What are AI hallucination evaluations? Metrics and methods that work in 2026
Hallucination evaluation measures whether an AI output is factually wrong, unsupported by retrieved sources, or inconsistent with prior context across the inputs your application actually handles. A useful score has to match the failure mode that users could see in production.
A reliable setup combines the right metric, scoring method, and ground-truth source for the task, whether the application relies on retrieved documents, source text, a curated dataset, or repeated generations with no reference answer.
A single LLM judge returning one score leaves blind spots. Better evaluation uses multiple checks across development, regression testing, and production monitoring. Braintrust lets teams combine built-in scorers, custom scorers, and human review into a single workflow, so hallucination checks can move from measurement to release control without a separate evaluation stack.
If you're evaluating tools to detect, review, and reduce hallucinations in production, read our guide to the best hallucination detection tools.
What hallucination means in evaluation
For evaluation, a hallucination falls into three failure types: an output can be factually wrong against the real world, unsupported by the documents retrieved for the request, or inconsistent with earlier context in the same conversation. A scorer tuned for only one failure type can miss the others.
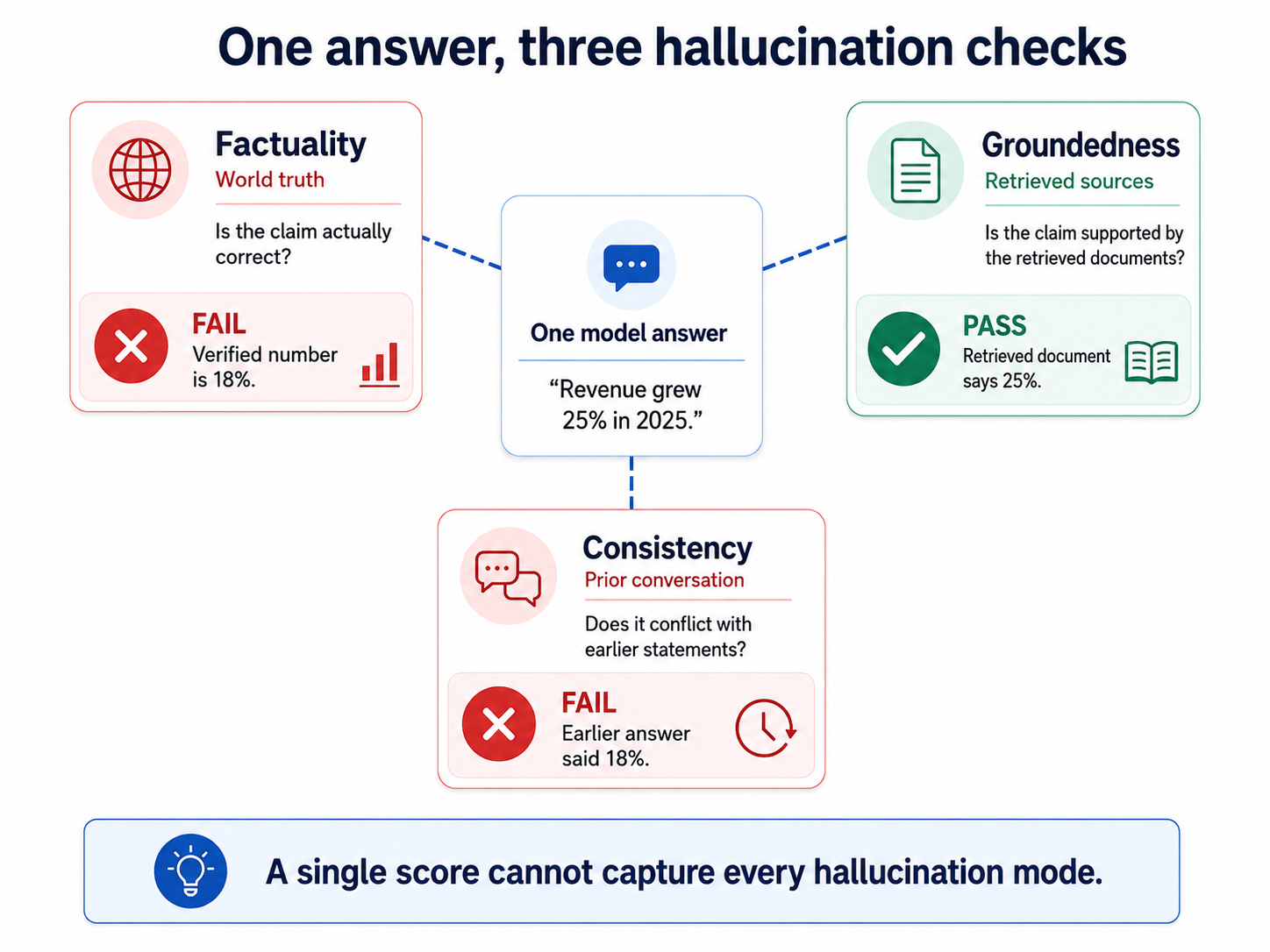
A single model answer can pass a groundedness check while failing factuality or consistency checks, so hallucination evaluation requires separate checks for each failure mode.
Production risk increases when the evaluation metric does not align with the failures users may encounter. A RAG assistant that checks only for groundedness can still return an invented statistic, because groundedness compares the answer to retrieved text and does not verify the claim against external facts. Picking the right metric is the first decision in a hallucination evaluation setup, and stronger setups score multiple properties together.
Hallucination evaluation metrics
Each metric scores a different property. Choosing the metric first defines which hallucination failures your evaluation can catch.
Groundedness measures whether the answer is supported by the chunks the system retrieved. It fits RAG, where retrieved documents define the context the model should use. When a claim has no support in those chunks, groundedness flags the answer even if the claim is true outside the retrieval set. For retrieval, generation, and end-to-end RAG scoring, see our guide to RAG evaluation metrics.
