Best AI governance platforms for LLM applications (2026): Eval, audit, and enforce
AI governance for LLM applications is about demonstrating that model behavior is evaluated before release, audited after deployment, controlled across users and reviewers, and enforced at runtime when policy violations occur. Runtime guardrails close one failure mode, but regulated teams also need evaluation records, trace-level evidence, role-based access controls, and deployment options that support compliance review.
This guide compares the best AI governance platforms for LLM applications across eval-time scoring, production audit, access control, and runtime enforcement, with a focus on how each tool fits real production workflows. For teams that need evaluation, auditability, RBAC, CI release gates, human review, and hybrid or self-hosted deployment within a single governance workflow, Braintrust is the strongest overall choice.
What is AI governance for LLM applications?
AI governance for LLM applications is the operating discipline for evaluating model outputs, recording production behavior, controlling access to sensitive AI data, and enforcing policies across development and production. It gives teams the evidence for each output, the review process for each release, and the controls that determine whether risky content reaches users.
Classical machine learning governance relies on deterministic model behavior, fixed test sets, and clear ground-truth labels. LLM applications require a different governance process because the same prompt can yield different answers across runs, and many useful outputs cannot be evaluated against a single fixed answer. Governance for LLM applications needs output-level evaluation, trace-level evidence, and a way to turn production failures into reusable test cases.
Many AI governance discussions center on runtime enforcement because real-time blocking addresses the most visible failures. For LLM applications, eval-time governance, production audit, and access control are equally important because compliance reviewers need proof that outputs were tested, traceable, and protected throughout the release process.
The four-layer LLM governance stack
LLM application governance comprises four layers, each addressing a specific governance risk. The strongest AI governance platforms cover multiple layers.
Layer 1: Eval-time governance checks model outputs before a prompt, model, retrieval change, or agent workflow reaches production. Custom scorers, golden datasets, LLM-as-judge evaluators, human review, and CI release gates form this stage. Strong eval-time governance turns quality checks into release requirements, so low-scoring changes fail before customers see the regression.
Layer 2: Production audit makes LLM behavior traceable after deployment. The layer includes immutable trace logs, full request and response capture, scorer results attached to each trace, and version history for prompts and models. A strong production audit provides engineering, security, and compliance teams with the evidence needed to understand why an application produced a specific output.
Layer 3: Access control and data isolation govern who can view, edit, approve, or export traces, datasets, scorers, prompts, and policies. Capabilities here include RBAC at the organization, project, and object levels, SSO via enterprise identity providers, audit logs for access events, and deployment options that keep sensitive data within the customer environment.
Layer 4: Runtime enforcement intercepts model inputs or outputs during live traffic and blocks, redacts, or flags content that violates policy. Implementation usually combines low-latency classifiers, policy checks for PII, prompt injection, jailbreak attempts, toxicity, and brand risk, with gateway integration into the application's request flow.
What to look for in an AI governance platform
Use the criteria below to compare how each platform supports release control, production review, sensitive data access, and runtime policy enforcement for LLM applications.
Eval-time scoring: A credible governance platform supports custom scorers, LLM-as-judge evaluators, code-based scorers, human review, and golden datasets, with the same scoring logic running in CI and against production traces.
Audit-grade tracing: Trace logs need to record the full request, response, prompt version, model version, scorer results, and timestamps. Logs should also be exported to SIEM and BI tools via Parquet or JSON Lines for external audit review.
RBAC and data isolation: Permission groups should operate at the organization, project, and object levels, with SSO via Okta, Microsoft Entra ID, Google Workspace, or custom OIDC, and workspace separation to support SOC 2 review requirements.
Runtime enforcement: Platforms that claim runtime governance should provide low-latency classifiers, policy checks for PII, prompt injection, toxicity, and copyright, and gateway integration that fits the application's request flow without adding unnecessary complexity.
Compliance certifications: SOC 2 Type II, HIPAA with Business Associate Agreements, and GDPR with Data Processing Agreements form the baseline for regulated teams. EU AI Act readiness depends on audit trail generation, policy mapping, access controls, and evidence export.
