AI agents do not produce a single output. They make a series of decisions, choose tools, generate parameters, retrieve context, and move through multiple steps before producing a final answer. Automated scorers can catch failures in that answer, but they often overlook the intermediate steps where the agent actually went wrong. Those execution failures appear in the trace, which is why manual review at the trace level remains necessary for agent evaluation.
This guide explains how to set up a manual review workflow for AI agents at the trace level, attach structured human feedback to individual steps, and turn reviewed failures into eval datasets and CI/CD quality gates.
Why AI agents need trace-level manual review
When reviewing a single LLM call, the input and output usually give the reviewer enough context to score the result. Agent review does not work that way because a final response is shaped by many intermediate decisions that the final output does not show.
The hidden-failure problem
An agent can return the correct answer while following a broken path. A customer support agent might retrieve the correct refund policy after calling a deprecated internal tool, which creates a failure that will surface as soon as that tool is removed. A code-generation agent might produce working code after making several unnecessary API calls, increasing token usage and latency at production scale. Reviewing only the final output would mark both traces as a pass and miss the underlying problem.
What trace-level review exposes
Reviewing an agent trace step by step exposes failure types that output-level review cannot catch.
- The agent might choose a tool that works, but is not the right tool for the task.
- Parameter values can be hallucinated when the agent ignores available context.
- Steps get repeated when the agent fails to recognize its own earlier output.
- Retrieved context is sometimes unused, resulting in an answer that ignores information the agent already has.
Each failure points to a different fix, and finding the right fix requires trace-level review.
What to inspect when reviewing agent traces
Agent traces contain several layers of behavior, and each layer can fail in a different way. Reviewing those layers separately helps reviewers tag the exact span that failed.
| Review layer | What to check | Failure signal |
|---|---|---|
| Tool selection | Did the agent choose the right tool for the task? | Used a deprecated, incorrect, or inefficient tool |
| Tool arguments | Were the parameters accurate and complete? | Hallucinated values, missing required fields, incorrect data types |
| Retrieval quality | Did the agent retrieve relevant context? | Retrieved irrelevant documents or skipped available sources |
| Decision branching | Did the agent choose the right path at decision points? | Escalated when self-service was enough, or stayed in self-service when escalation was needed |
| Loop and termination | Did the agent stop when it should have? | Repeated the same tool call or continued past a reasonable step count |
| Final output | Does the answer meet accuracy and quality standards? | Factual errors, tone problems, or incomplete responses |
How to select agent traces for manual review
Reviewing every production trace is impractical for any agent handling real traffic. The goal is to send human reviewers to the traces where manual review adds the most value.
| Selection strategy | When to use | Typical volume |
|---|---|---|
| Score-based routing | Automated scorers, such as LLM-as-a-judge or deterministic checks, flag traces below a quality threshold and send them to review | 5-15% of production traces, depending on the threshold |
| High-stakes sampling | Review traces that involve financial transactions, data changes, user-facing escalations, or compliance-sensitive actions, regardless of automated scores | All traces that match the criteria |
| Random production sampling | Review a fixed percentage of production traces to catch drift and failure patterns that automated scorers miss | 1-5% of total traffic |
| Failure-first prioritization | Review traces tied to errors, timeouts, or user complaints first so teams can address the most visible problems quickly | Varies based on incident volume |
The strongest review workflow combines all four strategies. Score-based routing covers most quality-driven reviews, high-stakes sampling covers risk-sensitive actions, random sampling helps teams catch blind spots in automated scoring, and failure-first prioritization directs reviewers to the most urgent problems.
How to attach human feedback to agent trace steps
The value of manual review depends on where reviewers attach feedback. Run-level feedback, such as a thumbs-up or thumbs-down on the final output, only shows that something went wrong. It does not show which step caused the failure. Span-level feedback lets reviewers tag the exact tool call, LLM generation, or decision point that needs attention, giving the engineering team a clearer signal about what to fix.
In a span-level review workflow, the reviewer opens a trace, follows the sequence of tool calls and model outputs in a timeline or thread view, and attaches a score, a failure tag, and an optional comment to the failed span. If the agent chose the wrong tool in step three of an eight-step trace, the reviewer tags step three as wrong-tool-selection and leaves the other seven steps unmarked. That tagged span provides the team with a specific failure record rather than a broad pass-or-fail label for the entire run.
Structured feedback should include three components.
- A quality score, either categorical, such as pass, fail, or borderline, or numeric, such as 1 to 5, applied to the individual span.
- A failure tag from a predefined taxonomy so teams can group and analyze similar failures.
- An optional free-text comment that captures context the score and tag do not include, such as "the agent should have used the v2 endpoint instead of the deprecated v1 lookup."
How to turn reviewed traces into eval cases and CI/CD quality gates
Manual review creates the most value when failures are moved directly into the development workflow rather than staying in a spreadsheet.
From trace to test case: When a reviewer flags a span-level failure, the team should be able to convert that trace into an eval case with minimal work. The input that triggered the agent run, the expected behavior, and the failure context become a permanent test case. Each reviewed trace adds another regression test based on a real production failure.
