DeepEval alternatives (2026): Best tools for LLM evals, RAG, and agent testing
Braintrust is the strongest DeepEval alternative because it covers the full eval lifecycle that DeepEval's open-source layer leaves incomplete. Braintrust carries evaluation through production monitoring, team collaboration, and automated release enforcement on a single platform.
Other top alternatives:
- RAGAS - Research-backed RAG evaluation metrics, but limited to retrieval and generation scoring with no production monitoring or collaboration features
- Promptfoo - Open-source eval and red teaming with YAML-driven configs, but results stay local with no centralized experiment tracking
- Arize Phoenix - OpenTelemetry-native, self-hostable tracing and evaluation, but managed features and tighter eval integration require moving to Arize AX
- Langfuse - Open-source and self-hostable with a managed cloud option, but self-hosting adds infrastructure overhead, and eval depth is limited compared to full platforms
- Agenta - Open-source playground with built-in evaluation and observability in one platform, but native CI/CD release gating is less developed
- Galileo - Production guardrails and low-latency evaluation scoring, but prompt iteration and deployment enforcement remain limited
Why teams look for DeepEval alternatives
DeepEval's open-source evaluation framework is designed for engineers who want pytest-style LLM tests to run in CI. DeepEval works best in a code-first workflow where evaluations are defined, executed, and reviewed within the same engineering context.
What DeepEval does well
DeepEval provides broad coverage for local evaluation and CI-driven testing:
- 50+ built-in metrics, including G-Eval, faithfulness, hallucination detection, answer relevancy, and task completion scoring.
- Component-level evaluation was introduced in version 3.0, allowing teams to score individual function calls, retrievers, and tool invocations using the @observe decorator.
- Native pytest integration, making CI pipelines straightforward for Python teams.
- Synthetic dataset generation using evolution techniques to expand coverage from seed examples.
- Multi-modal evaluation for image-based test cases.
- Multi-turn conversational testing through ConversationalTestCase.
- ArenaGEval for A/B output comparison across prompts or models.
- Agent-specific metrics covering task completion, tool correctness, planning quality, and efficiency.
- DeepTeam, a separate project from the same team, for red teaming across 40+ vulnerability categories.
When DeepEval falls short
The following limitations apply to DeepEval's open-source layer:
- Evaluation results live in terminal output or JSON files unless teams adopt Confident AI, the commercial platform built by the same team.
- No built-in production monitoring for scoring live traffic or detecting quality drift in real time.
- Dataset management is fully code-based, with no UI for browsing, annotating, or collaborating on test cases.
- Sharing results requires pull requests or artifact files rather than shared dashboards.
- No native production-to-eval feedback mechanism in the free tier, so production failures cannot automatically become regression cases without custom infrastructure or upgrading to Confident AI.
DeepEval is effective within its intended scope, but its open-source architecture is built for local execution rather than shared, production-facing evaluation workflows. When evaluation becomes a cross-functional, production-level requirement, teams typically move to hosted platforms that provide shared dashboards, production monitoring, and release governance.
Open-source DeepEval alternatives
RAGAS: Research-backed metrics for RAG evaluation
RAGAS is best suited for teams running retrieval-augmented generation pipelines that need structured retrieval and generation metrics.
The RAGAS framework evaluates RAG systems without requiring ground-truth labels, which simplifies early dataset construction. It separates retrieval quality metrics, such as context precision and context recall, from generation quality metrics, such as faithfulness and answer relevance, making it easier to diagnose which stage of the RAG pipeline is underperforming. RAGAS integrates with LangChain, LlamaIndex, and Haystack and supports knowledge-graph-based synthetic test generation.
RAGAS operates primarily as a metrics library rather than a complete evaluation system. It does not provide CI orchestration, production monitoring, experiment tracking, or collaboration interfaces. Teams typically run RAGAS metrics inside a broader evaluation infrastructure rather than using it as a standalone evaluation management system.
Promptfoo: Open-source LLM evaluation and red teaming
Promptfoo is designed for teams that combine LLM evaluation with structured security testing.
Promptfoo has expanded toward red teaming, offering an agent that performs reconnaissance, attack planning, and vulnerability scanning aligned with OWASP and NIST presets. Promptfoo is fully open-source, runs locally, and uses Node.js rather than Python. Evaluation is configured via YAML files, and CI integration is provided by a GitHub Action that shows before-and-after pull request diffs.
As an evaluation system, Promptfoo remains local-first. Results are stored in CI artifacts or local runs, without centralized experiment tracking or persistent quality dashboards. Promptfoo is well-aligned for teams prioritizing jailbreak resistance and compliance testing, but it does not serve as a full evaluation management layer.
