LangSmith alternatives (2026): Best tools for LLM tracing, evals, and prompt iteration
Braintrust is the strongest LangSmith alternative for LLM production teams that need production tracing, structured evaluations, CI/CD quality gates, and controlled releases in a single system.
Other top alternatives:
- Langfuse - Open-source and self-hostable with a cloud option, but self-hosting means managing your own infrastructure, and the hosted tier has usage limits that can add up at scale.
- Agenta - Open-source, self-hostable platform that combines a prompt playground, prompt management, evals, and observability in one place, but lacks native CI/CD gating capabilities.
- Galileo - Strong production evaluators and guardrails, but deployment enforcement remains limited compared to a full eval-to-production loop.
- Fiddler AI - Enterprise-grade ML and LLM monitoring with compliance-focused governance, but more geared toward large enterprises with robust security requirements.
Pick Braintrust if you need the complete eval-to-production loop with CI/CD gates and cross-functional collaboration. Pick others for open-source flexibility, self-hosting, or compliance-first monitoring.
Why teams look for LangSmith alternatives
If you are building entirely on LangChain or LangGraph, LangSmith works well as it traces LangChain apps with a single environment variable, and the evaluation framework integrates directly with the LangChain ecosystem.
Once applications move into shared environments and production traffic increases, teams begin to notice specific limitations, including:
