Evals are a team sport: How we built Loop
Loop is an AI assistant built into Braintrust that helps with evaluation workflows. It can surface insights from production data, optimize prompts and datasets, generate scorers, and create custom charts. It makes AI observability and evals more accessible to non-engineers while still being useful for technical work.
When we launched Loop, the early metrics looked promising, but we also noticed something concerning: the "Optimize this prompt" workflow had a low acceptance rate. Users were abandoning conversations midstream.
I'm Mengying, on the growth team, and I worked with David, a design engineer, to figure out what was going wrong. To do this, we needed to understand what was actually happening in user interactions.
Step 1: Human review to identify patterns
Rather than guess at the problem, I started manually reviewing logs of user interactions with Loop. I scored them based on observable user satisfaction signals.
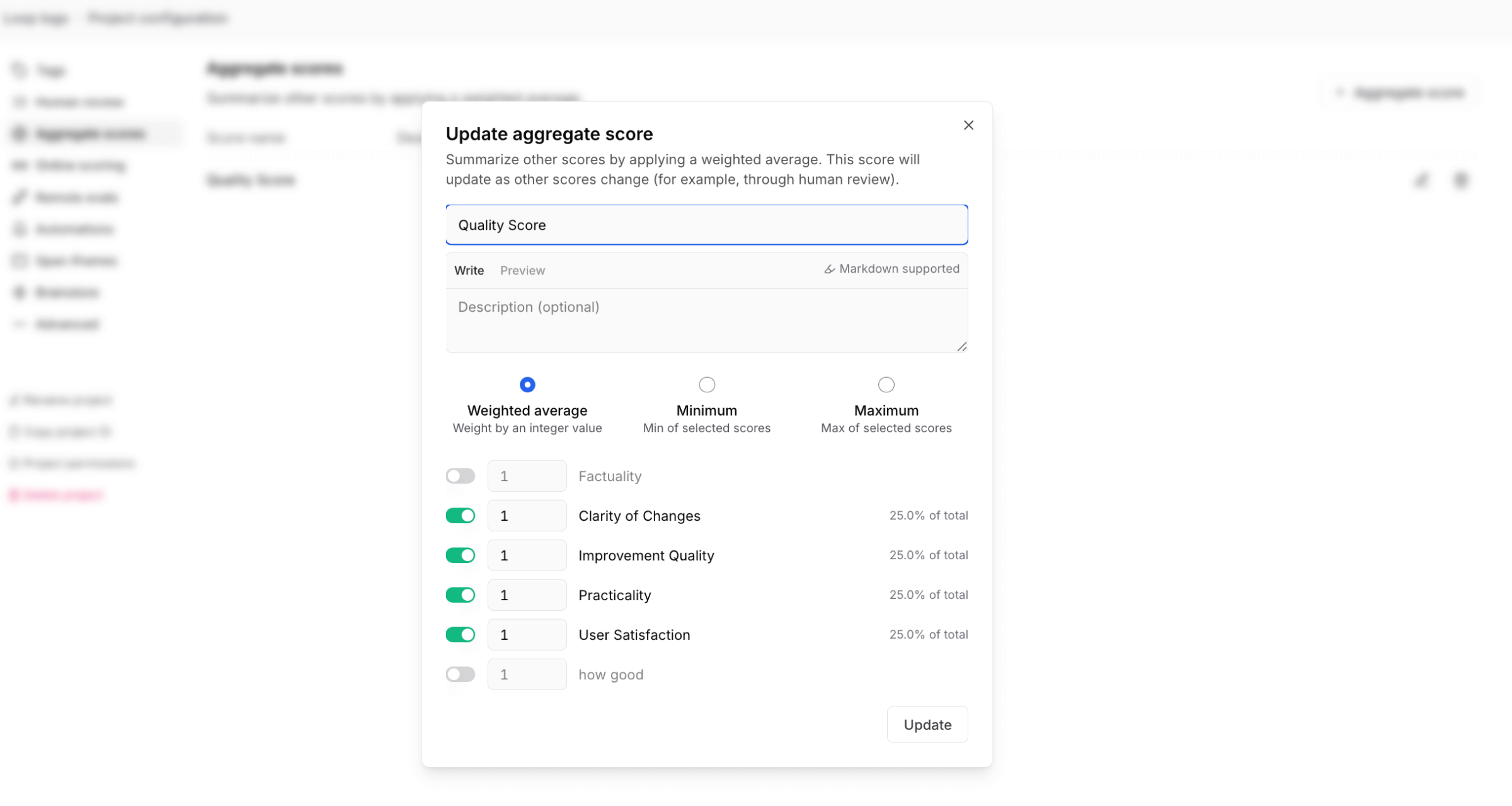
The process needed more than a simple "good" or "bad" rating. After some experimentation, I developed a 4-dimensional scoring framework:
- Improvement Quality (1-5): How much better is the optimized prompt than the original?