RAGAS and Promptfoo expand on specific aspects of LLM evaluation. RAGAS focuses on research-backed retrieval and generation scoring for RAG pipelines, while Promptfoo emphasizes red teaming and security validation. Both extend evaluation capabilities beyond DeepEval in targeted ways, but remain framework-first tools built for local execution rather than shared evaluation management.
5 best hosted DeepEval alternatives for LLM evaluation (2026)
1. Braintrust
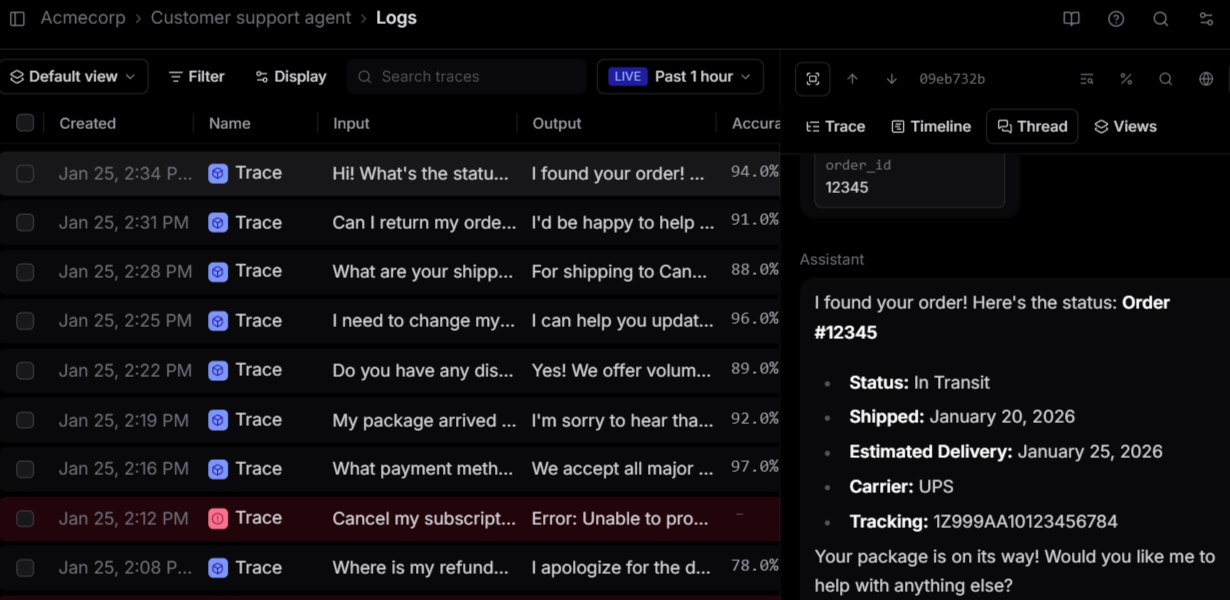
Best for: AI SaaS teams shipping LLM features to production that require every release to meet defined quality thresholds before it goes live.
Most open-source evaluation frameworks generate scores but stop short of integrating those scores into release workflows. Braintrust connects evaluation scoring with production tracing, dataset management, cross-functional review, and CI-based release enforcement inside a single system.
Braintrust captures every model call, tool invocation, and application-layer interaction through the AI gateway, which supports OpenAI, Anthropic, Google, and other providers, or through Python and TypeScript SDKs for direct instrumentation. The interactions are stored in Brainstore, Braintrust's observability database, as structured, searchable records across millions of entries. Teams can trace failures back to specific prompts, tool calls, or agent steps and identify exactly where and why output quality degraded in production.
Rather than leaving teams to query static dashboards, Braintrust runs analysis in the background so problems surface on their own. Topics clusters every production trace by intent, sentiment, and recurring issue (with custom facets you define), so the failure modes worth testing show up across all traffic without manual review. Those recurring patterns are exactly the cases worth converting into evals, which closes the loop back into the offline test suite.