Deployment flexibility: Managed cloud supports fast pilots; hybrid deployment keeps sensitive data within the customer VPC; and fully self-hosted or air-gapped deployment supports regulated workloads with strict data control requirements.
Top 5 AI governance platforms for LLM applications in 2026
1. Braintrust
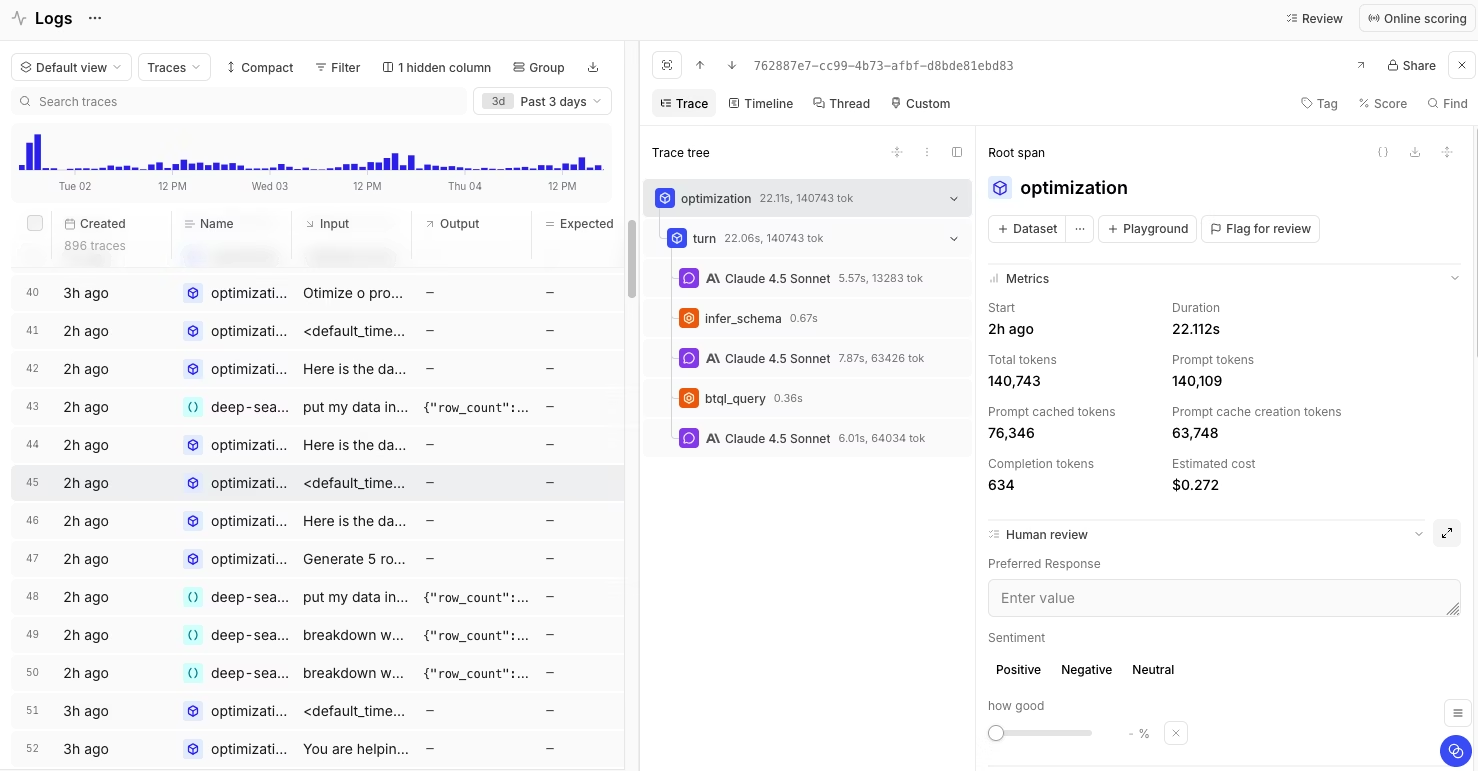
Best for: Teams that need eval-time governance, production audit, and RBAC for LLM applications within a single platform, with SOC 2 Type II coverage and hybrid deployment.
