Contributed by Jess Wang on 2026-06-22
In this cookbook, you’ll take 1,781 real agent-eval traces published on Hugging Face (the Exgentic agent-llm-traces dataset), import them into Braintrust, score them with an LLM judge, and use Topics and SQL to find the patterns. This cookbook covers setting up a pipeline, but you can read our deeper analysis of those traces in our blog post.
By the end, you’ll learn how to:
- Stream a Hugging Face trace dataset into Braintrust as a span tree per session.
- Score each session with an LLM-as-a-judge and write the scores back onto the same spans.
- Use Topics to cluster failure modes without manual tagging.
- Slice success rate by benchmark, harness, and model with a single query.
- Turn a failure cluster into a targeted eval dataset.
What you’re working with
The dataset is 1,781 agent runs across six benchmarks (SWE-bench, AppWorld, BrowseComp+, and three τ²-bench customer-service suites), six models, and five harnesses. Each run records the task, the agent’s full conversation (every LLM call), and metadata like model, benchmark, harness, and token count. There are roughly 49,000 LLM calls in total, and importantly, the dataset ships with no ground-truth labels, meaning that everyscores and expected field is null. You’ll build your own success measure in the scoring step.
Getting started
You’ll need:- A Braintrust account with an API key.
- Python 3.10+ with the
braintrust,datasets,requests, andpython-dotenvpackages, plus thebtCLI (installed with thebraintrustpackage) for the logs push.
Hugging Face topics. The import script resolves the project by name, so it has to exist first.
Importing the traces
The importer lives inhf_bt_cookbook/import_logs.py (read the full file there). It’s a worked example you edit and re-run. The entire mapping lives in an EDIT ME block at the top of the file, where you name the Hugging Face repo and say which columns hold the session ID, the trace, the metadata, and any scores.
