Five hard-learned lessons about AI evals
The team at Braintrust spends a lot of time deep in evaluation data, helping teams of all sizes ship reliable LLM‑powered products. We run the platform that powers those evals and observability workflows, so we see the successes and the failures up close. On an average day, our customers run ≈ 13 evals per org, and the most advanced teams push 3,000+ evals daily while spending hours poring over trace logs. All that usage has taught us five tough lessons. If you’re searching for the most comprehensive LLM evaluation tools in the market today, or an LLM evaluation platform with detailed trace logs for agent workflows, these lessons will show you what “good” really looks like, and how we built Braintrust to get you there.
1: Effective evals speak for themselves
Here’s how I know an org’s eval loop is truly adding value:
Rapid model adoption
When a new model drops, your evals should let you ship it to prod within 24 hours. Notion’s AI team does exactly that, with every major model release showing up in the product the very next day.
User‑feedback input
A user files a bug → you turn that example into an eval case in minutes. That feedback‑to‑eval path ensures issues never slip through the cracks.
Playing offense
Evals aren’t just regression tests. We use them to validate brand‑new features pre‑ship, so we already know success rates before users ever touch the product.
If those three boxes aren’t checked yet, just keep tightening the loop until the value is undeniable.
2: Great evals must be engineered
Data engineering
Synthetic datasets alone won’t cut it. Real users will always do something you didn’t anticipate, so we continuously add production traces back into our eval datasets.
Custom scoring
Our open‑source autoevals library ships with ready‑made metrics, but every serious team eventually writes its own scorers. Think of a scorer as the PRD for your AI’s behavior: if you rely on a generic metric, you’re shipping someone else’s requirements, not yours.
3: Context beats prompts
Modern agents spend far more tokens on tool calls and outputs than on the system prompt itself. That means:
-
Design tools for the model, not just your API. Sometimes we create entirely new “LLM‑friendly” endpoints because the original API shape confuses the model.
-
Optimize output formats. Switching one internal tool’s output from
JSONtoYAMLliterally doubled its success rate.YAMLwas shorter, easier for the model to parse, and cheaper in tokens.
If you haven’t audited your agent’s context lately, do it. Prompt tweaks are great, but the surrounding context often moves the needle more.
4: Be ready for new models to change everything
We manage a set of “aspirational” evals, which are tests that current models score 10 % on. Every time a new model lands, we swap it in via the Braintrust Proxy (with zero code changes) and rerun the suite. When Claude 4 Sonnet crossed our success threshold last month, we shipped a brand‑new feature two weeks later.
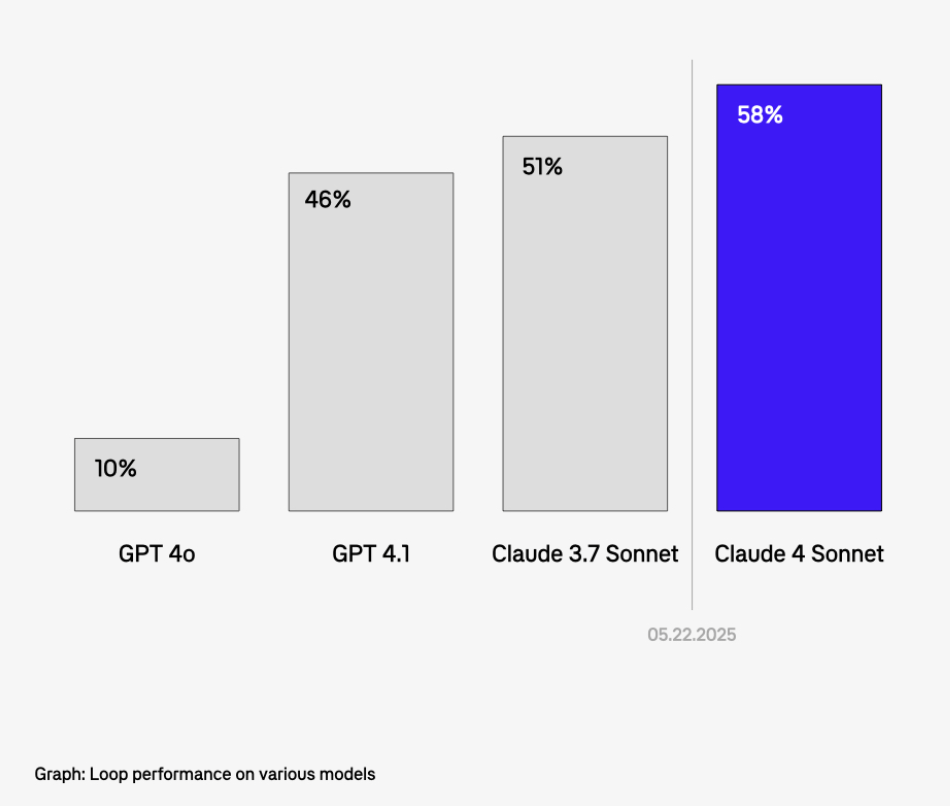
That turnaround’s only possible because:
-
The evals were already written.
-
The infra made model swapping trivial.
-
The culture said, “If a new model enables something, drop everything and ship.”