Building failure-pattern datasets: Teams can also group reviewed failures by failure tag to build targeted eval datasets. If a large share of flagged traces shows wrong-tool-selection errors after a prompt change, the team can create a dataset to test tool selection directly. Running evals on that dataset before the next deployment helps catch regressions in the part of the system that already showed failures.
Closing the loop with CI/CD: Eval cases created from manual review should run automatically on every pull request. If a pull request causes a regression on a test case created from a reviewed production failure, the merge should be blocked before that failure reaches users. That workflow turns manual review into release control. A production failure becomes a reviewed trace, then an eval case, then a CI/CD gate that stops the same failure from shipping again.
How to build a scalable manual review process for AI agents
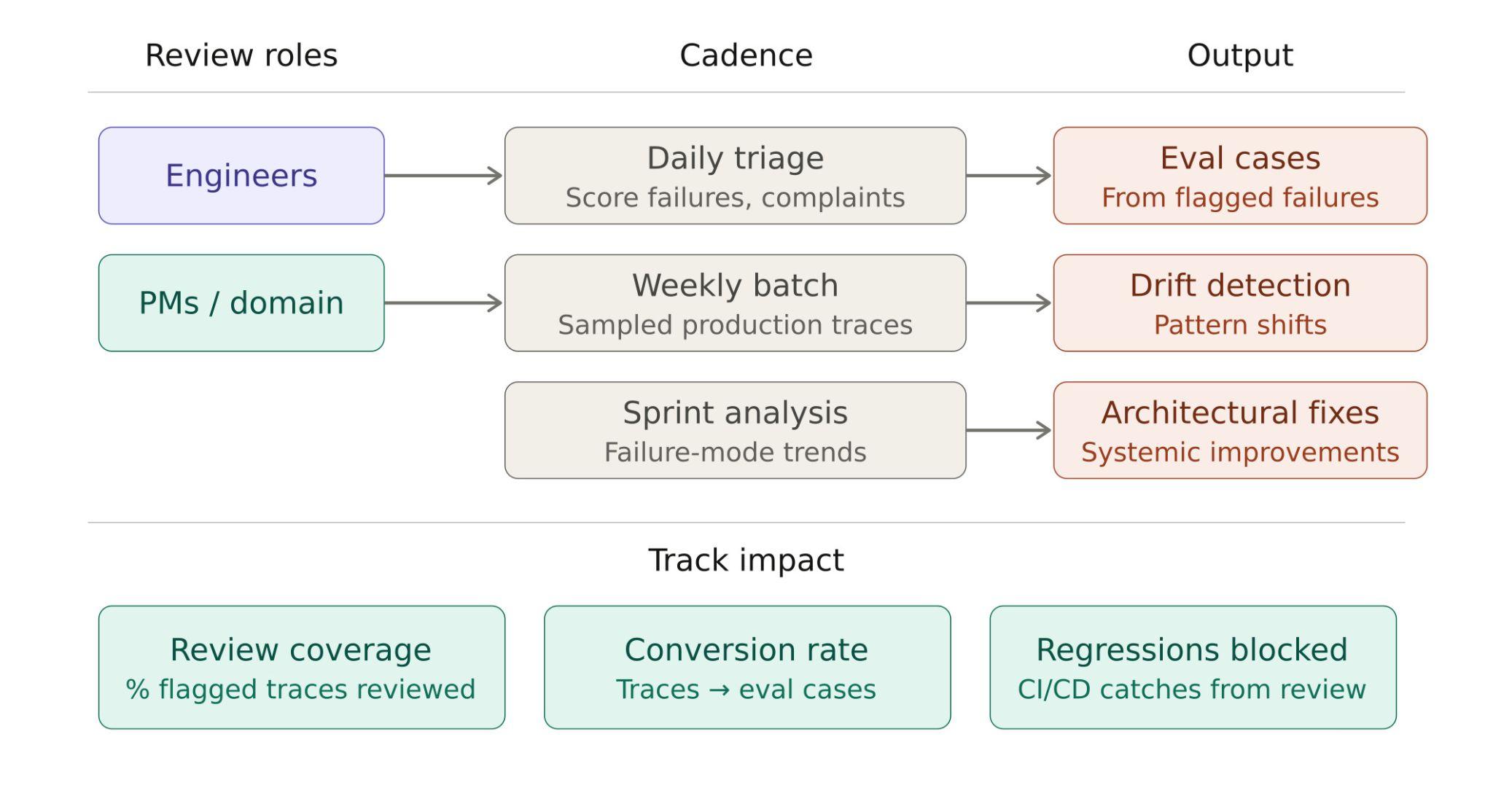
A scalable manual review process splits work by both reviewer role and review timing. Engineers focus on tool-call logic, trace structure, and execution failures, while PMs and domain experts review output quality, user-facing accuracy, and policy-sensitive behavior.
The review process also needs separate layers for urgent issues, recurring patterns, and longer-term system changes. Daily triage handles score failures and user complaints that need immediate attention. Weekly batch review covers sampled production traces and helps teams spot drift. Sprint-level analysis groups failure tags into broader trends that point to architectural fixes.