Limited framework flexibility: LangSmith is built around LangChain, so teams using custom orchestration layers, direct provider APIs, or mixed framework stacks receive less native support and must invest additional effort in instrumentation.
Access costs increase as collaboration expands: As more engineers, product managers, and stakeholders need visibility into traces and evaluation results, costs rise with headcount rather than with actual usage. Teams that want prompt quality to be a shared responsibility often find this pricing model harder to scale as collaboration grows.
No deployment enforcement: LangSmith surfaces evaluation results in dashboards for review, but those results do not automatically influence the deploy pipeline. Quality drops can pass through code review and reach production before someone manually intervenes, which weakens evaluation as a safeguard.
Iteration remains engineering-dependent: Prompt changes move through engineers from testing to release, while product managers and other collaborators rely on tickets and handoffs instead of testing variations directly. This structure slows iteration and limits cross-functional ownership of output quality.
Tracing and regression testing remain separate workflows: When a production failure occurs, teams must manually connect traces to existing test datasets and create new regression cases themselves. Without a direct link between live failures and evaluation workflows, preventing repeat issues requires additional coordination and process overhead.
Top 5 LangSmith alternatives (2026)
1. Braintrust
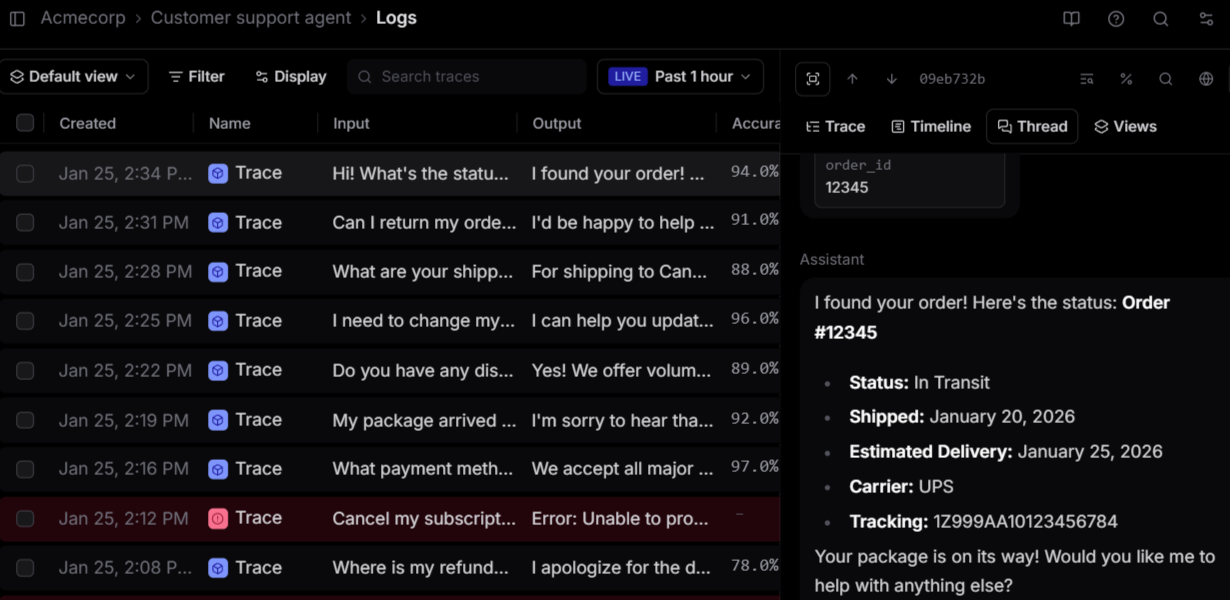