5: Optimize the whole loop, not just the prompt
An eval = data + task (prompt/agent/tools) + scoring. We ran an internal experiment where we asked an LLM to:
A) optimize only the prompt, vs.
B) optimize the entire eval (prompt + data + scorers).
Approach B crushed A, turning an unviable feature into a viable one. Moral: don’t get tunnel vision. If the score is inflated, tighten the metric. If the dataset is stale, enrich it. Holistic tuning compounds.
Meet Loop: your eval copilot
To bake these lessons into the product, we launched Loop, the first AI agent for evals.
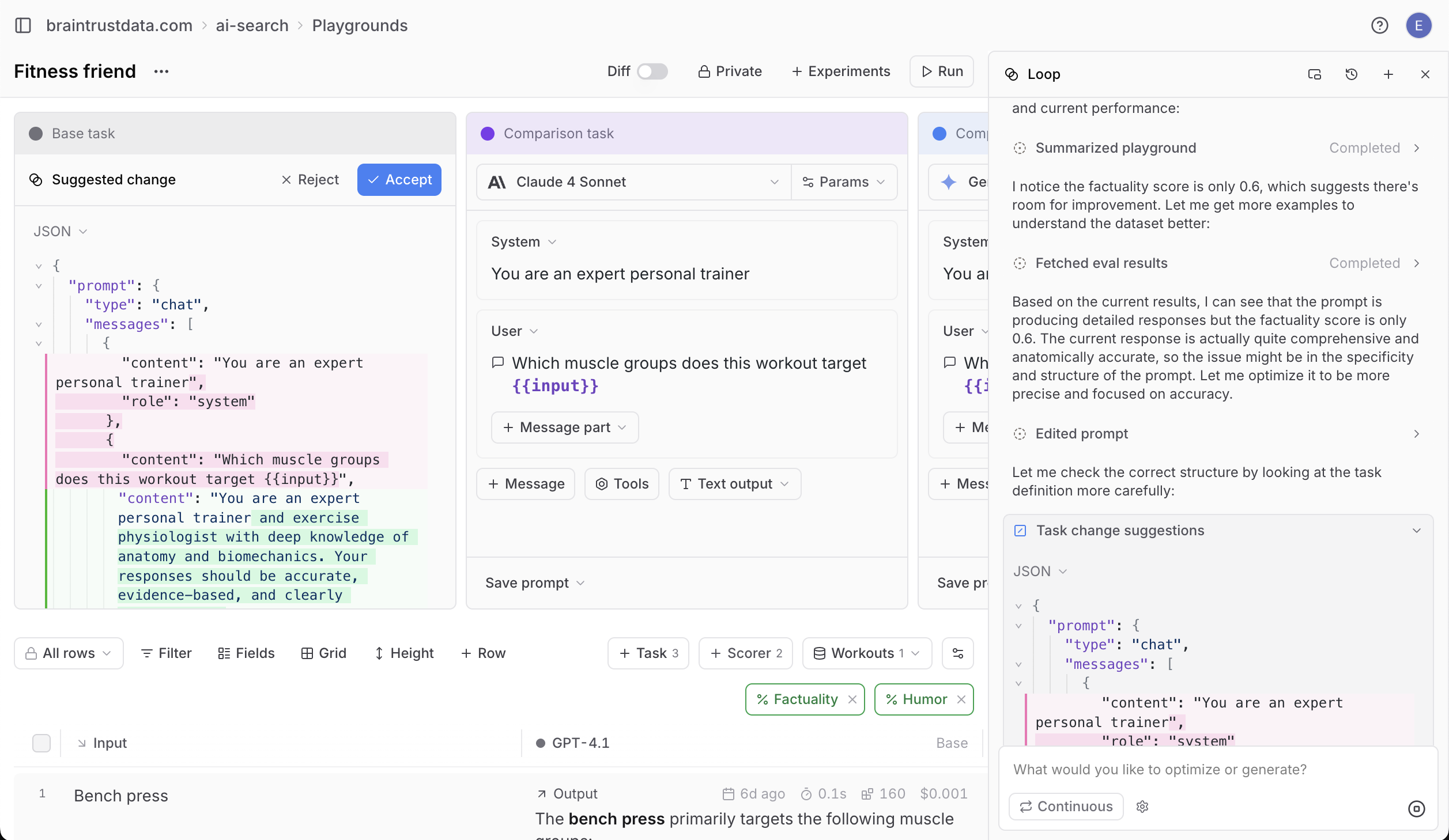
Loop lives in the playground and auto‑improves your evals:
- “Optimize this prompt.”
- “What data am I missing?”
- “Why is my score low?”
- “Write me a harsher scorer.”
Behind the scenes, Loop uses Claude 4 Sonnet (or any model you select) to propose and execute changes.
Summing it up
-
Evals that matter enable 24‑hour model swaps, feed on real user bugs, and validate features pre‑launch.
-
Engineer your data pipelines and scorers with the same rigor as production code.
-
Context (tools, formats, flows) often matters more than the prompt itself.
-
New models can upend your roadmap. Stay ready with continuous evals and a provider‑agnostic proxy.
-
Optimize the full loop (data + prompt + scorers), not just single lines of text.
We built Braintrust so you can spend less time doing all of this and more time shipping features your users love. Sign up for a free account today, or reach out to learn more about getting your team on Braintrust.