Layer coverage: Strong on layers 1, 2, and 3. Layer 4 requires a runtime enforcement tool.
Braintrust provides end-to-end AI evaluation and observability for teams shipping LLM features to production. Braintrust connects production tracing, offline evaluation, CI release gating, and human review into a single workflow, with the same scorer code running across both evaluation and production surfaces. The unified workflow turns every score into an auditable artifact attached to a specific trace, which is the audit-posture compliance reviewers expect in production LLM systems.
Eval-time governance
Braintrust supports LLM-as-judge scorers, code-based scorers, and human review through AutoEvals and custom evaluation workflows, with built-in checks for factuality, relevance, security, and other custom criteria. The native GitHub Action runs evaluation suites on every pull request and posts results in the PR comment, so teams can block merges when a scorer falls below the required threshold. The Playground lets engineers and product managers iterate on prompts, scorers, and models side by side in the browser, keeping non-engineering reviewers within the evaluation workflow without requiring code changes. Loop can also help reviewers describe issues in natural language and turn recurring failures into evaluation cases, which reduces engineering overhead in governance workflows.
Production audit
Every LLM call logged into Braintrust captures duration, time to first token, token usage, tool calls, errors, prompt version, model version, and estimated cost. Brainstore, the underlying storage engine, handles the nested, variable-length structure of AI traces and supports fast filtering across large volumes for audit review. Production traces convert into evaluation datasets with one click, so an audit incident becomes a regression test case without leaving Braintrust. Online scoring can run configured scorers on production traces as logs arrive, so audit records include live quality signals alongside offline evaluation results. Enterprise exports can send traces or spans to cloud storage in JSON Lines or Parquet for external audit review and downstream analysis.
Access control and compliance
Braintrust is SOC 2 Type II certified, supports HIPAA requirements with BAAs available, and supports GDPR requirements through Data Processing Agreements. Braintrust encrypts data at rest with AES-256 and in transit with TLS 1.2, and stores API keys as one-way cryptographic hashes. RBAC applies at the organization, project, and object levels, with built-in groups for Owners, Engineers, and Viewers, as well as custom groups for fine-grained permissions. SSO runs through Okta, Microsoft Entra ID, Google Workspace, and custom OIDC providers.
Deployment
Hybrid deployment separates the control plane from the data plane. The control plane runs on Braintrust infrastructure and handles UI, metadata, and authentication. The data plane runs inside the customer's AWS, GCP, or Azure VPC and stores traces, datasets, prompts, and evaluation results. Customer data does not flow through Braintrust's control plane, which supports EU residency and regulated-industry requirements. Enterprise customers can also run Braintrust in a fully self-hosted environment for air-gapped workloads.
Pros
- SOC 2 Type II, HIPAA with BAAs, and GDPR compliance, with AES-256 encryption at rest and TLS 1.2 in transit
- Hybrid deployment keeps trace data inside the customer's VPC across AWS, GCP, and Azure
- Native GitHub Action runs evals on every pull request and blocks merges below threshold
- Production traces convert into evaluation cases with one click, growing regression coverage from real failures
- Online scoring attaches evaluation results to live production traces
- Enterprise export supports JSON Lines and Parquet for external audit workflows
- RBAC operates at the organization, project, and object level, with SSO across Okta, Entra ID, Google Workspace, and OIDC
- Free Starter plan and flat Pro pricing reduce seat-based procurement friction
Cons
- Runtime policy blocking is outside Braintrust's core governance coverage.
- Classical ML governance features such as drift detection, fairness metrics, and SHAP explainability are not Braintrust's main focus.
Pricing: Free Starter plan with 1 GB processed data, 10K scores, and unlimited users. Pro at $249/month. Custom enterprise pricing available. See pricing details.