Best for: SaaS teams shipping AI features frequently that cannot afford regressions reaching users and need evaluation results to control every release.
Braintrust captures production traces across model calls, tool invocations, and application layers without forcing a specific orchestration framework. The AI gateway supports major providers with minimal setup, and SDKs cover common backend languages for teams that prefer direct instrumentation. Because traces are structured and searchable, teams can isolate failures quickly and understand how prompts behave under real production traffic.
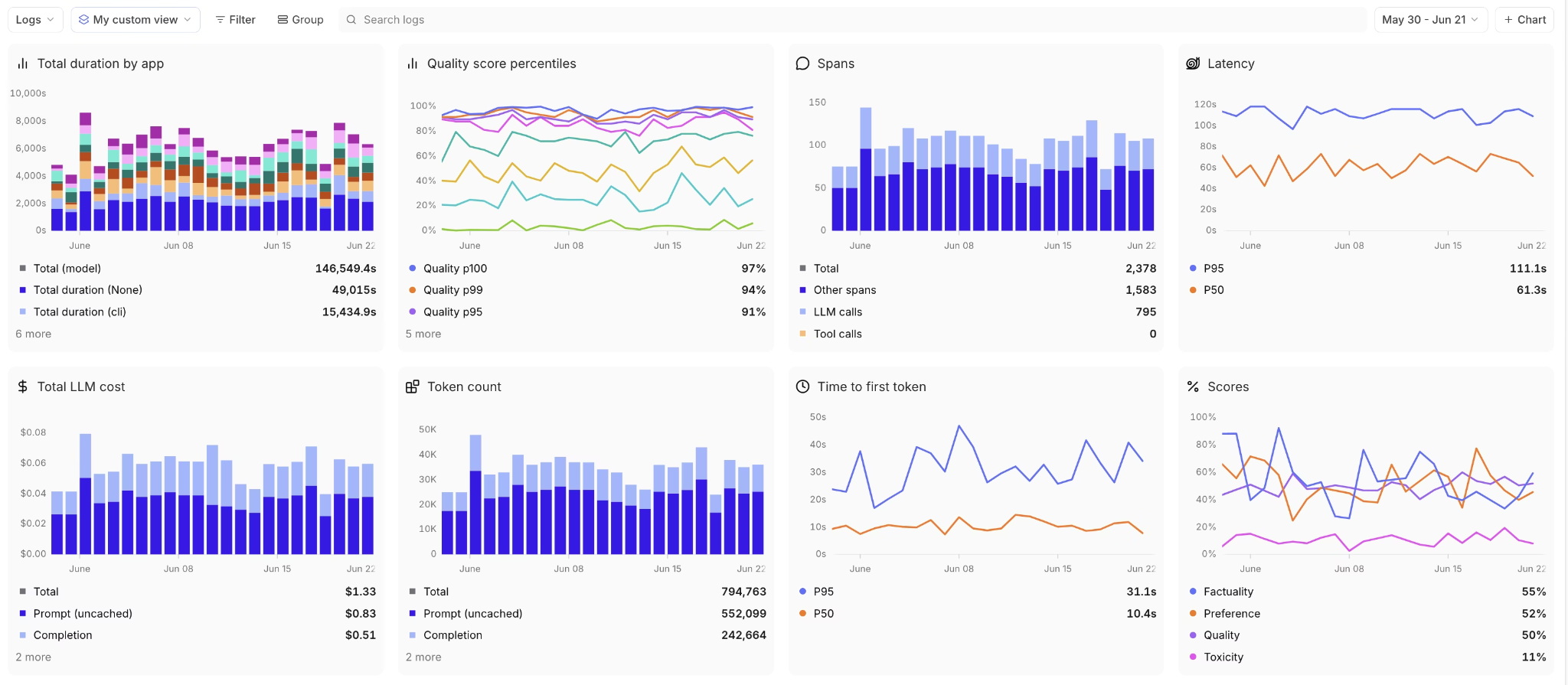
Evaluation in Braintrust directly influences release decisions, not just report scores. Teams can define custom metrics and use LLM-as-a-judge scorers to evaluate the quality of LLM output. Production traces can be directly converted into evaluation cases, turning live failures into permanent regression tests. Pull requests run evaluations automatically, and defined quality thresholds determine whether changes move forward.
Prompt testing happens inside a shared Playground where PMs and engineers compare outputs, annotate results, and test variations against real production data without exporting traces or rebuilding datasets. Loop, Braintrust's AI assistant, lets non-technical team members analyze logs, generate evaluation cases from live traffic, and create custom scorers using plain language. Shared access to traces and quality metrics keeps feedback tied to release decisions and removes back-and-forth between teams.
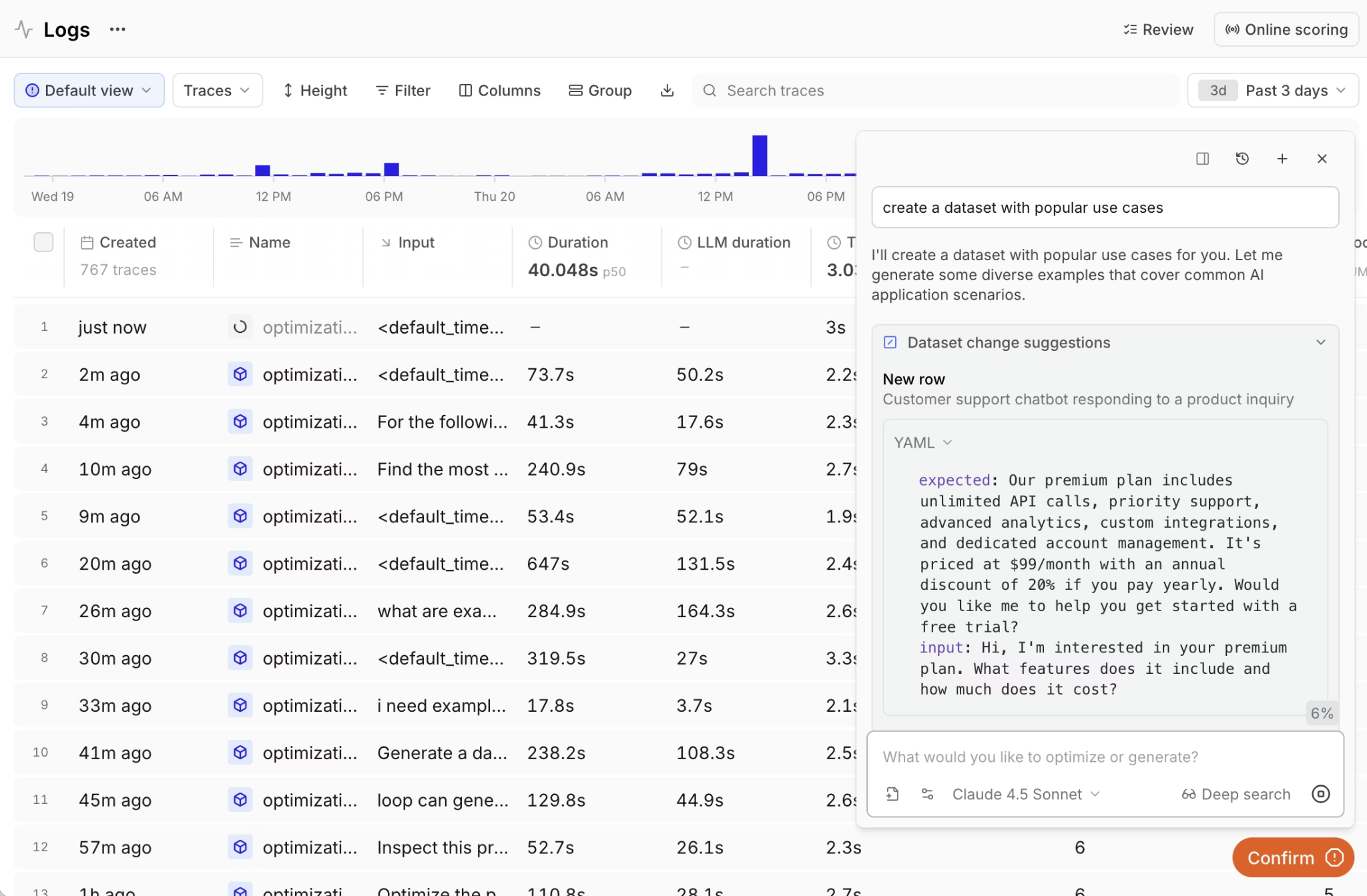