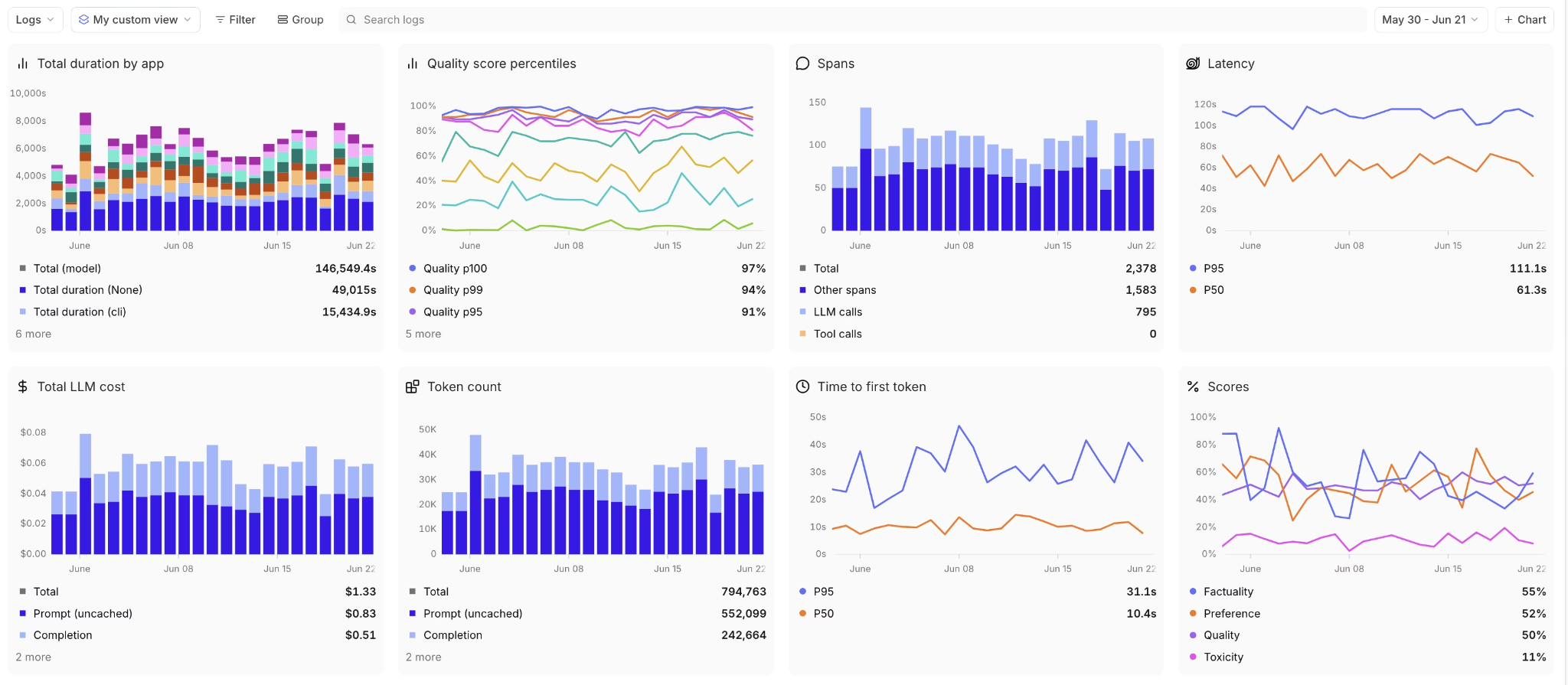
Braintrust connects evaluation results directly to release decisions. Teams define custom metrics, LLM-as-a-judge scorers, and human-annotation workflows to measure output quality across multiple levels. Production traces can be converted into structured evaluation dataset entries with one click, and the GitHub Action evaluates every pull request, posts per-test-case regression diffs, and blocks merges when scores fall below defined thresholds. Regressions are addressed during code review instead of after deployment.
Loop, Braintrust's AI assistant, reduces the overhead of writing evaluations by generating production-ready scorers, datasets, and improved prompt variants from plain-language descriptions. The shared Playground provides PMs and engineers with a unified workspace to compare outputs, annotate results, and test prompt variations against real production data without exporting traces or recreating datasets in separate tools.
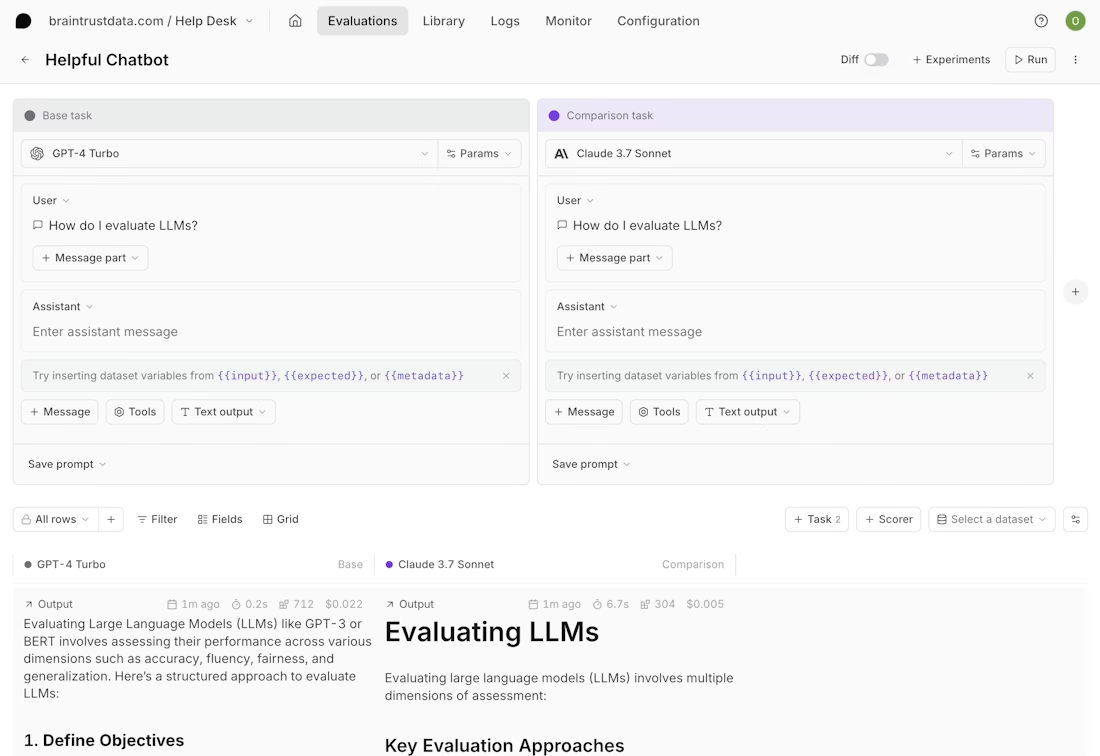
Unlike DeepEval, which operates as a testing framework, Braintrust makes evaluation a prerequisite for deployment.