Faithfulness asks whether a summary or generated answer stays true to the source text it was given. It overlaps with groundedness, and Braintrust scores both with closely related logic, but the evaluation target differs. Groundedness checks generated answers against retrieved passages. Faithfulness checks the condensed or transformed output against the full source text.
Factuality checks whether a claim is correct against general world knowledge or a verified answer. It fits open-domain question answering, where no retrieved passage or source document defines the answer. Factuality catches invented statistics or claims that may appear supported by weak context but fail against external truth.
Consistency looks at whether repeated generations for the same prompt agree with each other. It fits free-form generation, where there may be no reference answer. Wide disagreement across samples signals that the model is guessing or producing unstable answers.
Hallucination evaluation methods
Once you know which property to score, the method decides how the score is produced, how expensive it is to run, and how much calibration it needs.
LLM-as-a-judge prompts a strong model to grade the output against a rubric or reference. It is quick to set up, adapts to new tasks through prompt edits, and handles subjective criteria that fixed rules cannot express. The judge is still a language model, so it can return the wrong verdict. Calibrate judge scores against human labels before using them as release signals. For setup details, see our explainer on LLM-as-a-judge.
Fine-tuned models are smaller models trained to spot hallucinations for specific tasks. Patronus Lynx is an open-source model built on Llama 3 that checks whether a RAG answer stays faithful to its source document. Galileo Luna is a proprietary encoder that flags unsupported spans inside an answer and runs fast enough for real-time use. Both can be faster and cheaper at runtime than a large judge, but each model is constrained by its training scope, and proprietary scoring keeps you tied to one vendor's model.
Consistency sampling and semantic entropy involve running the model several times and measuring how much the answers vary in meaning. Semantic entropy groups answers that mean the same thing and measures their spread, helping catch arbitrary or made-up answers when no reference exists. The method works well for open-ended prompts, but repeated sampling increases token cost.