Unlike LangSmith, where evaluation results inform engineers but do not automatically block bad releases, Braintrust converts failures into regression tests and blocks regressions before users see them.
Pros
- CI/CD quality gates: GitHub Actions run evaluations on every pull request and block merges automatically when scores fall below defined thresholds, preventing regressions from reaching production.
- Production-to-eval pipeline: Any production trace converts into an evaluation dataset entry with one click, turning live failures into permanent regression tests instead of one-off fixes.
- PM and engineer collaboration: The Playground allows PMs and engineers to test prompt changes against real production data, compare outputs side by side, and align on release decisions in a shared workspace.
- Automated scorer generation: Loop AI generates scorers and datasets from production data, reducing the time required to define evaluation criteria for new features and edge cases.
- Framework-agnostic integrations: Support for OpenTelemetry, SDK-based instrumentation, and the AI gateway allows teams to use their existing architecture without adopting a specific orchestration framework.
- Unlimited users on the free tier: The free plan allows unlimited collaborators, making it easier to involve product, engineering, and leadership in quality reviews without scaling costs with headcount.
Cons
- Self-hosting is available only on the Enterprise tier
- Closed-source platform
Pricing
Free tier includes 1 GB of processed data, unlimited users, and 10K scores. Pro plan at $249/month with 5 GB of processed data and unlimited users. Enterprise plans are custom. See pricing details.