Pros
- CI/CD quality gates: Braintrust's GitHub Action evaluates every pull request and blocks merges when scores drop below set thresholds, catching regressions before they reach production.
- Production-to-eval pipeline: One-click trace-to-dataset conversion turns live failures into permanent regression tests, strengthening the eval suite over time.
- Eval modes: Braintrust supports offline dataset-based evaluation during development, online evaluation against live production traffic, and automated evaluation in CI.
- Cross-functional collaboration: The shared Playground lets PMs and engineers compare outputs, annotate results, and tie feedback directly to release decisions in one workspace.
- Automated scorer generation: Loop creates scorers and datasets from production data using plain-language descriptions, removing the manual overhead of writing evaluation logic.
- Framework-agnostic: OpenTelemetry support, SDK instrumentation, and the AI gateway work with any orchestration stack without requiring lock-in to a framework.
- Unlimited users on the free tier: Quality reviews scale across product, engineering, and leadership without incurring per-seat costs.
Cons
- Self-hosting is available only on the Enterprise tier
- Closed-source platform
Pricing
Free tier includes 1 GB of processed data, unlimited users, and 10K scores. Pro plan at $249/month. Enterprise plans are custom. See pricing details.
Why AI SaaS teams choose Braintrust over DeepEval
| Dimension | Braintrust | DeepEval | Winner |
|---|---|---|---|
| Evaluation model | Production-grade evaluation platform with governance and enforcement | Open-source evaluation framework focused on local test execution | Braintrust |
| Eval lifecycle coverage | Dataset management, scoring, monitoring, regression tracking, and release enforcement in one system | Local evaluation execution; no native lifecycle management in the OSS layer | Braintrust |
| Production observability | Structured, searchable traces via AI gateway and Brainstore | No production tracing in the OSS layer | Braintrust |
| Release governance | Evaluation results tied directly to deployment decisions with merge blocking | Test execution in CI without native release governance | Braintrust |
| Team collaboration | Shared Playground with annotation workflows and experiment history | Terminal output and JSON; cloud collaboration requires Confident AI | Braintrust |
| Integration flexibility | AI gateway, OpenTelemetry, Python and TypeScript SDKs | Python-native framework | Braintrust |
| Dataset management | Versioned datasets with UI, annotation queues, and production import | Code-only dataset management | Braintrust |
| Eval metrics depth | Custom scorers, LLM-as-judge, human annotation, Loop-generated scorers | 50+ built-in metrics, G-Eval, component-level evals, ArenaGEval | Tie |
| RAG evaluation | Built-in RAG scorers with RAGAS metric import | Native RAG metrics with context precision, recall, and faithfulness | Tie |
| Agent evaluation | Trace-level evaluation with tool call and multi-step scoring | Task completion, tool correctness, planning quality metrics | Tie |
| Free tier model | Hosted platform with 1 GB processed data/month, unlimited users, 10K scores | Unlimited local OSS usage; hosted features via Confident AI with a 2-user free cap | Depends on workflow |
Ready to move eval results from terminal output into production? Start free with Braintrust.