- Practicality (1-5): Can real users implement this in their workflow?
- Clarity of Changes (1-5): Do users understand what changed and why?
- User Satisfaction (1-5): Based on user reactions, how happy were they?

I combined these dimensions into a single quality score to understand Loop's overall performance:
For each conversation, I would:
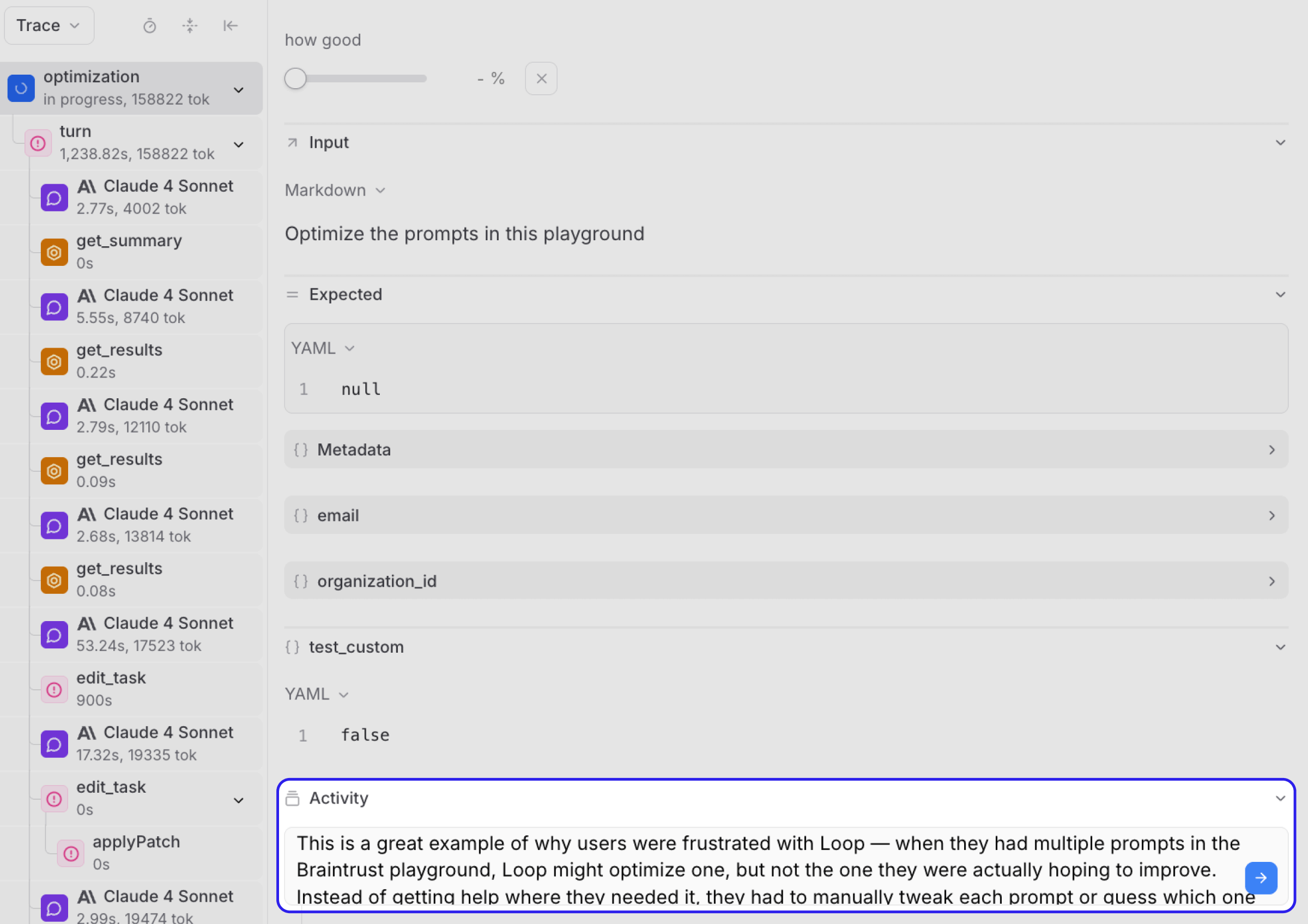
- Read the full interaction to understand context and user intent. The thread view helped me see the exact conversation without parsing complicated trace trees.

-
Score each dimension separately based on what I saw in the conversation.
-
Add notes about specific issues or patterns.
Here's an example:
Conversation #1247 (Low aggregate score: 2.1)
- Improvement Quality: 4/5 (Loop's optimization was technically solid)
- Practicality: 3/5 (Changes were implementable)
- Clarity of Changes: 1/5 (User couldn't tell what was different)
- User Satisfaction: 1/5 (User said "This isn't what I asked for")
I could view conversations chronologically, add custom fields for each score dimension, and filter by aggregate scores to focus on the worst interactions.
For logs where I wasn't sure how to score, I'd assign them to David for technical review. This helped catch nuances I might miss.
Step 2: Using Loop to narrow down the focus area
After reviewing hundreds of conversations, a pattern emerged. I asked Loop for a dataset of the logs with the lowest scores.
The pattern was ironic: "Optimize this prompt" (Loop's most popular default option) consistently had the lowest quality scores.
Looking closer, I found the issue. When users had multiple prompts in their playground, Loop would optimize all of them by default. But usually users only wanted to optimize one specific prompt.