Why AI SaaS teams choose Braintrust over LangSmith
| Dimension | Braintrust | LangSmith | Winner |
|---|---|---|---|
| Framework support | Framework-agnostic; SDKs across multiple languages + OpenTelemetry | Also framework-agnostic + OpenTelemetry, but deepest zero-config integration is LangChain/LangGraph | Braintrust |
| CI/CD gating | Native GitHub Action with PR gating and automatic merge blocking | Eval results in dashboards only; no automated deploy prevention | Braintrust |
| Prod-to-eval pipeline | One-click trace-to-dataset conversion with automatic linkage | Manual correlation between production traces and test datasets | Braintrust |
| PM collaboration | PM-accessible Playground with annotation workflows and shareable experiment links | A prompt playground and annotation exist, but engineers control most of the workflow | Braintrust |
| Primary language | TypeScript-first with broad multi-language coverage, including Python | Python-first with JS SDK available | Tie |
| LangChain DX | Requires explicit SDK integration | Single environment variable enables full tracing, zero additional code | LangSmith |
| Free tier | 1 GB of processed data, unlimited users | 5,000 traces/month, one user | Braintrust |
| Paid pricing | Flat $249/month, 5 GB of processed data, any team size | $39/user/month means a 10-person team hits $390/month before trace volume | Braintrust |
Ready to close the eval-to-production loop? Start free with Braintrust.
2. Langfuse
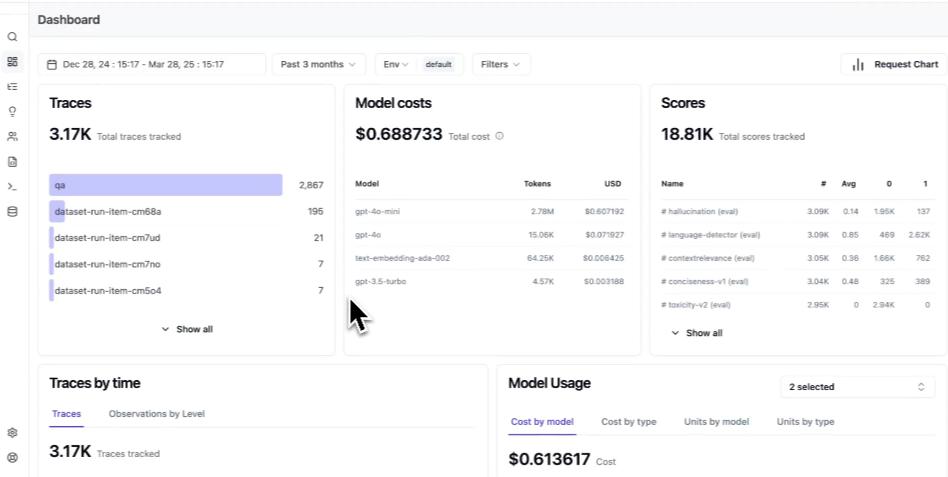
Best for: Teams that require self-hosting and have the engineering capacity to operate and maintain their own observability infrastructure.
Langfuse provides an open-source observability platform that teams can self-host for full control over data and infrastructure. Langfuse includes trace visualization, prompt versioning, and usage tracking. Teams that require direct access to raw trace data can query their observability layer using SQL without platform restrictions. A managed cloud deployment option is also available for teams that prefer not to operate their own infrastructure.
Pros
- Fully open-source and self-hostable with a managed cloud option
- Trace viewing, prompt versioning, and cost and latency tracking across providers
- OpenTelemetry support with broad SDK coverage
Cons
- Self-hosting requires PostgreSQL, ClickHouse, Redis, and Kubernetes for production workloads
- No CI/CD deployment blocking or automated quality gates in the shipping pipeline
- PM collaboration features are limited compared to platforms built for cross-functional workflows
Pricing
Free self-hosting and a free cloud plan with 50K units per month. Paid plan starts at $29 per month.