2. Arize Phoenix
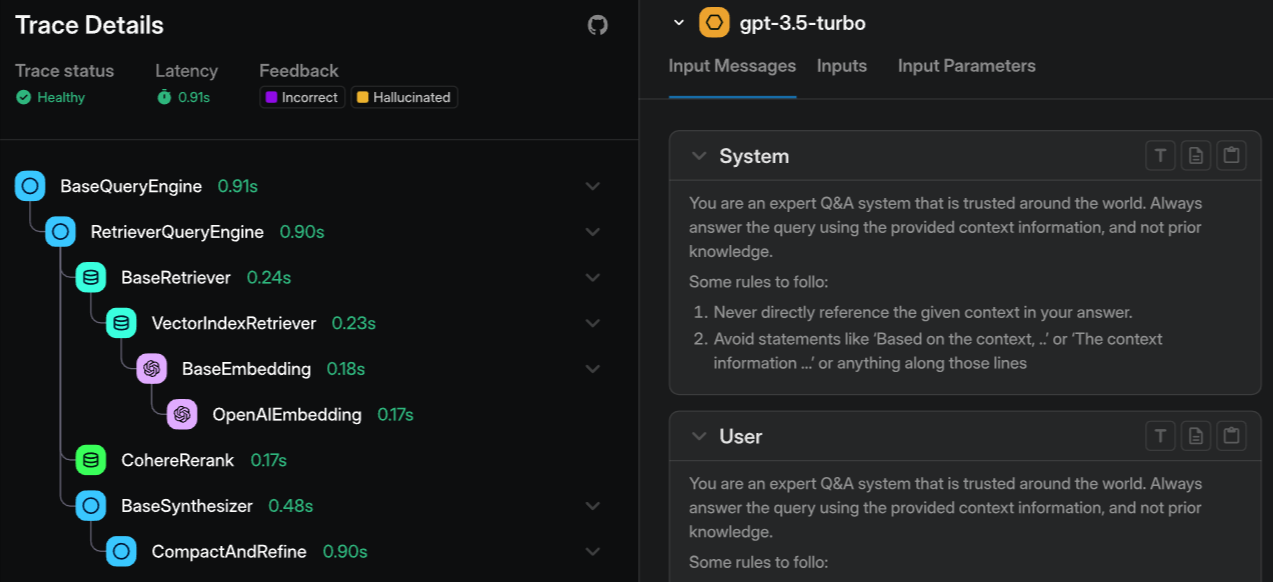
Best for: Teams that want OpenTelemetry-native, vendor-agnostic tracing and evaluation they can self-host with no feature restrictions.
Arize Phoenix captures traces with OpenTelemetry and the OpenInference standard, which keeps the data portable instead of tied to one vendor. You can replay a trace to inspect a failure and use the built-in evaluation templates to analyze model behavior while debugging. Phoenix also has embedding clustering and drift detection to surface patterns across similar failures. The open-source version is fully self-hostable with no feature restrictions. The managed cloud offering, Arize AX, adds enterprise support and more compliance capabilities. Evaluation runs through prebuilt templates that show you output quality, but it is looser than on eval-first platforms and does not act as a release gate. For a closer look, see Arize Phoenix vs Braintrust.
Pros
- OpenTelemetry-native with vendor-agnostic, portable trace data
- Embedding clustering and drift detection for surfacing failure patterns
- Free and self-hostable with no feature restrictions
- Broad framework support through OpenInference instrumentation
Cons
- Managed cloud features require moving to Arize AX with separate enterprise pricing
- Evaluation workflows are less integrated than eval-first platforms
- Evaluation results provide visibility, but do not function as automated release enforcement
Pricing
Open-source version is free and fully self-hostable with no feature restrictions. Managed cloud offering, Arize AX, has a free tier (25K spans) with custom enterprise pricing for additional support and compliance capabilities.
3. Langfuse
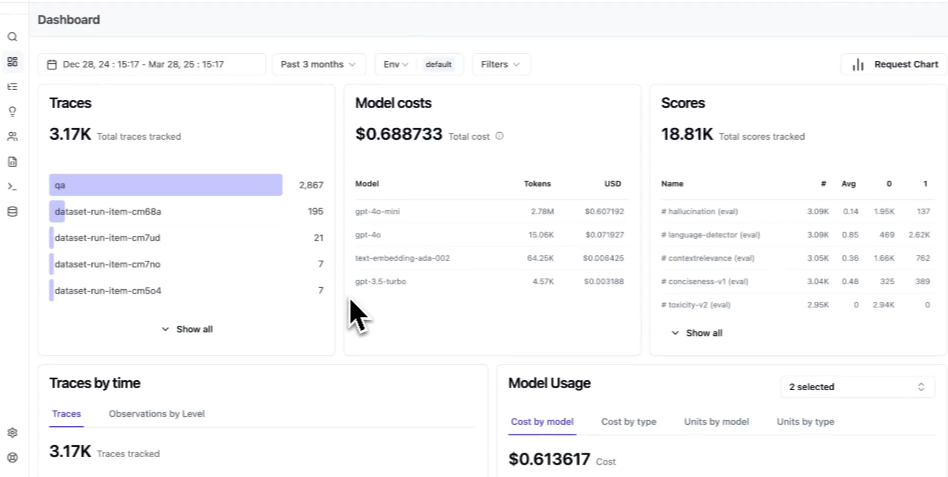
Best for: Teams that require open-source deployment and are prepared to operate their own LLM observability infrastructure.
