Benchmarking GLM-5.2 vs Opus 4.8 for real-world long-context retrieval
For an LLM to be useful for coding agents, it must be able to accurately retrieve information from long context. While Anthropic's Opus 4.8 has led industry benchmarks in this regard for some time, newer models are catching up, in some cases coming close to matching performance. Specifically, GLM-5.2 from Z.ai has shown that it can perform well as a coding agent that manages long context retrieval. And because it is open-source, it can be used to support native inference for teams building agent-based products. That was the situation we found ourselves in at Braintrust while building our product Topics with our inference partners at Baseten.
We built a Braintrust-native eval in collaboration with Baseten to test whether GLM-5.2 can preserve exact long-context retrieval under production serving constraints. To probe this long-context behavior we built AST-derived retrieval tasks over the CPython standard library at roughly 25k and 50k tokens. Because each question is mechanically extracted from source-code structure, the eval tests exact retrieval against deterministic ground truth rather than subjective code understanding.
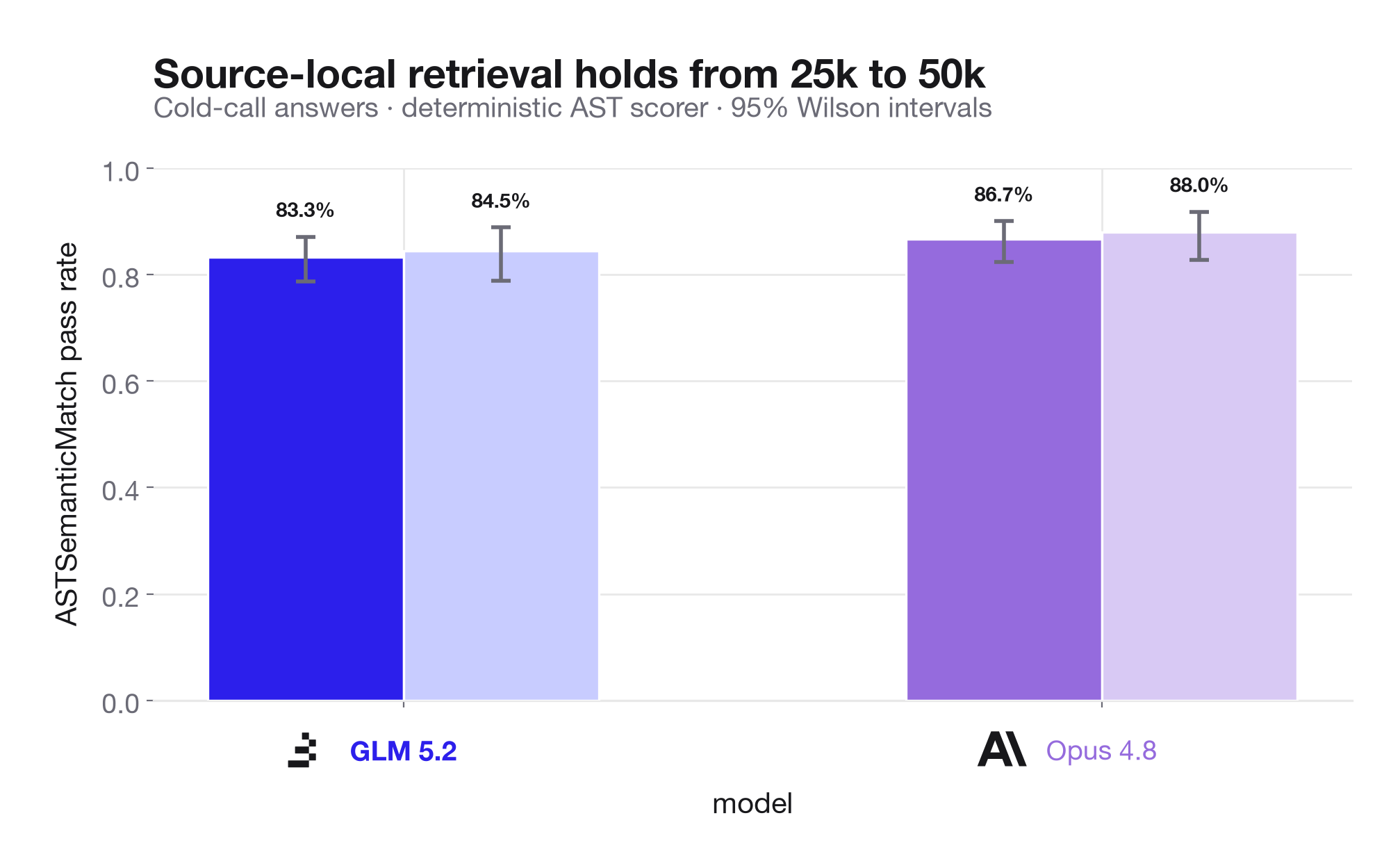
Our benchmark shows that GLM-5.2 is slightly behind Opus 4.8 on retrieval, while average provider cost per trace is about 76-78% lower across the two context tiers. On a perturbation control slice, GLM is about 86% cheaper per correct answer. In a historical baseline pass, GLM-5.2 also outperformed Opus 4.6 and Sonnet 4.6 on exact AST-based retrieval at both 25K and 50K context. For many applications, this makes GLM-5.2 the more efficient choice.