2. Galileo

Best for: Teams that need low-latency runtime protection for customer-facing LLM applications.
Layer coverage: Strong on layer 4. Partial on layers 1 and 2.
Galileo is an AI evaluation, observability, and runtime protection platform for GenAI and agentic applications. Galileo's runtime guardrails run checks on model inputs and outputs during production workflows to block harmful requests, prompt injection, PII leakage, hallucinations, and unsafe outputs. Luna-2 evaluator models run low-latency production scoring, and Galileo also supports pre-built metrics, custom evaluators, and agent-focused tracing. Galileo fits best when runtime enforcement is the main requirement, while deeper CI release gating and production-to-eval governance may still require additional eval infrastructure.
Pros
- Runtime protection can block harmful inputs or unintended outputs before users see them.
- Luna-2 evaluator models support low-latency production scoring.
- Pre-built metrics cover RAG, agents, safety, and quality checks.
- Agent Control provides an open-source policy layer for agent workflows.
Cons
- Real-time guardrails require Galileo Enterprise.
- CI release gating and production-to-eval workflows are less central than runtime protection.
Pricing: Free tier with 5,000 traces/month. Paid plan starts at $100/month. Custom enterprise pricing.
3. Credo AI
Best for: Enterprises that need portfolio-level AI governance across ML systems, agents, and LLM applications.
Layer coverage: Strong on layer 3 at the governance-program level. Layers 1, 2, and 4 are lighter at the LLM application level.
Credo AI runs enterprise AI governance programs through an AI registry, risk assessment workflows, policy packs, evidence generation, and audit-ready documentation. The pre-built policy packs cover frameworks such as the EU AI Act, NIST AI RMF, ISO 42001, SOC 2, and HITRUST. Credo AI is well-suited to organizations that need centralized governance across many AI systems, while engineering groups working on LLM application releases will still need a dedicated eval and tracing workflow.
Pros
- AI registry supports inventory management across ML models, agents, and LLM applications.
- Policy packs cover EU AI Act, NIST AI RMF, ISO 42001, SOC 2, and HITRUST.
- Evidence generation and audit-ready documentation support governance reviews.
- Third-party AI vendor assessments help track external AI system risk.
Cons
- Eval-time scoring and prompt iteration are not Credo AI's main focus.
- Application-level tracing and CI release control require separate tooling.
Pricing: Custom enterprise-only pricing.
4. Fiddler AI
Best for: Regulated enterprises that need LLM monitoring, runtime guardrails, and classical ML monitoring in the same platform.
Layer coverage: Strong on layers 2, 3, and 4. Layer 1 is partial.
Fiddler AI provides observability and guardrails for AI applications, with coverage across LLM systems and classical ML models. Fiddler Guardrails evaluates prompts and responses at runtime using Fiddler Center Models (formerly known as Trust Models) and enforces thresholds for hallucinations, safety violations, and jailbreak attempts. Fiddler also supports ML monitoring use cases such as model drift, performance degradation, fairness review, and explainability, making it a better fit for organizations that govern both traditional ML and LLM systems. Eval-time prompt iteration and CI-based release control are less central to Fiddler's product surface.
Pros
- Runtime guardrails evaluate prompts and responses in under 100ms.
- Guardrails can enforce thresholds for hallucinations, safety violations, and jailbreak attempts.
- Trust Models can run in the customer environment to reduce data egress.
- Classical ML monitoring covers workflows for drift, fairness, performance, and explainability.
Cons
- Eval-time prompt iteration and CI release gating are not Fiddler's main focus.
- Engineering teams that need release-control evals may need a separate evaluation workflow.
Pricing: Free guardrails plan with limited functionality. Full observability and enterprise deployment require custom pricing.
5. Patronus AI
Best for: Teams in regulated domains that need evaluator models and benchmarks for hallucination, PII, copyright, and domain-specific failure modes.
Layer coverage: Strong on layer 1 for evaluator coverage. Layer 4 is partial through smaller evaluator variants.