Langfuse is an open-source LLM engineering platform that teams can self-host for full control over data and infrastructure. Langfuse includes trace visualization, prompt versioning, evaluation with LLM-as-a-judge support, and cost and latency tracking across providers. The v3 SDK adds native OpenTelemetry support, and a managed cloud deployment option is available for teams that prefer not to operate their own infrastructure. Langfuse's eval capabilities include LLM-as-a-judge support, but it offers fewer built-in scorers than Braintrust and no AI-assisted scorer generation.
Pros
- Open-source with a self-hosting option
- Managed cloud deployment is available
- Trace visualization, prompt versioning, and cost tracking
- OpenTelemetry support with SDK coverage
Cons
- Production self-hosting requires infrastructure components such as ClickHouse, Redis, and Kubernetes
- Evaluation features are part of observability rather than structured release governance
- Cross-functional collaboration features are limited compared to Braintrust
Pricing
Free self-hosting and a free cloud plan with 50K units per month. Paid plan starts at $29 per month.
4. Agenta
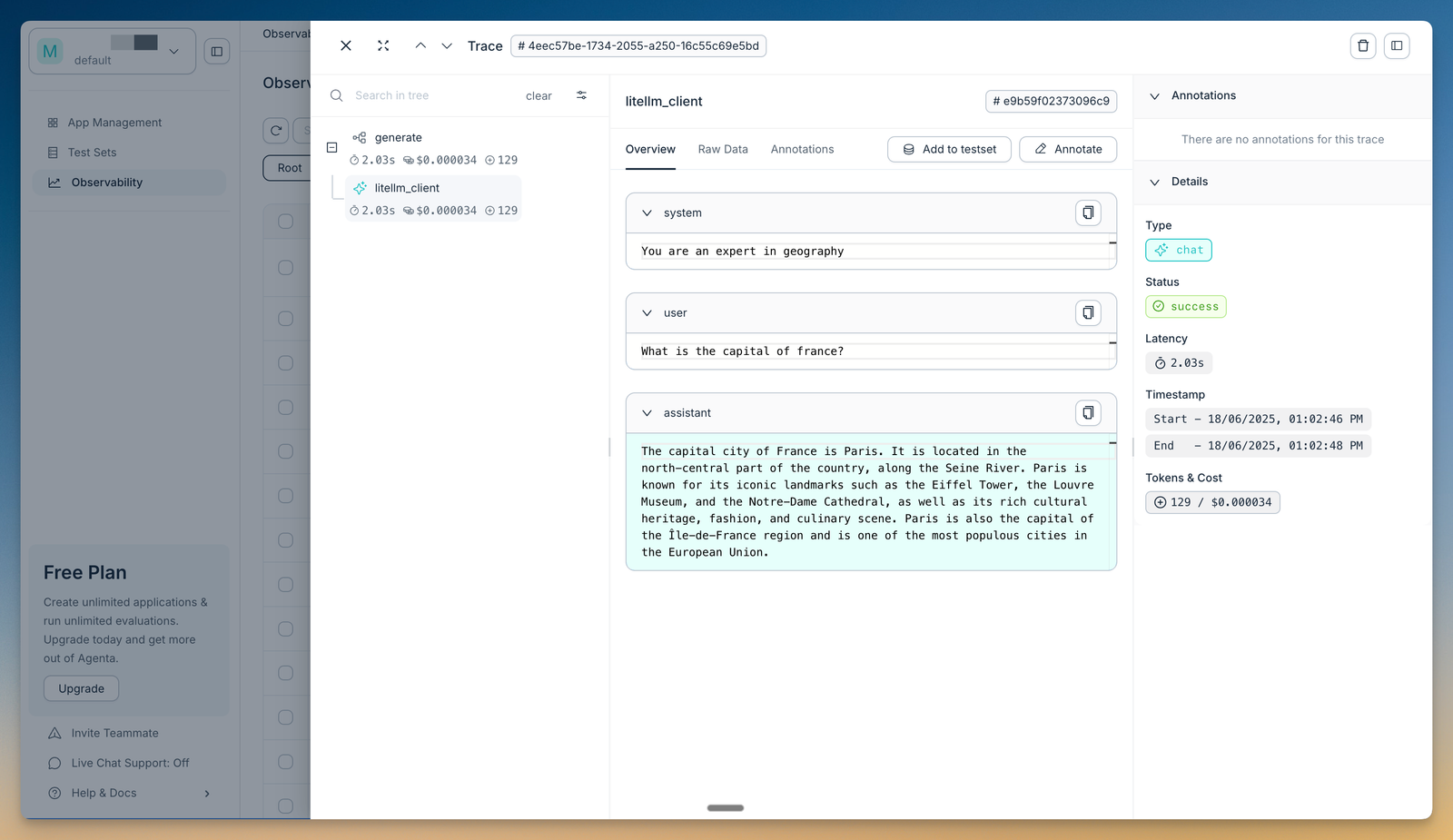
Best for: Teams that want an open-source platform combining a prompt playground, evaluation, and observability in one place.
