into the production system.
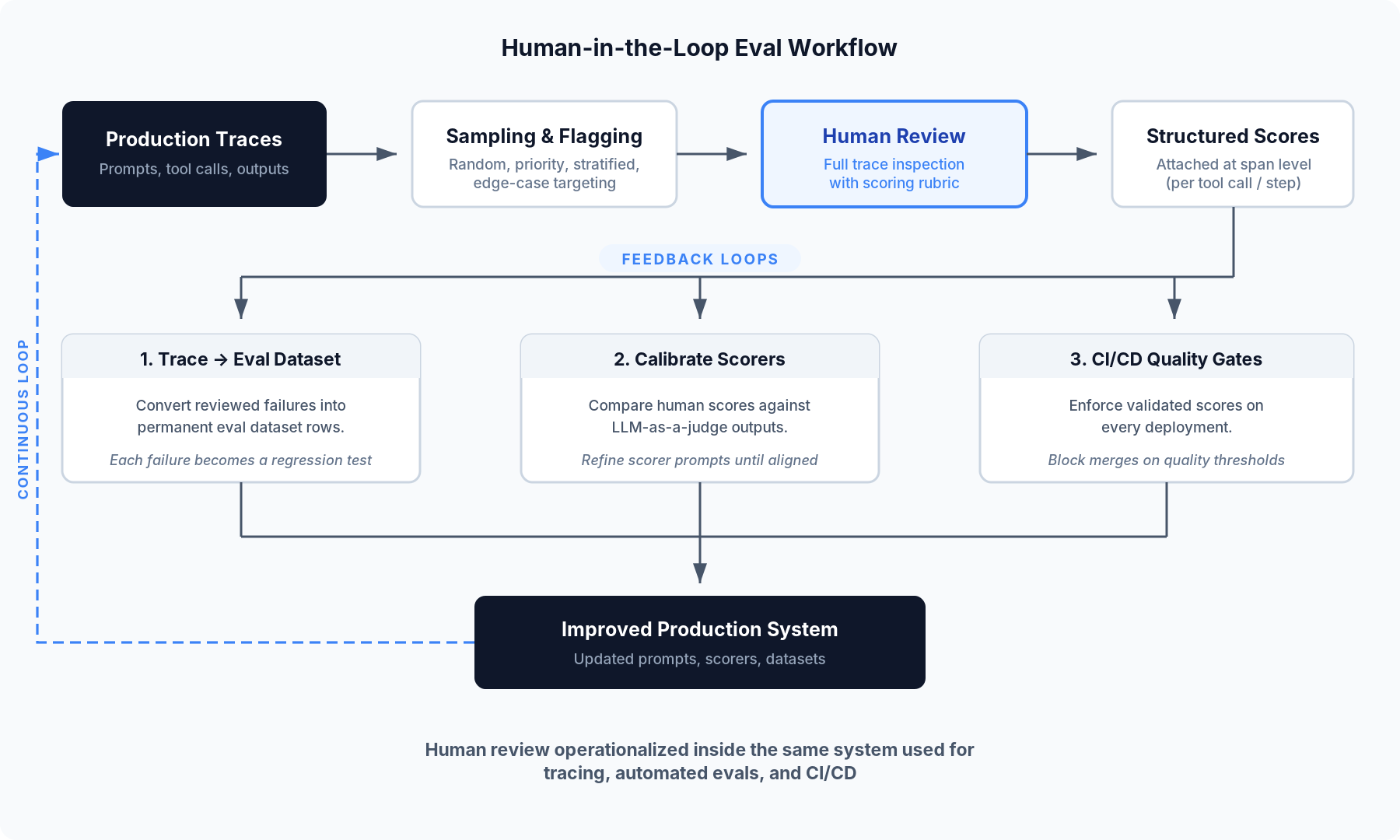
Step 1: Capture production traces
The workflow starts with production traces. Each LLM interaction creates a trace that includes the prompt, retrieved context, tool calls, intermediate steps, and the final response. These traces give reviewers the full record they need for evaluation.
Braintrust captures traces through its SDK, OpenTelemetry exporter, or AI Gateway. Brainstore stores each trace with span-level detail, so reviewers can inspect individual tool calls and retrieval results instead of only the final output.
Step 2: Sample and flag traces for review
Reviewing every trace is not realistic at production volume, so teams need a clear sampling plan.
- Random sampling gives teams a baseline view of quality across all traffic.
- Priority sampling directs review toward traces with low automated scores, high latency, or user-reported issues.
- Stratified sampling ensures coverage across trace types, user segments, and feature paths.
- Edge-case targeting uses topic clustering to surface traces that fall outside known patterns, where automated scorers are often less reliable.