This helped us decide whether we could use GLM-5.2 in our own product, and today it is critical to the workflow of Topics, Braintrust's clustering and analysis feature for automatically grouping traces, feedback, and eval results into meaningful themes so teams can understand patterns in model behavior at scale.
We're sharing the results of the eval along with a full breakdown of our eval methodology so others can build on what we learned. The resulting benchmark goes beyond a simple model leaderboard and makes comparisons regarding cost and performance that have real-world implications.
What we found
We found that Opus 4.8 is more accurate, but only modestly, especially when looking at relative costs. Opus 4.8 leads GLM-5.2 by about 3.5 points on exact long-context retrieval at both 25K and 50K tokens, but the cost gap is much larger. At the same context sizes, Opus costs about 4.1x to 4.5x more per trace.
If two models are close on retrieval quality, how much should you pay for the last few points of performance?
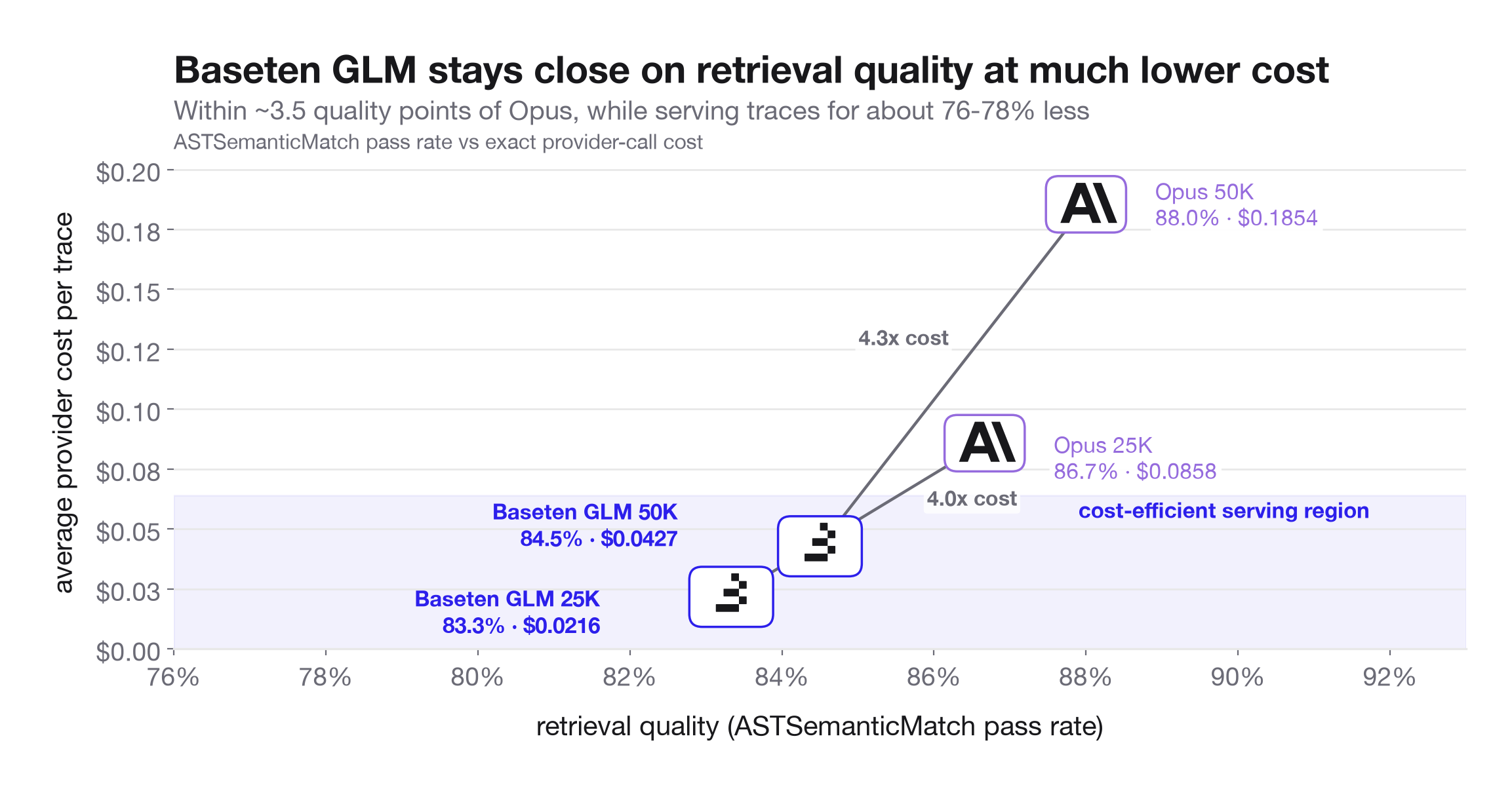
For this eval, GLM-5.2 is tested as the option for maximizing cost efficiency. At 25K tokens, GLM scored 83.3% at $0.0208 per trace while Opus scored 86.7% at $0.0856 per trace. At 50K tokens, GLM scored 84.5% at $0.0415 per trace while Opus scored 88.0% at $0.1849 per trace.
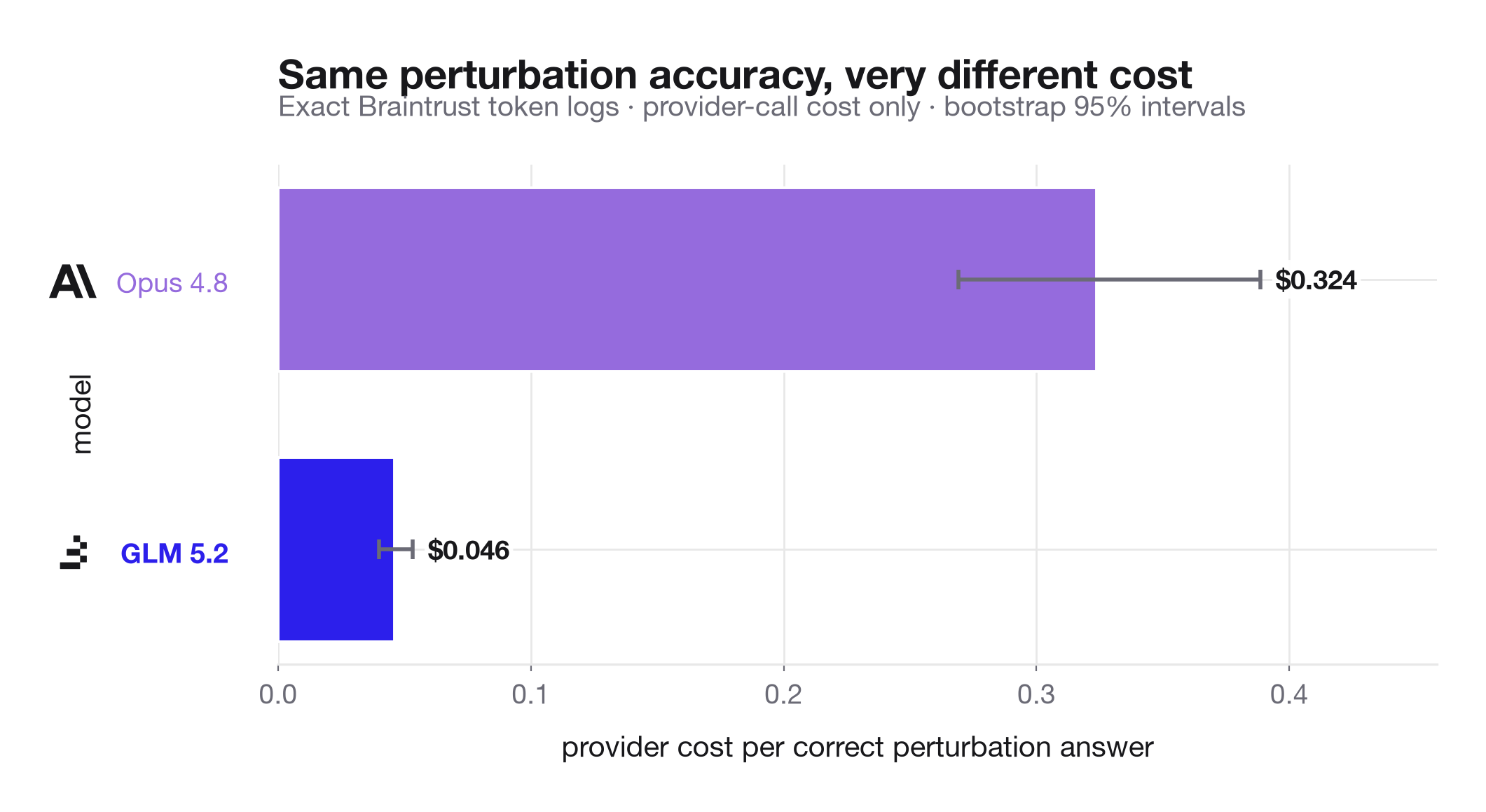
GLM gives up a small amount of retrieval accuracy, but average provider cost per trace is about 76-78% lower across the two context tiers. On the perturbation control slice, where both models answered the same number of rows correctly, GLM was about 86% cheaper per correct answer: $0.046 versus $0.324.