Agenta is an open-source LLMOps platform that brings prompt management, a prompt playground, evaluation, and observability together. In the playground, teams compare prompts and models side by side, keep a complete version history, and deploy prompt changes without touching application code. Evaluation runs automated LLM-as-a-judge and custom evaluators, scores a full trace across an agent's steps, and supports human annotation. Observability traces every request so teams can pinpoint failures and annotate the traces directly. The core platform is MIT-licensed and self-hostable, and it integrates with LangChain, LlamaIndex, and OpenAI.
Pros
- Open-source and self-hostable, with prompt management, playground, evaluation, and observability in one platform
- Automated LLM-as-a-judge and custom evaluators, plus human annotation
- Side-by-side prompt and model comparison with full version history
Cons
- Native CI/CD release gating that blocks merges on eval scores is less developed
- Self-hosting the open-source stack adds infrastructure overhead
- Production-scale trace analysis is narrower than tracing-native systems
Pricing
Hobby tier is free (2 seats, 5K traces/month). Pro starts at $49/month, Business at $399/month, with custom enterprise pricing. Self-hosted open source is free.
5. Galileo

Best for: Enterprise teams focused on safety scoring and real-time guardrails in production environments.
Galileo is structured around production-grade evaluation and guardrail enforcement, using its Luna-2 small language models to deliver low-latency scoring. The Agent Reliability Platform includes agent observability, automatic failure detection, and guardrails that can intervene before tool execution. Galileo's built-in metrics cover retrieval systems, agents, safety, and security use cases, and support continuous scoring on live traffic. Galileo is more oriented toward safety and guardrail enforcement than toward collaborative prompt experimentation or CI-based release governance.
Pros
- Low-latency evaluation scoring through Luna-2 models
- Built-in metrics for retrieval, agents, safety, and security
- Real-time guardrails with pre-execution intervention
Cons
- Focused on guardrails and scoring rather than collaborative prompt iteration
- CI-based merge blocking is not part of the core workflow
- The observability scope is narrower than full evaluation lifecycle platforms
Pricing
Free tier with 5,000 traces/month. Paid plan starts at $100/month. Custom enterprise pricing.
Best DeepEval alternatives compared (2026)
| Feature | Braintrust | RAGAS | Promptfoo | Arize Phoenix | Langfuse | Agenta | Galileo |
|---|---|---|---|---|---|---|---|
| Code-first workflow | SDK + UI | Python library | YAML + CLI | OpenTelemetry SDK + UI | SDK-based | SDK + UI | SDK-based |
| Team collaboration | Playground, annotations, shared links | No | No | Dashboard sharing | Basic annotation | Playground, annotations | Eval-focused |
| Dataset management | Versioned, UI, one-click from prod | Code-only | YAML-based | Limited | Limited | Limited | Limited |
| Eval depth | Custom + LLM judge + Loop AI | RAG metrics only | Assertions + red teaming | Evaluation templates | LLM-as-judge | Custom + LLM judge | Luna-2 + built-in metrics |
| RAG eval | Yes | Yes | Limited | Yes | Limited | Limited | Yes |
| Agent eval | Yes | No | Limited | Yes | Limited | Yes | Limited |
| CI/CD gating | GitHub Action + merge blocking | No | GitHub Action (no blocking) | Requires custom integration | No | No | No |
| Prod to eval loop | One-click trace to eval case | No | No | Trace replay, manual | Manual | Manual | Guardrails only |
| Free tier | 1 GB data, 10K scores, unlimited users | Free OSS | Free OSS | Free OSS + 25K spans (AX) | 50K units/month | Free (2 seats, 5K traces) | 5K traces/month |
DeepEval vs alternatives: How to choose
Choose DeepEval if evaluation is primarily a code-level testing activity managed by engineering within local development and CI workflows.
Choose Braintrust when LLM quality directly affects customer trust, revenue, or product credibility, and every release needs defined quality thresholds before it goes live. Braintrust gives teams a structured system to evaluate, monitor, and enforce quality across development and production without relying on manual review or scattered tooling.