Human review puts a person in the loop to label outputs as supported or unsupported. Human labels serve as the ground truth for calibrating automated methods and remain the strongest quality signal in ambiguous cases. Human review does not scale to every production request, so it is best used for dataset building, judge calibration, and audits of live outputs. Our roundup of human-in-the-loop evaluation platforms covers the tooling.
For day-to-day production scoring, an LLM judge is usually the practical default because prompt changes make it adaptable across tasks. A fine-tuned model fits stable, high-volume RAG workloads where latency and cost are tighter constraints. Semantic entropy is well-suited to open-ended prompts with no reference answer, while human review keeps automated scoring aligned with labeled examples and real user risk.
Ground-truth sources for hallucination evaluation
After choosing a metric and scoring method, select the reference source your evaluation will compare against. The ground-truth source often determines which hallucination metrics and methods are practical for the task.
Gold dataset: A set of questions paired with human-verified answers. A gold dataset yields the cleanest signal because the expected answer is already known, making it useful for factuality scoring in open-domain tasks. The main cost is upkeep because the dataset must expand and remain accurate as the product evolves.
Retrieved context as a proxy: The documents your RAG system retrieved become the reference for judging the answer. Retrieved context supports groundedness because the scorer checks whether the answer stays inside the retrieved text. The setup is efficient because the context already sits in the trace and does not require a separate labeling workflow.
No ground truth: Free-form generation often has no single correct answer to compare against. Consistency sampling and semantic entropy fit these cases because they measure agreement across repeated model outputs without requiring an external answer key.
Choose the metric, method, and ground truth by task
The metric, method, and ground-truth source should match the task you are evaluating. Use the table below to choose the combination that fits the output, reference material, and review workflow.
| Task | Metric | Method | Ground-truth source |
|---|---|---|---|
| RAG question answering | Groundedness and faithfulness | Fine-tuned model or LLM judge | Retrieved context |
| Summarization | Faithfulness | LLM judge | Source document |
| Free-form generation | Consistency | Semantic entropy or sampling | None |
| Multi-step agent reasoning | Faithfulness to tool outputs, plus factuality of the final answer | LLM judge, with human review on a sample | Tool outputs as context, gold set for final answers |
How to implement hallucination evaluation in Braintrust
Braintrust integrates hallucination scoring, trace review, human feedback, regression datasets, CI checks, and production monitoring into a single workflow. The same scorers can run during development, before release, and on sampled production traffic, so hallucination evaluation stays tied to the outputs your application actually produces.
Score the common cases with built-in scorers
The autoevals library includes scorers for common evaluation tasks, including factuality checking and semantic comparison, and the full scorer set includes RAG-related checks such as Faithfulness, Context precision, Context recall, and Context relevancy. Use Factuality for open-domain answers, Faithfulness for answers grounded in retrieved or source context, and context scorers to evaluate whether retrieval provides the model with useful material. These checks cover the standard hallucination and RAG quality signals without requiring custom scoring logic.
Add custom scorers for task-specific failures
When a built-in scorer does not match your failure mode, Braintrust supports LLM-as-a-judge scorers and custom code scorers. Use a judge prompt for rubric-based checks, a Python or TypeScript scorer for business rules or deterministic checks, or a custom scoring routine for methods such as semantic entropy. Because built-in scorers, judge-based scorers, and code-based scorers can run in the same evaluation, one run can measure several hallucination risks together.