| Metric | GLM-5.2 | Opus 4.8 |
|---|---|---|
| Retrieval (25K) | 83.3% | 86.7% |
| Retrieval (50K) | 84.5% | 88.0% |
| Avg cost/trace (25K) | $0.0208 | $0.0856 |
| Avg cost/trace (50K) | $0.0415 | $0.1849 |
| Perturbation cost/correct | $0.046 | $0.324 |
For high-volume agent workflows, retry-tolerant systems, or workloads with many parallel long-context reads, that cost delta can matter more than the small accuracy delta. On the primary deterministic scorer, Opus leads by 3.4 points at 25K and 3.5 points at 50K. GLM-5.2's retrieval score is also effectively flat as context grows from 25K to 50K, which is the result we most wanted to see from a sparse-attention long-context model. There is effectively no external retrieval degradation over the tested range.
The contrast becomes even clearer in our perturbation tests where we intentionally modified symbols within the provided context, which should expose any model that relies on memorized associations rather than true contextual reasoning. Both models achieved 83 out of 100 correct answers, but the cost efficiency gap is substantial: GLM delivered each correct perturbation answer at roughly $0.046 compared to $0.324 for Opus. Importantly, the errors were not due to difficulty handling long contexts. Instead, they concentrated on local source disambiguation issues, such as distinguishing between repeated method names in nearby classes. This suggests the core challenge is precise reasoning within context, not context length itself.
Latency is the primary caveat, but it is also where Baseten's product story really matters. In our tests, GLM-5.2 served through Baseten delivered the fastest single first-token response we observed at 778 ms, and external benchmarks likewise highlight strong throughput on this stack. At the same time, performance variability emerges under load. In a separate 100k-token latency run on a shared model API endpoint, the latency distribution showed a heavier tail: 36 out of 300 requests exceeded 10 seconds to first token, while Opus remained more consistent. This suggests that GLM-5.2 is not inherently slow, but more sensitive to tail latency under contention.
In practice, that sensitivity makes the inference setup itself a first-class product decision rather than an afterthought. With most hosted frontier APIs, you get whatever multi-tenant serving configuration the provider gives you, along with its noisy-neighbor effects and tail behavior. By contrast, working with an inference platform like Baseten gives you real control over those knobs. In our collaboration, we found that deployment-level choices on Baseten, such as autoscaling thresholds, replica capacity, endpoint isolation, regional configuration, and context/timeout handling, were important levers for reducing latency spikes and improving predictability in long-context production workloads. The real tradeoff, then, is not fixed model speed, but how effectively your serving configuration is designed with Baseten for your target use case and context needs.