A typical failed interaction looked like this:
User: "Optimize this prompt"
Loop: "I've optimized all your 3 prompts for better clarity and effectiveness!"
User: "Wait, that's not the prompt I was working on..."
Loop: "I can help you with prompt optimization. What would you like me to improve?"
User: [abandons conversation]
I asked Loop to narrow it down further: "Can you identify which specific scenarios are causing the lowest satisfaction scores in the 'Optimize this prompt' workflow?"
Loop analyzed the tagged conversations and found the key variable: the number of prompts in the user's playground. Conversations with 1 prompt averaged 4.2. Conversations with 2+ prompts averaged 2.1.
Step 3: Creating a targeted dataset
Once we identified the pattern, I tagged all low-scoring conversations that involved multiple prompts with a new label: multiple-prompt.
The tagged dataset became our foundation for testing solutions. Each conversation included the dialogue plus metadata from the playground (specifically how many prompts the user had when they made the request).
David added technical context based on his review. For conversations where Loop's behavior was ambiguous, he annotated which prompt the user likely intended to optimize based on their recent activity.
Having both perspectives made the dataset more useful than if either of us had worked alone.
Step 4: Testing solutions in the playground
With the dataset ready, we moved to the playground to test solutions. We needed Loop to consider which prompt the user wanted to optimize when multiple prompts were present.