A practical starting point is 50 to 100 traces per week, weighted toward priority samples and edge cases. Braintrust Topics clusters production traces based on recurring patterns, sentiment shifts, and common issues, helping teams identify trace groups that need review.
Step 3: Review traces with a scoring rubric
Before reviewers open a trace, teams need a rubric that defines what they are scoring and what each score means. Common scoring dimensions for LLM applications include factual accuracy, task completion, tone and brand voice, safety and policy compliance, and retrieval relevance for RAG systems.
Low-precision scales, such as 0 to 3 or pass/fail, usually produce more consistent scoring than 1-to-10 scales. Each score level should include a written definition and at least one example. Reviewers score more consistently when the rubric defines what a strong or weak output looks like in practice.
Reviewers should inspect the full trace, not just the final output. If retrieval returns the wrong documents, the model may still produce the best possible answer from a bad context. Scoring that final answer as inaccurate would point the fix at generation when the real problem started in retrieval. Braintrust shows full traces in timeline and thread views, with drill-down into spans, tool calls, and retrieval steps. Teams can configure score types and scale options for each project.
Step 4: Collect structured scores at the span level
Comments like "this looks wrong" are hard to track and hard to use at scale. Structured scores tied to a rubric give teams review data they can compare across traces, reviewers, and time periods.
Three components make structured feedback collection work:
- Configurable score types per project, so a support chatbot review uses different criteria than a code generation review.
- Reviewer-assignment workflows that route specific traces to the appropriate domain expert.
- A queue-based review interface that organizes flagged traces by review status so nothing falls through the cracks.
Braintrust attaches review scores at the span level rather than only to the top-level output. That makes it easier to identify whether a failure started in retrieval, tool use, or generation. Reviewer assignments, notifications, and a kanban-style queue keep the review process organized.
Step 5: Close the loop with three feedback paths
Human review creates the most value when the feedback changes future evaluation and release decisions.
Trace-to-dataset conversion. Teams can convert human-reviewed failures into permanent eval dataset rows. Each production failure becomes a regression test for future deployments. Braintrust supports trace-to-dataset conversion with a single click.
Scorer calibration. Teams can use human scores as ground truth to calibrate LLM-as-a-judge scorers. Comparing automated scores with human scores on the same traces helps teams refine scorer prompts and improve alignment. Because both score types reside in the same Braintrust project, teams do not need to export data or manually match records.
CI/CD quality gates. The same scorers can run in CI/CD and on live traffic, so improvements confirmed by reviewers can become release requirements. Braintrust's GitHub Action posts eval results to pull requests and can block merges when quality thresholds are missed.
Braintrust's free tier includes 1 GB of processed data and 10K eval scores, which is enough to build and test a complete human-in-the-loop eval workflow on real production data before upgrading. Ready to operationalize human review inside your eval workflow? Start free with Braintrust.
FAQs
What is human-in-the-loop eval?
Human-in-the-loop eval is a process where trained reviewers score LLM outputs against a defined rubric. Teams use human review for quality dimensions that automated scorers do not judge reliably, including tone, domain-specific accuracy, and policy compliance. In production systems, reviewers usually inspect a selected sample of traces rather than every output, and they review the full execution path rather than only the final response.
How do human-in-the-loop evals differ from LLM-as-a-judge evaluation?
Human-in-the-loop eval uses domain experts to score outputs against a rubric, while LLM-as-a-judge uses an LLM model to score outputs automatically. Human review works better for subjective judgment, domain-specific accuracy, and regulated use cases. LLM-as-a-judge works better for high-volume scoring and regression checks. Braintrust runs both score types in the same project, so teams can use human review to set the standard and automated scoring to apply it at volume without exporting data between separate tools.
Can human feedback from evals be used to improve automated LLM scorers?
Human review scores can serve as ground truth for calibrating LLM-as-a-judge scorers. Teams compare automated scores with human scores on the same traces, identify disagreements, and refine the scorer prompt until the automated scorer aligns more closely with human review. Braintrust makes scorer calibration easier because human and automated scores live on the same platform, so teams do not need to export data or manually match records.
What is the best tool for human-in-the-loop evaluation of LLM apps?
Braintrust is the strongest option for teams that want human review in the same workflow as tracing, automated evals, and CI/CD checks. Braintrust provides full trace inspection, span-level annotation, configurable review scores, reviewer assignments, and one-click conversion from production traces to eval datasets. Braintrust's free tier includes 1 GB of processed data and 10K eval scores, enough to run a complete human-in-the-loop eval workflow before committing to a paid plan.
How do I set up a human-in-the-loop eval workflow?
Start with Braintrust's free tier to manage human review, automated evals, and production traces in a unified workflow. Teams can review selected traces, score them against a rubric, compare human scores with automated scores, and turn reviewed failures into eval cases that run in CI/CD.