Use human review to calibrate automated scores
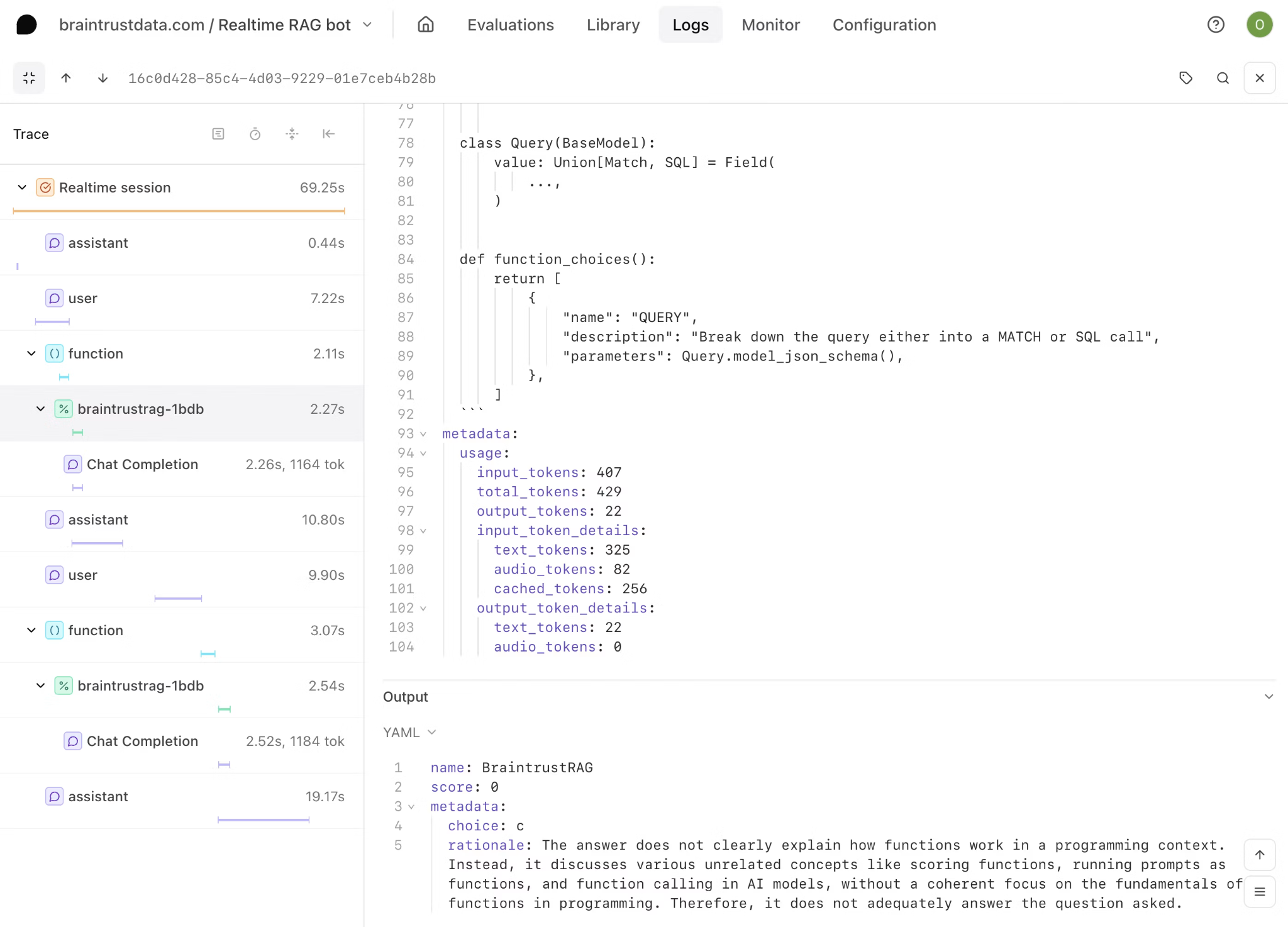
Human review should remain connected to the automated scoring workflow, especially in cases of ambiguous hallucinations. In Braintrust, reviewers can score traces, experiment spans, and dataset rows, then use those labels to validate scorers, create ground truth, and turn edge cases into future test cases. That keeps LLM judges and code-based checks aligned with the reviewed examples rather than relying solely on automated verdicts.