Patronus AI evaluates, monitors, and improves LLM systems through evaluator models, benchmarks, API-based evaluation, and tracing support. Lynx targets hallucination detection, Glider supports rubric-based judging, and FinanceBench provides a finance-focused benchmark grounded in public company filings. Patronus AI fits teams that need evaluator depth for regulated-domain checks, while collaboration, CI release gating, and governance workflow coverage are lighter than a full eval platform.
Pros
- Lynx supports hallucination detection across evaluation workflows.
- Glider supports rubric-based scoring.
- FinanceBench covers finance-specific question answering grounded in company filings.
- API and SDK support make Patronus usable inside custom evaluation pipelines.
Cons
- Collaboration and dashboard workflows are lighter than full evaluation platforms.
- Usage-based evaluator calls can be harder to forecast at scale.
Pricing: Free Lynx model available as an open-source download. Usage-based API pricing, $10-20 per 1,000 API calls, depending on evaluator size for hosted Patronus evaluators. Custom enterprise pricing.
Quick comparison: Best AI governance platforms for LLM applications (2026)
| Feature | Braintrust | Galileo | Credo AI | Fiddler AI | Patronus AI |
|---|---|---|---|---|---|
| Custom, LLM-as-judge, and code scorers | Strong | Strong | Partial | Partial | Strong |
| Golden dataset support | Strong | Strong | Partial | Partial | Strong |
| CI release gate | Native GitHub Action | Partial | Not covered | Not covered | Not covered |
| Production-to-eval conversion | One-click | Partial | Not covered | Partial | Partial |
| Immutable trace logs | Strong | Strong | Strong | Strong | Strong |
| Audit export | Parquet and JSON Lines | Partial | Strong | Strong | Partial |
| RBAC at org, project, and object level | Strong | Strong | Strong | Strong | Partial |
| SSO through Okta, Entra, Google, or OIDC | Strong | Strong | Strong | Strong | Strong |
| EU residency or self-hosting | Strong — hybrid VPC deployment | Partial | Partial | Strong | Partial |
| Policy library or compliance packs | Strong | Strong | Strong | Strong | Strong |
| SOC 2 Type II | Strong | Strong | Strong | Strong | Strong |
| HIPAA with BAA | Strong | Partial | Partial | Strong | Partial |
| Free tier | Free Starter plan with 1 GB processed data, 10K scores, and unlimited users | 5K traces/month | No public free tier | Free guardrails | Free Lynx OSS |
| Starting paid plan | Pro at $249/month with 5 GB processed data and 50K scores | $100/month with 50K traces | Custom enterprise | Custom pricing | Usage-based |
Upgrade your LLM governance workflow with Braintrust. Start free today.
Choosing the right AI governance platform
AI governance platform selection should start with which control the LLM application needs first: release gates and audit records before deployment, real-time blocking for live traffic, portfolio-level policy management, or domain-specific evaluator coverage.
Choose Braintrust if eval-time governance, production audit, RBAC, and deployment flexibility are the main requirements. Braintrust connects scorers, datasets, production traces, human review, and CI release gates into a single workflow, making it the strongest fit when governance needs to influence what reaches production.
Choose Galileo if low-latency runtime protection is the primary requirement for customer-facing LLM traffic. Galileo is strongest when the application needs real-time checks for unsafe outputs, prompt injection, PII leakage, or other policy violations during live requests.
Choose Credo AI if the organization needs portfolio-level governance across many AI systems. Credo AI fits centralized governance programs that manage registries, risk assessments, policy packs, and audit documentation across ML models, agents, and LLM applications.
Choose Fiddler AI if classical ML monitoring and LLM monitoring need to sit in the same system. Fiddler AI fits organizations that need runtime guardrails, drift monitoring, fairness review, explainability, and production oversight across mixed AI workloads.
Choose Patronus AI if regulated-domain evaluator coverage is the main requirement. Patronus AI fits teams that need benchmarks and evaluator models for hallucination, PII, copyright, finance, legal, healthcare, or other domain-specific failure modes.