3. Agenta
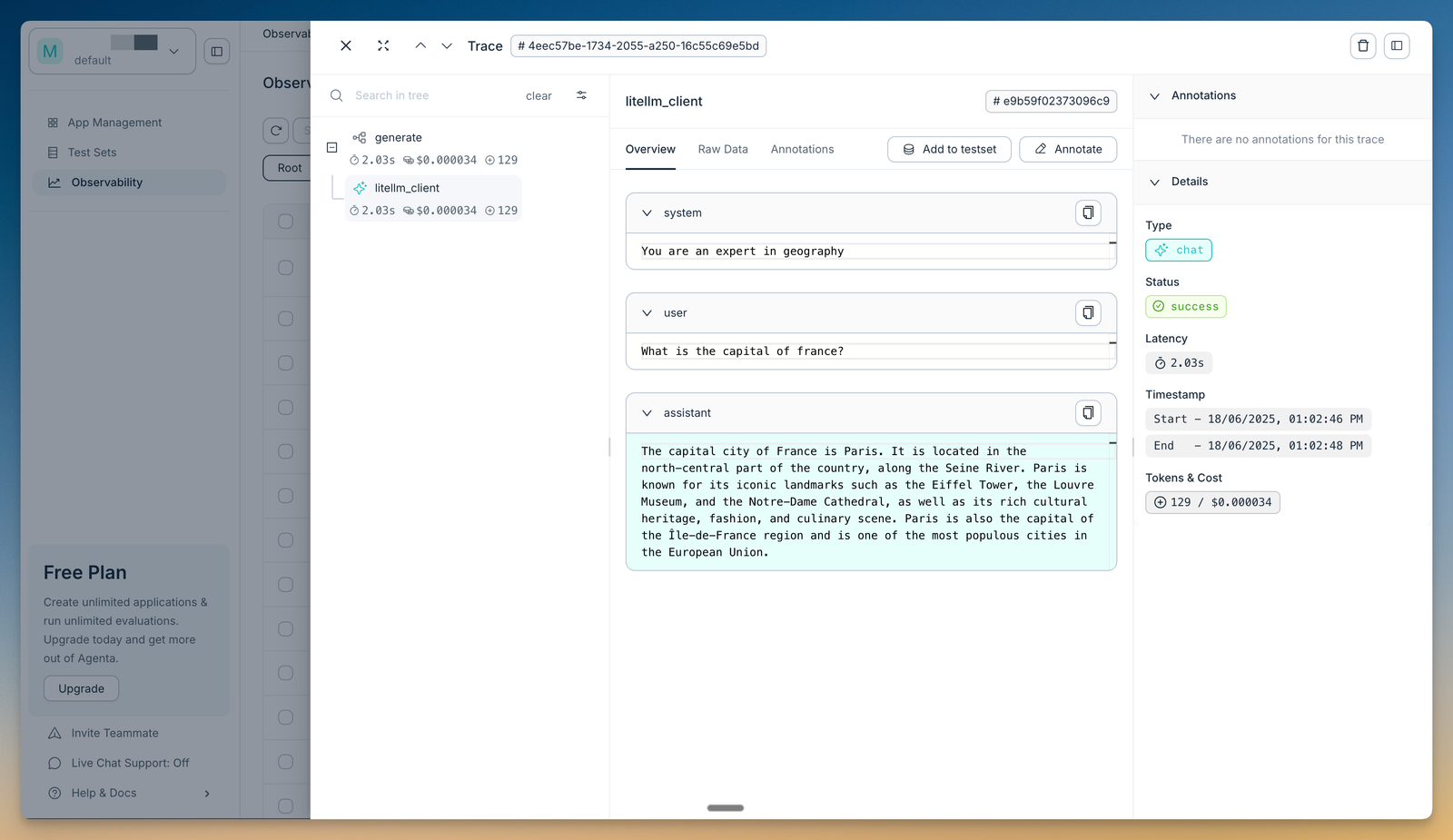
Best for: Teams that want an open-source, self-hostable platform that brings the prompt playground, prompt management, evals, and observability together in one place.
Agenta is an open-source LLMOps platform that combines a prompt playground, prompt management, LLM evaluation, and observability. The playground lets you compare prompts and models side by side, keep a complete version history, and deploy changes without writing code. Evaluation runs automatically with LLM-as-a-judge and custom evaluators, works across the full trace of an agent's steps, and supports human annotation. The observability layer traces every request so teams can pinpoint failures and annotate traces directly. Agenta integrates with LangChain, LlamaIndex, and OpenAI, and the functional features are MIT-licensed and self-hostable.