Trace each step to find where a score dropped
Braintrust captures RAG and agent workflows as traces with spans for model calls, retrieval, tool use, scores, inputs, outputs, timing, tokens, and cost. When a faithfulness or groundedness score drops, you can inspect the trace to see which documents were retrieved, what context reached the model, what tool outputs were used, and what the model generated. That turns a low hallucination score into a specific debugging target.
Turn production failures into regression tests
Braintrust datasets are versioned collections of test cases that can be built from production logs, user feedback, manual review, traces, or Loop. When a live answer receives a low hallucination score or gets flagged by a reviewer, you can add the case to a dataset and use it in future experiments. That feedback loop turns each production failure into a repeatable test.
Monitor hallucinations on live traffic
Online scoring evaluates production traces as they are logged and runs asynchronously, so quality monitoring does not sit inside the user-facing request. Use the same hallucination scorers on sampled production traffic to track score trends, surface edge cases, and catch drift as prompts, retrieval data, tools, and models change.
Use Loop to speed up review and dataset work
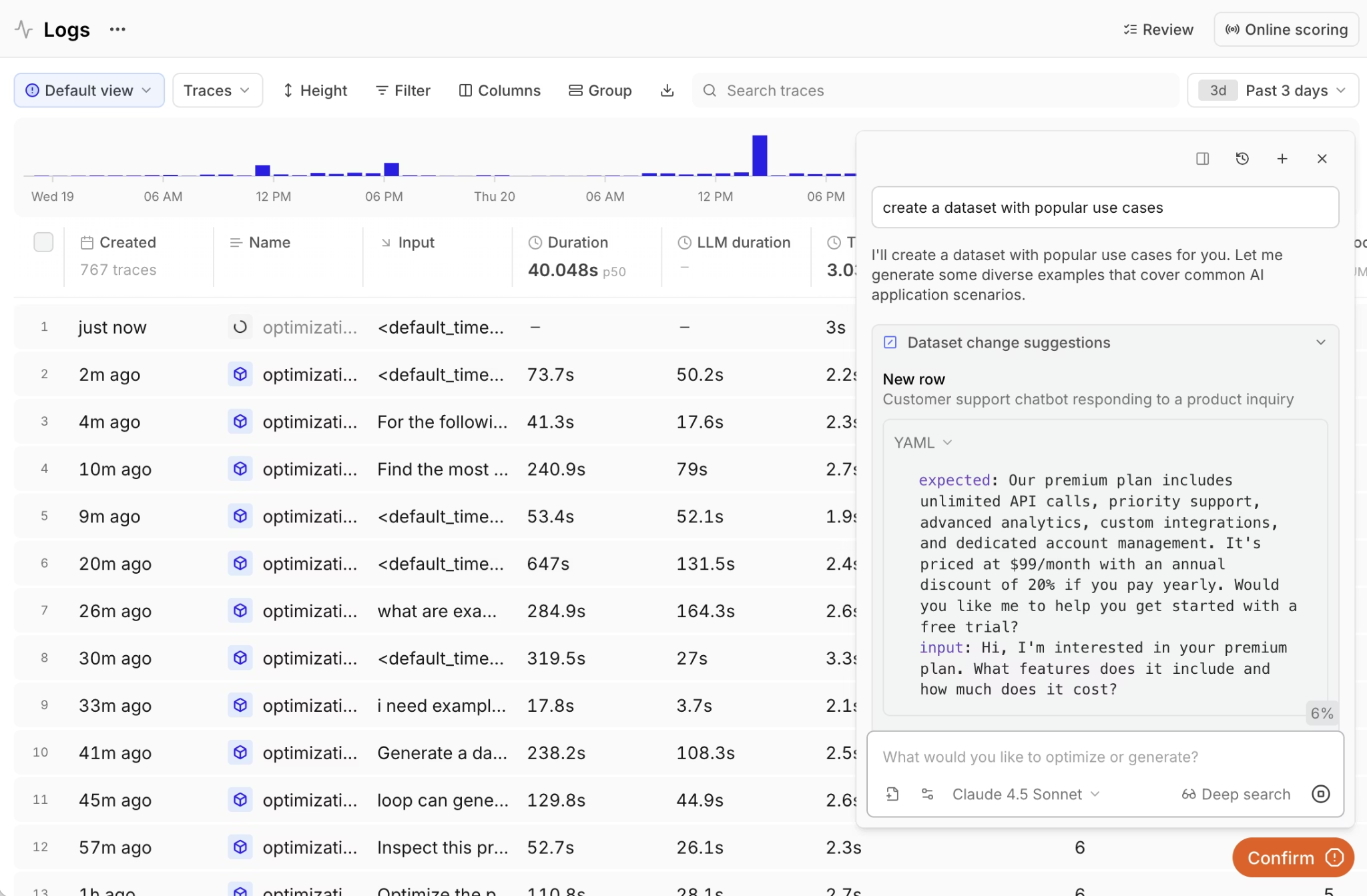
Loop lets you ask natural-language questions over logs and traces, generate SQL filters, find similar traces, build datasets from log patterns, and generate scorers from issues found in production. For hallucination evaluation, that means product and domain experts can help surface low-scoring examples, group related failures, and expand regression coverage without writing queries.
Catch regressions in CI before they merge
Braintrust experiments create immutable evaluation snapshots, and evals can run locally, in the UI, or in CI/CD. The Braintrust GitHub Action can run hallucination evals on pull requests that change prompts, retrieval logic, tools, or model settings, so regressions are caught before a release.
Ready to score hallucinations against your own traffic? Start free with Braintrust's Starter plan →
The Starter plan is free, includes generous usage limits across users, projects, datasets, playgrounds, and experiments, and requires no credit card, so you can start with a focused hallucination evaluation set and expand coverage from there.
FAQs: AI hallucination evaluations metrics and methods (2026)