datasets.load_dataset(HF_REPO, streaming=True). For each session row, it builds a span tree:
content, calls in tool_calls):
--push to upload:
--push.
Once the push finishes, every run is a row in the Braintrust Logs view that you can sort, filter, and slice on any metadata field.
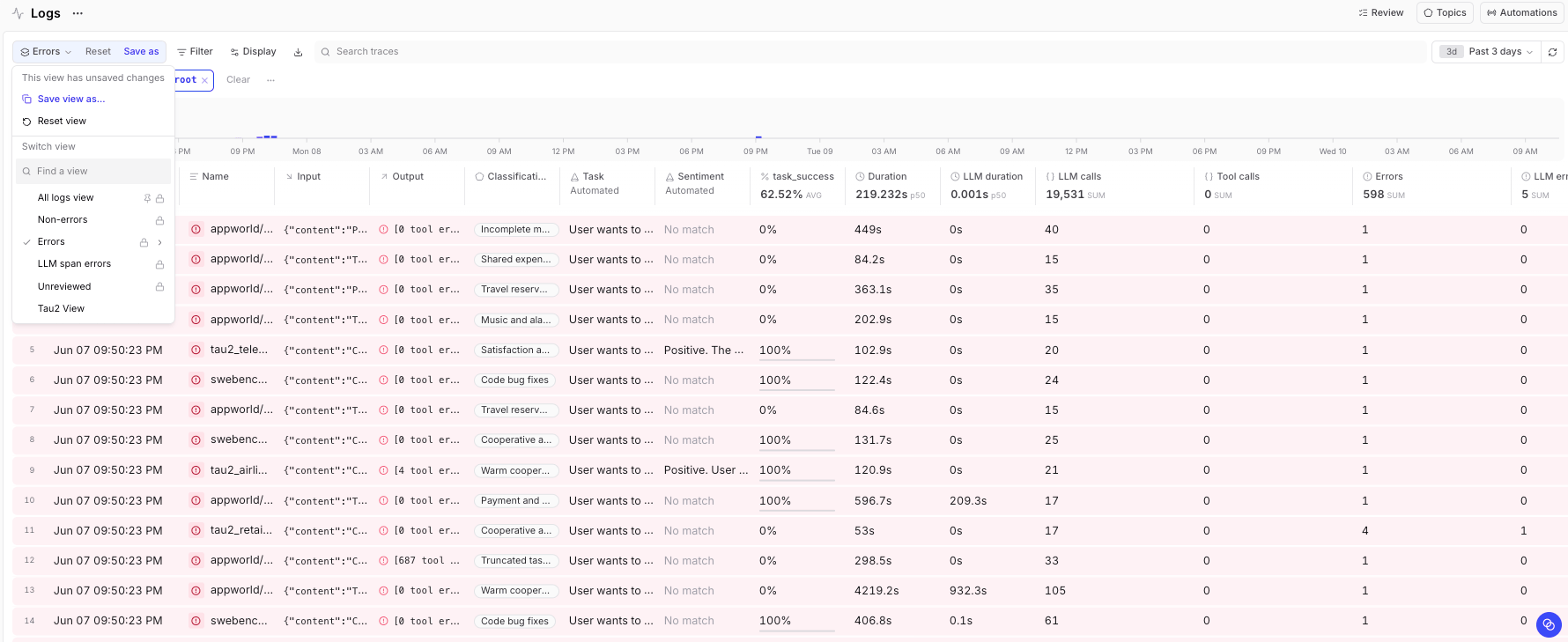
Scoring with an LLM judge
The traces record what each agent did, but not whether it succeeded. To build a success measure, we want to run an LLM-as-a-judge over each session to determine whether the task completed successfully. To do this, we feed the LLM-as-a-judge the task, the agent’s final conversation, and a benchmark-specific rubric, then ask for a binary verdict. The judge call goes through the Braintrust gateway, an OpenAI-compatible endpoint that fronts every major model provider (OpenAI, Anthropic, Google, and more) behind one URL. So you can point the judge at any model just by changing themodel field, and you authenticate with the same BRAINTRUST_API_KEY you already set, with no separate provider key to manage:
SCORE_COLS at it, and re-run the importer. The matching IDs upsert the score onto the spans that are already there.
scores.task_success you can filter and aggregate on. Filter scores.task_success IS NOT NULL to work only with scored rows.
Finding failure modes with Topics
With the sessions scored, Topics clusters them automatically, no manual tagging required. The Issues facet groups agent misbehaviors into named classes, and clusters likeFalse success confirmation, Incomplete multi-step execution, and Truncated task completion map directly onto the failure modes you would otherwise have to discover by hand.
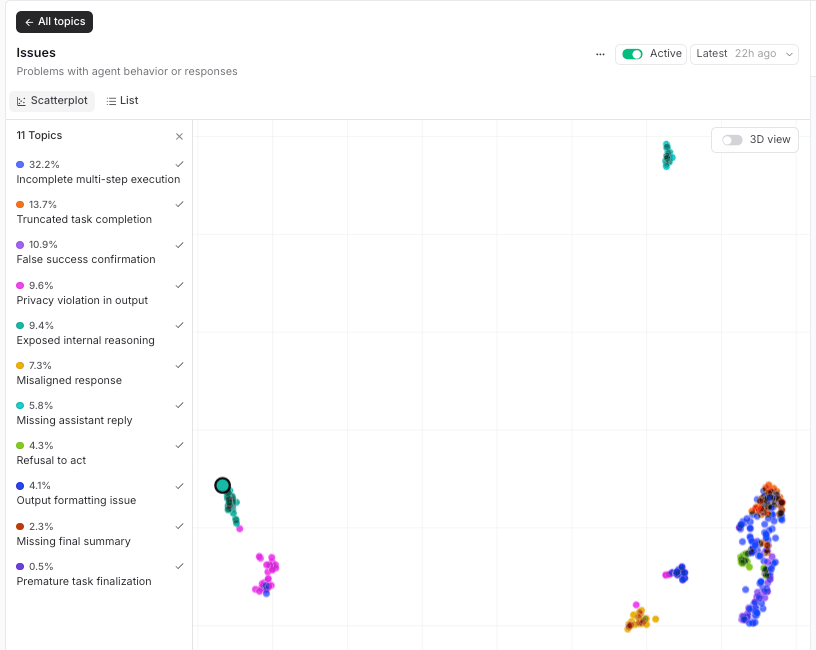
False success confirmation cluster, without us labeling a single trace. The failure taxonomy we would otherwise have built manually fell out of the clustering automatically, which is why it’s worth reaching for Topics before you write a single rule.