Choose RAGAS if your primary requirement is retrieval and generation metrics for a RAG pipeline and you plan to run those metrics within a broader evaluation system.
Choose Promptfoo if LLM security testing and red teaming are the primary requirements and your team operates primarily in a Node.js environment.
Choose Arize Phoenix if OpenTelemetry-native, vendor-agnostic tracing and a fully self-hostable open-source deployment are the priority.
Choose Langfuse if self-hosting and infrastructure control are non-negotiable requirements and your team has the operational capacity to manage observability systems.
Choose Agenta if you want an open-source platform that combines a prompt playground, evaluation, and observability and you are willing to self-host.
Choose Galileo if real-time safety guardrails, low-latency scoring, and compliance-focused evaluation in production environments are the main objectives.
Why Braintrust is the best DeepEval alternative
DeepEval enables engineers to validate LLM behavior inside local development workflows. Braintrust is designed for organizations that treat LLM quality as a release-level responsibility, where output standards are defined, enforced, and visible across teams before changes reach users. Braintrust provides a unified governance layer that connects evaluation directly to deployment authority, reducing the likelihood that regressions reach production while keeping engineering velocity aligned with product accountability.
Quality failures surface most often under real production traffic. Braintrust captures production traces, converts failure cases into structured evaluation datasets, and integrates scoring into CI to identify regressions before deployment. Replicating the same level of enforcement with DeepEval's open-source framework requires building and maintaining custom systems for tracing, storage, dataset management, scoring, and CI orchestration.
Braintrust also gives cross-functional teams shared access to evaluation workflows that would otherwise be locked inside engineering's codebase. Product managers, QA leads, and engineers review traces, annotate outputs, and manage datasets inside the same Playground, with shared visibility into experiments and quality metrics. Loop generates scorers and datasets from production data, reducing the operational overhead of formalizing evaluation criteria for new features and model updates.
Braintrust is SOC 2 Type II-certified and HIPAA-compliant, with hybrid deployment options for enterprise environments that require additional operational control. Organizations including Notion, Stripe, Vercel, Zapier, Ramp, and Instacart run production evaluation workflows through Braintrust.
Start with Braintrust's free tier or schedule a demo to connect evaluation directly to your release process.
DeepEval alternatives FAQs
Why do people look for alternatives to DeepEval?
DeepEval works well as a code-first evaluation framework for individual engineers running local tests in CI. Teams begin evaluating alternatives when evaluation results need to be visible beyond engineering, when quality must be tracked across model and prompt versions over time, or when production failures need to inform regression coverage. DeepEval's open-source layer does not include shared dashboards, production monitoring, or built-in collaboration workflows, and its hosted features are delivered separately through Confident AI. Organizations that require evaluation to operate as a production governance layer typically move to full platforms.
What is the best DeepEval alternative?
Braintrust is the best DeepEval alternative for teams that need evaluation to govern what ships to production. While DeepEval focuses on local, code-level testing, Braintrust connects evaluation to release control, shared team visibility, and ongoing production oversight, making it suitable for organizations that treat LLM quality as a deployment requirement. Braintrust is designed for teams that want consistent quality standards across development and production, with enforcement mechanisms that prevent regressions from reaching users.
Is Braintrust better than DeepEval?
Braintrust and DeepEval serve different stages of the evaluation lifecycle. DeepEval provides engineers with pytest-style assertions and built-in metrics for local validation. Braintrust operates at the platform level, where evaluation results inform release decisions, quality standards persist across versions, and teams share visibility into model behavior over time. DeepEval is sufficient for solo developers validating prompts locally. Organizations whose LLM quality directly affects what ships to users will find Braintrust's full eval suite a better match for their needs.
What is the best LLM evaluation tool in 2026?
The answer depends on where a team sits in the evaluation lifecycle. DeepEval covers local test execution, RAGAS provides research-backed retrieval and generation metrics, Promptfoo adds red teaming and security validation, Arize Phoenix offers OpenTelemetry-native, self-hostable tracing, Langfuse offers self-hosted observability, Agenta offers an open-source prompt playground with built-in evaluation and observability, and Galileo focuses on real-time guardrails. Braintrust is the only platform that connects all stages of the evaluation lifecycle, from dataset management through scoring, production monitoring, and CI-based release enforcement, inside a single system.
How do I get started with LLM evaluation?
Define what "good output" means for your specific application, then build a small dataset of representative inputs with expected outputs. Braintrust lets teams start with offline evals against that dataset, add LLM-as-a-judge and human-annotation scorers as quality criteria become clearer, and then wire those scores into CI so every pull request is evaluated automatically. The production-to-eval pipeline means that live failures become regression test cases with a single click, so the evaluation suite strengthens over time without manual dataset curation.