Pros
- Open-source and self-hostable, with enterprise features for team management, RBAC, and SOC2
- Prompt playground with side-by-side prompt and model comparison plus complete version history
- Automated evaluation with LLM-as-a-judge and custom evaluators, full-trace scoring, and human annotation
Cons
- No native CI/CD gating to block merges when evaluation scores regress
- The free tier caps usage at 2 seats and 5,000 traces per month
- Production traces do not convert into regression datasets automatically
Pricing
Hobby tier is free with 2 seats and 5,000 traces per month. Pro starts at $49/month, and Business at $399/month with RBAC and SOC2. Self-hosting the open-source core is free.
4. Galileo

Best for: Enterprise teams focused on AI safety and guardrails.
Galileo focuses on production-scale evaluation and guardrail scoring. Its Luna-2 small language models are designed for low-latency evaluation tasks without relying solely on large frontier LLM judges. Galileo includes built-in metrics for retrieval systems, agents, safety, and security use cases, and supports continuous scoring in live environments.
Pros
- 20+ built-in metrics covering RAG, agents, safety, and security evaluation
- Agentic evaluation with flow adherence, task completion, and conversation quality scoring
- Production guardrails powered by Luna-2 for ongoing monitoring
Cons
- Focuses on evaluation and guardrails rather than prompt iteration, playground UX, or version management
- No CI/CD deployment blocking or PR-level quality gating
- Tracing and observability coverage are narrower than full-loop platforms
Pricing
Free tier with 5,000 traces/month. Paid plan starts at $100/month. Custom enterprise pricing.
5. Fiddler AI
Best for: Regulated industries like finance, healthcare, and defense that need explainability, bias detection, and compliance monitoring alongside LLM observability.
Fiddler provides unified monitoring for traditional machine learning models and LLM applications within a single platform, including drift detection, bias analysis, and explainability features alongside generative AI monitoring. Fiddler's guardrail models support detection of hallucination, toxicity, PII leakage, and prompt injection for production workloads.
Pros
- Unified monitoring for traditional ML and LLM applications in a single dashboard
- Guardrails for hallucination, toxicity, PII leakage, and prompt injection
- Embedding drift detection for tracking distribution shifts in production
Cons
- The interface and workflow assumptions reflect Fiddler's ML monitoring heritage rather than a generative AI-first UX
- No CI/CD deployment blocking, as monitoring and alerting happen only after deployment
- No prompt management, playground, or version control is built into the platform
- SDK instrumentation is required for every service, with no zero-code proxy option
Pricing
Free guardrails plan with limited functionality. Custom pricing for full AI observability and enterprise features.
Best LangSmith alternatives compared (2026)
| Feature | Braintrust | Langfuse | Agenta | Galileo | Fiddler AI |
|---|---|---|---|---|---|
| PM usability | PM-accessible Playground with side-by-side comparison, annotation workflows, and shareable experiment links tied directly to release decisions | Basic annotation, engineering-oriented | Prompt playground with side-by-side comparison and human annotation, but not connected to release decisions or CI/CD | Evaluation-focused, no PM-facing UX | No playground or prompt management |
| Prompt/version workflow | Versioning, diffs, and environments with direct connection to eval results and deploy pipeline | Versioning and diffs available, but disconnected from the deploy pipeline | Prompt management with complete version history and code-free deploys, but no CI/CD gating | No prompt versioning | No prompt management |
| Traceability | Full agent traces, tool calls, and metadata across any framework via OTel or AI gateway, no code changes required for major providers | Requires instrumentation, no zero-code proxy option | Request-level tracing with trace annotation; integrates with LangChain and LlamaIndex | Guardrail-focused, narrower tracing | Requires SDK instrumentation, no zero-code proxy option |
| Evals depth | Offline + online evals, Autoevals, LLM-as-judge, human annotation, regression tests, and automated scorer generation from production data | Dataset evals and LLM-as-judge available, but no automated scorer generation or regression pipeline | LLM-as-a-judge, custom evaluators, full-trace scoring, and human annotation, but no automated regression from production traces | 20+ built-in metrics and Luna-2 scoring, but no prompt iteration or regression workflow | Monitoring-focused; no structured eval workflow |