Slicing the results
The reason to put traces in Braintrust is to ask structured questions across all of them at once. Every span carries queryable metadata, so you can group by benchmark, harness, and model in a single query: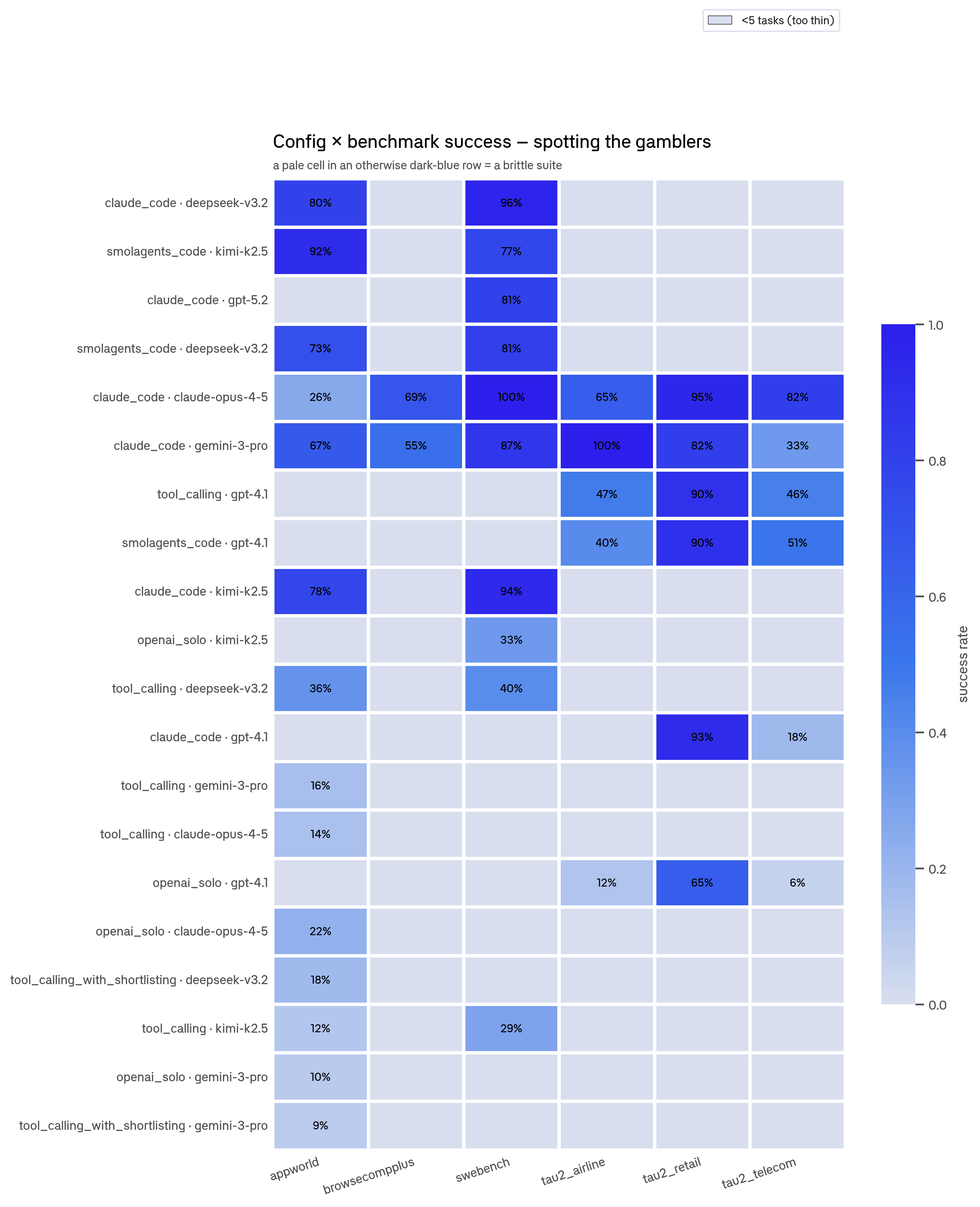
Building a targeted eval dataset
Analyzing traces tells you where the agent fails. To check whether a fix actually helps, you need a gradable dataset and an experiment. The cookbook’s second script,hf_bt_cookbook/import_dataset.py, turns Hugging Face rows into a Braintrust Dataset of {input, expected, metadata} records. You rewrite one function, to_record, which is the entire mapping:
Next steps
You’ve imported real agent traces, scored them, clustered their failures, and sliced success by configuration. From here you can:- Read the full analysis of this dataset for what the numbers actually showed.
- Point
import_logs.pyat your own trace dataset by editing theEDIT MEblock. - Run experiments against the configurations your analysis flagged.
- Explore Topics further to surface patterns your evals don’t yet test for.