What the eval means
This eval isn't a broad coding benchmark with simple leaderboard results. Existing long-context retrieval benchmarks such as LONG2RAG test whether models can recover information across long documents, while architecture explainers for DeepSeek Sparse Attention describe how GLM-5.x-style sparse attention reduces long-context attention cost by selecting a learned subset of prior tokens. Our eval asks whether that kind of long-context retrieval remains accurate when served as an observable production workload.
We put GLM-5.2 served through Baseten head to head with Claude Opus 4.8 in a production-relevant stress test: can GLM-5.2 read source-local facts from large code contexts while staying fast and observable? It probes both models with tightly scoped, Abstract Syntax Tree (AST) derived questions over the CPython standard library at roughly 25k tokens and 50k tokens. It isolates the first leg of the GLM-5.2 agentic loop story, which captures whether long-context memory remains accurate under serving pressure.
The "derived" part means the questions weren't written by hand or generated with an LLM. They were mechanically extracted from the tree structure itself. This makes the ground truth machine-checkable, and means that the correct answer is a deterministic property of the source code, not an interpretation of it.
Impact on production use-cases
We built this eval to stress test a narrower production claim: when the answer is present in a long prompt, can the model reliably retrieve it, and can the serving stack expose the latency and caching behavior around that retrieval? For GLM-5.2 specifically, the stress test maps onto the DeepSeek Sparse Attention idea. If the model reduces long-context attention cost by selecting a content-dependent subset of relevant prior tokens rather than attending densely over the whole window, the eval asks whether that sparse selection still preserves retrieval fidelity on exact source-local facts.
This stress test matters especially for enterprise production systems where long-context retrieval is load-bearing:
- Code intelligence and repository Q&A. Developers querying AI assistants over large, live codebases, asking where a function is defined, which services depend on a module, or whether a proposed change breaks a contract defined elsewhere. These tasks routinely require 50k-500k tokens of cross-file context. Tools with limited context miss correctness issues that full-context retrieval catches. Augment Code's blind study on a 3.6M-line Elasticsearch repository found a +14.8 correctness advantage for full-context retrieval over file-limited approaches.
- Financial document analysis. Analysts and compliance officers extracting specific figures and risk disclosures from SEC filings. These are usually 50k-250k token documents. GPT-4 Turbo with retrieval failed or hallucinated on 81% of FinanceBench questions, while the Fin-RATE benchmark found a 14-19% accuracy drop when moving from single-document to cross-entity and temporal analysis, which is exactly the kind of comparison analysts rely on.
- Enterprise knowledge base and internal documentation. DevOps engineers following AI-generated runbook instructions, compliance staff acting on policy answers, and support teams resolving escalations. All these depend on exact retrieval from documents the enterprise controls, and are token-intensive. Chroma's 2025 context analysis tested 18 frontier models and found that all of them exhibited performance degradation as context grew, and that "effective context" varied significantly from advertised context limits.
- Medical record summarization. AI tools reviewing patient EHRs that must surface specific diagnoses, medications, and lab values from longitudinal records. These tasks easily exceed 50k tokens for patients with chronic conditions. A Nature study of 147 AI-generated chart summaries found 46 instances of missing information versus only 5 hallucinations, and concluded that errors of omission present a larger threat than errors of commission. For example, one severity substitution (moderate -> severe aortic stenosis) would have changed clinical management.
In all of these cases, the model is acting as a precise retrieval layer over a document the enterprise trusts as ground truth. That is what our eval tests. Does the model actually read the window, or is it interpolating from training weights? These are production questions that determine whether a long-context serving system is safe to deploy in any of these workloads.
You can read a technical breakdown of the eval with more detail on methodology, hypotheses, and findings. Stay tuned for more about our work with Baseten, and how we built Topics with GLM-5.2 as the LLM providing native inference in Braintrust.
Thank you to Alex Ker at Baseten for collaborating with us on this benchmark.
Trace everything
Create an account or use agent setup to start building today.