For most regulated LLM applications, use Braintrust for evals, audit, access control, and release gates. Add runtime enforcement when the application also needs real-time blocking during live traffic.
Why Braintrust is the strongest choice for LLM governance
LLM governance is strongest when evaluation influences what reaches production. Braintrust connects eval-time scoring, production traces, human review, and CI release gates, so prompt, model, retrieval, and agent changes can be tested before deployment and monitored against the same quality standards after release.
For regulated teams, Braintrust keeps governance evidence connected across traces, datasets, scorers, prompts, experiments, and review results. RBAC, SSO, SOC 2 Type II, HIPAA, GDPR, hybrid deployment, and self-hosted deployment support the access-control and data-residency requirements behind production governance.
Teams including Notion, Stripe, Vercel, Zapier, Airtable, and Instacart use Braintrust for production AI evaluation and observability. Start free with Braintrust to connect evaluation, audit, and release control before the next production deployment, or book a demo to see hybrid deployment running in your environment.
FAQs about AI governance for LLM applications
Is AI governance the same as AI safety or AI compliance?
AI governance, AI safety, and AI compliance overlap, but they are not the same function. AI governance defines how an organization evaluates model behavior, records outputs, controls access, and enforces policies across development and production. AI safety focuses on reducing harmful model behavior, while AI compliance focuses on meeting legal, security, or industry-specific requirements. Braintrust fits the governance layer for LLM applications by connecting eval-time scoring, audit-grade tracing, access control, and release decisions.
Do I need a runtime guardrail platform and an eval platform?
Most production LLM applications in regulated industries run both, with the eval platform sitting in CI and the guardrail platform sitting in the request path. A typical setup routes user traffic through the LLM gateway, with the runtime guardrail inspecting inputs and outputs inline, and logging every request and response to the eval platform for offline scoring and audit. Failures caught by the guardrail in production become test cases in the eval platform, which tunes scorer thresholds and informs the next round of guardrail rules. Internal-only or low-traffic applications can sometimes ship with eval coverage alone, since the cost of a bad output is bounded by who can see it.
What does the EU AI Act require for LLM applications?
The EU AI Act's main provisions include the high-risk system rules in Annex III and the transparency obligations in Article 50. LLM application providers and deployers may need technical documentation, audit logs, risk assessment processes, human oversight workflows, and transparency controls depending on the use case. Braintrust supports those compliance requirements through trace logging, exportable audit records, RBAC for human review, and EU data residency through hybrid or self-hosted deployment.
How does Braintrust handle SOC 2, HIPAA, and EU data residency?
Braintrust completes an annual SOC 2 Type II audit and makes the report available through the Trust Center under mutual NDA, along with penetration test summaries, subprocessor lists, and security policy documentation. BAAs for HIPAA workloads and DPAs for GDPR are signed during procurement. EU data residency works through a hybrid deployment model that places the data plane inside an EU-region VPC that the customer controls, so customer-trace data never leaves the region. Most regulated teams use a hybrid setup to satisfy data-locality requirements that arise during their SOC 2 or ISO 27001 audits.
Can I export audit logs for an external compliance review?
Braintrust supports audit exports in JSON Lines and Parquet, as well as on-demand exports by project or organization via the API. Trace records can include the full request, response, prompt version, model version, scorer results, and timestamps, providing external reviewers with the evidence chain needed for SOC 2, HIPAA, or EU AI Act reviews. Braintrust's observability documentation covers export workflows and retention configuration.
Does Braintrust have a free tier for governance use cases?
The free Starter plan covers 1 GB of processed data, 10K evaluation scores per month, and unlimited users, which is enough capacity to wire up CI release gates, test scorer logic against real production traces, run human review workflows, and verify the audit export format before procurement begins. The features most regulated teams eventually need (SSO, RBAC, hybrid or self-hosted deployment, custom retention, and custom export) are on the Enterprise tier, so a typical procurement path runs a proof of concept on Starter and moves to Enterprise when the compliance program needs to enforce policy in production.