Is LLM-as-a-judge reliable for hallucination evaluation?
LLM-as-a-judge can be reliable when its scores are calibrated against human labels. The judge is still a language model, so it can return an incorrect verdict, especially on ambiguous outputs or poorly defined rubrics. In Braintrust, human review, built-in scorers, and custom judge prompts can work together, so teams can compare automated scores against reviewed examples before using the judge as a release signal.
What is the difference between hallucination evaluation and hallucination detection?
Hallucination detection flags an individual output as unsupported, incorrect, or risky, often before the response reaches a user. Hallucination evaluation measures failures across many inputs, so teams can see where the system fails, whether changes to prompts or retrieval improve quality, and whether regressions appear over time. Detection protects a single response; evaluation provides the measurement layer teams need to improve the system.
Can I evaluate hallucinations without a gold dataset?
You can evaluate hallucinations without a gold dataset when the task has another usable reference. For RAG, the retrieved context can serve as the reference for groundedness and faithfulness checks. For free-form generation, consistency sampling and semantic entropy can measure whether repeated outputs agree in meaning. A gold dataset is still useful for calibration and regression testing, but it is not required for every hallucination evaluation workflow.
How is RAG hallucination evaluation different from general hallucination evaluation?
RAG hallucination evaluation checks whether the answer is supported by the documents retrieved for the request. General hallucination evaluation checks whether a claim is correct against world knowledge or a verified answer, even when no retrieved source is available. A RAG answer can be grounded in the retrieved context and still be wrong if the retrieval supplies the wrong document, so production systems often need both source-grounding checks and factuality checks.
Does Braintrust have a free tier?
Braintrust offers a free Starter plan that includes generous usage limits for users, projects, datasets, playgrounds, and experiments. Teams can use the free tier to start building hallucination evaluation sets, run scorers, review outputs, and expand coverage as production risks become clearer. Paid plans add higher included usage, longer retention, and additional features for larger production workflows.