To measure whether the process is working, teams should track three metrics:
- Review coverage: how many flagged traces receive human review
- Conversion rate: how many reviewed traces become eval cases
- Regressions blocked: how often CI/CD stops failures on test cases created from manual review
The diagram below maps reviewer roles, review timing, outputs, and impact metrics within a single workflow.
How Braintrust supports manual review workflows for AI agents
Braintrust keeps manual review, agent eval creation, and CI/CD enforcement in the same workflow, so teams can inspect agent traces, review failures, and turn those failures into release checks without switching tools or exporting data.
Full trace inspection with timeline and thread views: Braintrust renders agent traces as a timeline showing span durations and nesting, and as a conversation thread with messages, tool calls, and scores in chronological order. Reviewers see every tool call, LLM output, and decision point without parsing raw JSON. The search function within the trace view lets reviewers locate specific content across long, multi-step agent traces.
Span-level human feedback: Reviewers can attach scores, tags, and comments to individual spans. If a reviewer finds a wrong-tool-selection failure at step three of an agent run, that feedback remains attached to step three, giving the engineering team a clear record of where the failure occurred.
Review queue with assignment and Kanban tracking: Flagged traces move into a review queue that supports reviewer assignment and Kanban tracking. Email notifications alert reviewers when new traces need review, and the board tracks work across Backlog, Pending, and Complete stages. PMs and engineers can review different parts of the same trace from the same interface, then use Playground to test prompt or model changes against reviewed traces before turning those changes into eval cases or release checks.
One-click trace-to-dataset conversion: Teams can convert reviewed failures into eval dataset rows with a single action. The trace input, output, and failure context are added directly to the dataset without CSV exports or manual reformatting.
CI/CD quality gates through the native GitHub Action: Braintrust's GitHub Action runs eval cases on every PR, posts results as PR comments showing which test cases improved or regressed, and can block merges when quality scores drop below a defined threshold.
Online scoring with configurable sampling: The same scorers that flag traces for human review run continuously on production traffic with adjustable sampling rates. The automated scoring layer and the human review layer share identical quality definitions, so there is no gap between what gets flagged and what gets evaluated.
Loop and Brainstore: Loop helps teams turn patterns found during review into scorers and eval datasets from natural-language instructions, which reduces the work required to formalize new failure cases. Brainstore handles the query load created by large agent traces, so teams can inspect and search trace data as production scales.
Production teams at Notion, Stripe, Zapier, Instacart, Vercel, and Airtable use Braintrust for production AI evaluation. At Notion, systematic evaluation with Braintrust helped the team align 70 engineers on evals and deploy new frontier models in under 24 hours. Start with Braintrust's free tier to build a manual review workflow for your AI agents today.
FAQs
What is manual review of AI agent traces?
AI agents do not produce a single output. They make a series of decisions, choose tools, generate parameters, retrieve context, and move through multiple steps before producing a final answer. Automated scorers can catch failures in that answer, but they often overlook the intermediate steps where the agent actually went wrong. Those execution failures appear in the trace, which is why manual review at the trace level remains necessary for agent evaluation.
Why is manual review important for AI agents in production?
AI agents can produce the right final answer while still making bad decisions during execution. An agent might choose the wrong tool, pass incorrect parameters, repeat unnecessary steps, or take a slower path that increases cost and latency. Output-level scoring often misses execution failures such as incorrect tool use, invalid arguments, and redundant loops. Braintrust provides reviewers with timeline and thread views that show tool calls, model outputs, and nested steps, without requiring them to read raw logs.
What is the best tool for manual review of AI agent traces?
Braintrust is the strongest option for teams that want manual review connected to their eval and deployment workflow. Braintrust combines trace-level inspection, span-level human feedback, review queue management with assignment and tracking, one-click trace-to-dataset conversion, and CI/CD quality gates on a single platform.
How do you start a manual review for AI agent traces?
Start by instrumenting the agent to send traces to an observability platform. Pick five to ten production traces where the agent produced an incorrect or unexpected output, and review each trace step by step, tagging the span that caused the failure. Those first-reviewed traces form the foundation of an eval dataset that grows with each review session. Braintrust's free tier includes tracing, scoring, and dataset management, so teams can start building that dataset without upfront cost.
How do you connect manual review findings to automated evals?
Automated scorers handle volume across production traffic, while human review handles calibration and edge cases where automated scoring is unreliable. Reviewed failures feed into eval datasets that run on every code change, so the two layers reinforce each other over time. Braintrust's trace-to-dataset pipeline and GitHub Action connect the two layers directly: a failure flagged by a reviewer on Monday can block a risky merge on Wednesday.
Can manual review scale for high-traffic AI agents?
Manual review does not need to cover every trace. A scalable workflow scores production traffic automatically and reserves human review for flagged traces, high-stakes actions, and a small random sample. As teams turn reviewed failures into eval cases, automated scorers improve because teams compare automated scores against human judgment on real failures. Braintrust supports high-volume review with continuous production scoring and fast trace retrieval.