| CI/CD integration | Native GitHub Action runs evals on every PR, posts results, and blocks merges on regressions | No | No | No | No |
| Integrations | OTel, Vercel AI SDK, zero-code tracing across major providers | Broad OTel and SDK support, but no zero-code proxy | LangChain, LlamaIndex, and OpenAI; model-agnostic | Partial | OTel-based but requires SDK instrumentation per service |
| Free tier | 1 GB data, 10K scores, unlimited users | 50K units/mo | 2 seats, 5K traces/mo | 5K traces/mo | Limited guardrails only |
| Deployment | SaaS default, self-host on Enterprise | Open-source, self-host, Cloud | Open-source, self-host, Cloud | SaaS | SaaS, VPC |
Choosing the right LangSmith alternative
Choose Braintrust if you need evaluation results to control release decisions, turn production failures into regression tests, and prevent regressions from reaching users.
Choose Langfuse if self-hosting is required and your team has the capacity to operate and maintain its own observability infrastructure.
Choose Agenta if you want an open-source, self-hostable platform that combines a prompt playground, prompt management, evals, and observability in one place.
Choose Galileo if continuous evaluation, scoring, and guardrails in live environments are the primary requirements.
Choose Fiddler AI if you operate in a regulated environment and require unified monitoring across traditional ML and LLM systems with compliance and governance controls.
Why Braintrust is the best LangSmith alternative
LangSmith helps teams understand how their LLM systems behave, while Braintrust changes how teams manage the quality of those systems as they move from development to production.
As LLM applications shift from early experimentation to frequent updates, teams need evaluation results that directly influence release decisions before prompt changes or model updates reach users, rather than relying on manual review after updates are made.
Braintrust turns evaluation results into a release requirement instead of a dashboard metric. Quality standards are enforced before deployment, providing teams with a consistent way to scale release velocity and team size without relying on individual judgment or last-minute review. Product and engineering work in the same environment, keeping feedback tied to release decisions and reducing the risk of user-facing issues caused by overlooked evaluation drops.
Companies such as Notion, Stripe, Vercel, Dropbox, and Zapier use Braintrust to protect user experience. Notion's AI team went from identifying and fixing 3 issues per day to 30 per day after building its evaluation workflow with Braintrust.
If you cannot afford regressions reaching users, start with Braintrust's free plan or schedule a demo.
LangSmith alternatives FAQs
Which is the best LangSmith alternative?
For most production teams, Braintrust is the strongest alternative because it ensures that evaluation results influence what reaches users. Instead of relying on dashboard review, Braintrust applies quality standards to release decisions and converts production issues into lasting safeguards. Braintrust also supports collaboration across product and engineering and offers a free tier suitable for teams scaling their evaluation practice.
Which LangSmith alternative works best for teams already using LangChain?
Teams committed to LangChain often consider Langfuse for its open-source flexibility and compatibility with LangChain-based applications. Braintrust also integrates with LangChain and adds structured release control, shared iteration, and production-level evaluation discipline. For teams that want LangChain compatibility and the full eval-driven shipping workflow on a single platform, Braintrust is the stronger long-term fit.
Is Braintrust better than LangSmith for automated evals?
For teams that need automated evaluations to influence release decisions, Braintrust provides stronger enforcement. Evaluation results are applied before changes reach production, reducing the risk of regressions going unnoticed. LangSmith provides structured evaluation and visibility into model performance, but acting on those results requires manual review. Braintrust is better suited for teams that want evaluation to gate every release automatically.