To test Loop without recreating everything, we used remote evals. This lets you call the production Loop endpoint and run evaluations locally.
We put Loop's existing system prompt into the base task and ran the evaluation. From the trace view, we confirmed Loop was seeing all 3 tasks but automatically optimizing the first one without asking.
Step 5: Using Loop to improve Loop
Here's where the story gets meta: we used Loop (running in Braintrust) to optimize Loop's own prompts. In the playground, we created a new session and fed Loop the dataset of problematic conversations, complete with playground metadata.
We entered the following into Loop:
I'd like to optimize the behavior of the base task prompt. If Loop detects multiple tasks in a playground, it should automatically optimize the comparison task rather than defaulting to the first base task. If the user rejects the execution, Loop should then prompt the user with a choice: 'Which task would you like to optimize first?'
Loop's response included specific prompt modifications that would implement this behavior change.
After adding Loop's suggested modifications, we ran the evaluation again. Loop now correctly analyzed the 2nd prompt instead of blindly defaulting to the first one. Progress!
Step 6: Iterative prompt development
Using prompt versioning, we refined Loop's behavior iteratively. Each iteration showed improvements on the multiple-prompt dataset.
We kept tweaking to ensure Loop gave clear instructions. For example, we asked Loop to:
"Give clear indication about which task's prompt you are optimizing."
The new version identified which task it was working on:
I successfully analyzed and began optimizing your movie identification prompt system. Here's what I accomplished:
Optimization Started
I successfully optimized task1 with a new prompt...
We tested each iteration against the tagged dataset in the playground. The side-by-side comparison made it easy to see how different versions handled the same scenarios.
Step 7: Sharing results
Before deploying, I wanted to show the team what we found. I created a chart showing:
- Acceptance rate by number of prompts in playground (before and after)
- Average satisfaction score by workflow type
- Distribution of abandonment points in conversations
The chart made it easier to share findings. Instead of describing the problem, I could show the data. Non-technical teammates could see the impact without interpreting raw scores.
Step 8: Deployment and validation
Once we were confident in our offline evaluations, David pushed the improved prompt to production.
The new conversation pattern looked like this:
User: "Optimize this prompt"
Loop: "I see you have 3 prompts in your playground. Which one would you like me to optimize?"
User: "The second one, about email generation"
Loop: "Perfect! Let me optimize your email generation prompt..."
User: "This is exactly what I needed!"
Step 9: Measuring success
The results were immediate and measurable. I continued reviewing conversations using the same tagging and scoring system to track improvement:
- Human review scores: Average conversation score jumped from 2.1 to 4.3 for "optimize this prompt" requests with multiple prompts
- Cost efficiency: Reduced unnecessary compute cycles by targeting specific prompts rather than optimizing all prompts by default
We had metadata around cost, cache hit rate, and tokens on every record, which made it easy to quantify the savings.
What we learned
The main thing we learned is that fixing AI products requires both technical and non-technical perspectives. I could identify patterns in user behavior that David might have missed, and he could spot technical issues I wouldn't catch.
The workflow that worked for us:
- Manual review to identify patterns (me)
- Technical analysis to understand root causes (David)
- Dataset creation combining both perspectives
- Testing solutions in the playground
- Charts to communicate findings to the team
If you're debugging your own AI product
Here's what worked for us:
- Start with manual review. Automated metrics won't tell you everything.
- Tag conversations to create focused datasets.
- Use Loop to narrow down patterns in large datasets.
- Test solutions in the playground.
- Create charts to communicate findings.
- Conduct offline experiments and deploy with confidence.
- Keep measuring with the same methods that found the original issue.
When your AI product isn't working as expected, good observability helps you figure out why. Fixing it usually requires teamwork - and maybe some help from AI.
Ready to start your own cross-functional evaluation project? Try Braintrust to see how Loop can help your team query, analyze, and improve AI applications faster.